
機器學習-->整合學習-->GBDT,RandomForest
本篇博文總仔細總結GBDT,RandomForest原理。
Boosting(提升)
提升是一個機器學習技術,可以用於迴歸和分類問 題,它每一步產生一個弱預測模型(如決策樹),並加權累加到總模型中;如果每一步的弱預測模型生 成都是依據損失函式的梯度方向,則稱之為梯度提升(Gradient boosting)。
梯度提升演算法首先給定一個目標損失函式,它的定義域是所有可行的弱函式集合(基函式),即自變數就是每次加進來的基函式;提升演算法 通過迭代的選擇一個負梯度方向上的基函式來逐漸逼近區域性極小值。(沿著梯度下降方向建立基函式)這種在函式域的梯度提升觀點對機器學習的很多領域有深刻影響。
提升的理論意義:如果一個問題存在弱分類器,則 可以通過提升的辦法得到強分類器。
提升演算法
給定輸入向量x和輸出變數y組成的若干訓練樣本(x1,y1),(x2,y2),…,(xn,yn),目標是找到近似函式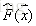
L(y,F(x))的典型定義為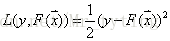
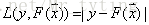
假定最優函式為
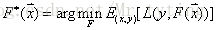
假定F(X)是一族基函式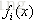
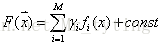
梯度提升方法尋找最優解F(x),使得損失函 數在訓練集上的期望最小。方法如下:
首先,給定常函式
:
以貪心的思想擴充套件到
:
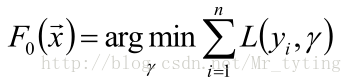
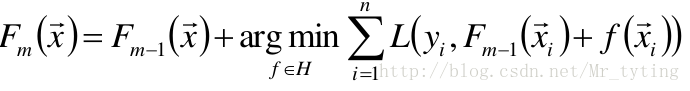
梯度近似
使用梯度下降法近似計算
將樣本代入基函式f得到
,從而L退化為向量
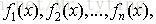
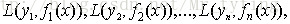
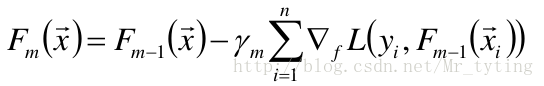
提升演算法的一般步驟(GBDT):
- 給定初始模型為常數
對於m=1到M:
① 計算偽殘差
注意:是對函式F求偏導,不是對x求導。
②使用資料
計算擬合殘差的基函式
③給定一個步長
④更新模型
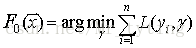
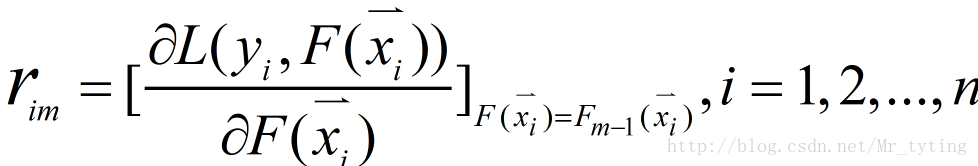
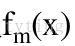
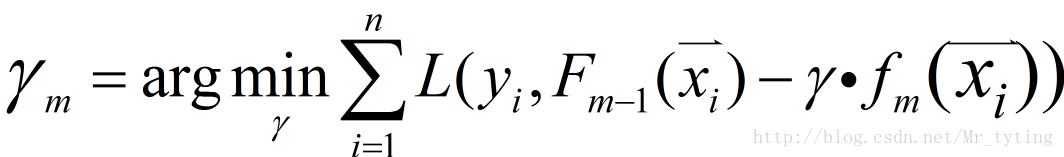
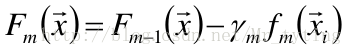
GBDT
梯度提升的典型基函式即決策樹(尤其是CART) 。
在第m步的梯度提升是根據偽殘差資料計算決策樹 tm(x)。令樹tm(x)的葉節點數目 為J,即樹tm(x)將輸入空間劃分為J個不相交區域 R1m,R2m,…,RJm,並且決策樹tm(x)可以在每個區域中給出某個型別的確定 性預測。使用指示記號I(x),對於輸入x, tm(x) 為:
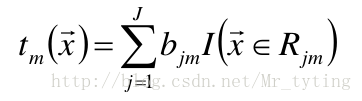
其中,bjm是樣本x在區域Rjm的預測值。
使用線性搜尋計算學習率,最小化損失函式:
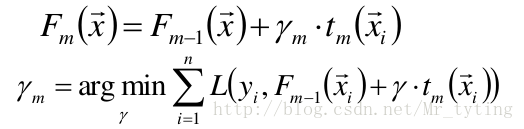
進一步:對樹的每個區域分別計算步長,從 而係數bjm被合併到步長中,從而:
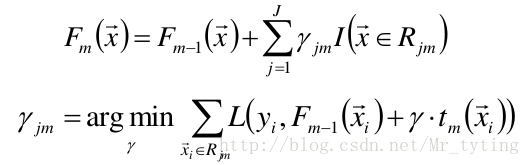
引數設定和正則化
對訓練集擬合過高會降低模型的泛化能力,需要使 用正則化技術來降低過擬合。
- 對複雜模型增加懲罰項,如:模型複雜度正比於葉結點 數目或者葉結點預測值的平方和等。
- 用於決策樹剪枝。
葉結點數目控制了樹的層數,一般選擇4≤J≤8。
葉結點包含的最少樣本數目
- 防止出現過小的葉結點,降低預測方差
梯度提升迭代次數M:
- 增加M可降低訓練集的損失值,但有過擬合風險
- 交叉驗證
衰減因子、降取樣
衰減Shrinkage
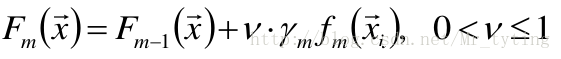
- 稱ν為學習率
- ν=1即為原始模型;推薦選擇v<0.1的小學習率。過小的 學習率會造成計算次數增多。
隨機梯度提升Stochastic gradient boosting
- 每次迭代都對偽殘差樣本採用無放回的降取樣,用部分 樣本訓練基函式的引數。令訓練樣本數佔所有偽殘差樣本的比例為f;f=1即為原始模型:推薦0.5≤f≤0.8。
- 較小的f能夠增強隨機性,防止過擬合,並且收斂的快。
- 降取樣的額外好處是能夠使用剩餘樣本做模型驗證。
GBDT總結
函式估計本來被認為是在函式空間而非引數空間的 數值優化問題,而階段性的加性擴充套件和梯度下降手 段將函式估計轉換成引數估計。
損失函式是最小平方誤差、絕對值誤差等,則為回 歸問題;而誤差函式換成多類別Logistic似然函式, 則成為分類問題。
Gradient Boost與傳統的Adaboost的區別是,Gradient Boost會定義一個loassFunction,每一次的計算是為了減少上一次的loss,而為了消除loss,我們可以在loss減少的梯度(Gradient)方向上建立一個新的模型。所以說,在Gradient Boost中,每個新的模型的建立是為了使得之前模型的loss往梯度方向減少,與傳統Boost對正確、錯誤的樣本進行加權有著很大的區別。
RandomForest
RandomForest建立過程
- 從樣本集中用Bootstrap取樣選出n個樣本;(Bootstrap即有放回的隨機取樣)
- 從所有屬性中隨機選擇k個屬性,選擇最佳分割 屬性作為節點建立CART決策樹;
- 重複以上兩步m次,即建立了m棵CART決策樹;
這m個CART形成隨機森林,通過投票表決結果, 決定資料屬於哪一類。
隨機森林是一個最近比較火的演算法,它有很多的優點:
①在資料集上表現良好
②在當前的很多資料集上,相對其他演算法有著很大的優勢
③它能夠處理很高維度(feature很多)的資料,並且不用做特徵選擇
④在訓練完後,它能夠給出哪些feature比較重要
⑤在建立隨機森林的時候,對generlization error使用的是無偏估計
⑥訓練速度快
⑦在訓練過程中,能夠檢測到feature間的互相影響
⑧容易做成並行化方法
⑨實現比較簡單
隨機森林顧名思義,是用隨機的方式建立一個森林,森林裡面有很多的決策樹組成,隨機森林的每一棵決策樹之間是沒有關聯的。在得到森林之後,當有一個新的輸入樣本進入的時候,就讓森林中的每一棵決策樹分別進行一下判斷,看看這個樣本應該屬於哪一類(對於分類演算法),然後看看哪一類被選擇最多,就預測這個樣本為那一類。
在建立每一棵決策樹的過程中,有兩點需要注意 - 取樣與完全分裂。首先是兩個隨機取樣的過程,random forest對輸入的資料要進行行(樣例)、列(特徵)的取樣。對於行取樣,採用有放回的方式,也就是在取樣得到的樣本集合中,可能有重複的樣本。假設輸入樣本為N個,那麼取樣的樣本也為N個。這樣使得在訓練的時候,每一棵樹的輸入樣本都不是全部的樣本,使得相對不容易出現over-fitting。然後進行列取樣,從M個feature中,選擇m個(m << M)。簡而言之:就是可放回抽取樣例,隨機抽取部分特徵。之後就是對取樣之後的資料使用完全分裂的方式建立出決策樹,這樣決策樹的某一個葉子節點要麼是無法繼續分裂的,要麼裡面的所有樣本的都是指向的同一個分類。一般很多的決策樹演算法都一個重要的步驟 - 剪枝,但是這裡不這樣幹,由於之前的兩個隨機取樣的過程保證了隨機性,所以就算不剪枝,也不會出現over-fitting。
OOB資料
上面說到了,隨機森林之“隨機”
- 從原始樣本集中隨機有放回的抽樣
- 從原始樣本特徵集中隨機有放回的抽取一些特徵出來
這裡我們假設原始樣本集中有n個樣本,隨機的有放回的從這n個樣本集中抽取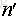
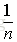
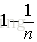
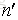

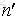
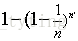

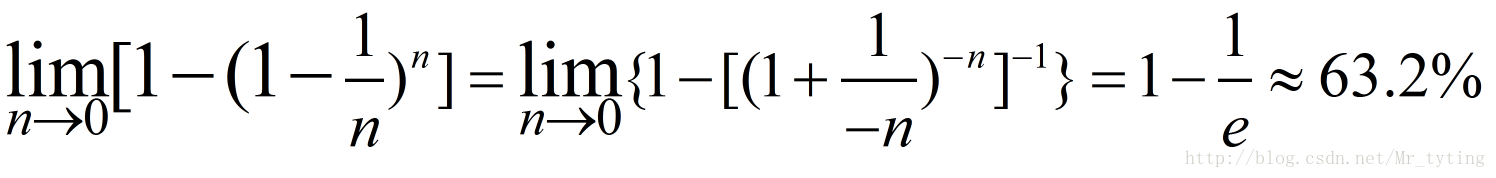
由此可得,在隨機森林中,每次生成一顆決策樹時,都會隨機抽取63.2%的樣本參與這棵樹的生成,約有36.8%的樣本沒有參與到本次這棵樹生成。我們把參與的63.2%的樣本資料稱為在bag中的資料,剩餘的36.8%的樣本資料稱為out of Bag(OOB),即袋外資料,這些袋外資料可以取代測試集用於誤差估計。每次生成一棵樹時都會有袋外資料,就用袋外資料測試當前生成的這棵樹的效能如何。
上面都是假定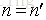
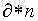
Breiman以經驗性的例項形式證明袋外資料誤差估計與同訓練集一樣大小的測試集精度相同。
clf = RandomForestClassifier(n_estimators=200, criterion='entropy', max_depth=3,oob_score=True) ##oob_score=True利用袋外資料驗證模型效能
clf.fit(x, y.ravel())
print clf.oob_score_使用RF建立計算樣本間相似度
原理:若兩樣本同時出現在相同葉結點的次數越多,則二者越相似。
演算法過程:
記樣本個數為N,初始化N×N的零矩陣S,S[i,j]表 示樣本i和樣本j的相似度。
對於m顆決策樹形成的隨機森林,遍歷所有決策樹 的所有葉子結點:
記該葉結點包含的樣本為sample[1,2,…,k],則S[i][j]累加1。
樣本i,j∈sample[1,2,…k]
樣本i,j出現在相同葉結點的次數增加1次。遍歷結束,則S為樣本間相似度矩陣。
使用隨機森林計算特徵重要度
計算正例經過的結點,使用經過結點的數目、 經過結點的gini係數和等指標。或者,隨機替換 一列資料,重新建立決策樹,計算新模型的正 確率變化,從而考慮這一列特徵的重要性。
總結
按這種演算法得到的隨機森林中的每一棵都是很弱的,但是大家組合起來就很厲害了。我覺得可以這樣比喻隨機森林演算法:每一棵決策樹就是一個精通於某一個窄領域的專家(因為我們從M個feature中選擇m讓每一棵決策樹進行學習),這樣在隨機森林中就有了很多個精通不同領域的專家,對一個新的問題(新的輸入資料),可以用不同的角度去看待它,最終由各個專家,投票得到結果。