
搞懂分布式技術10:LVS實現負載均衡的原理與實踐
淺析負載均衡及LVS實現
原創: fireflyc 寫程序的康德 2017-09-19
負載均衡
負載均衡(Load Balance,縮寫LB)是一種網絡技術,它在多個備選資源中做資源分配,以達到選擇最優。這裏有三個關鍵字:
-
網絡技術,LB要解決的問題本質上是網絡的問題,所以它實際上就是通過修改數據包中MAC地址、IP地址字段來實現數據包的“中轉”;
-
資源,這裏的資源不僅僅是計算機也可以是交換機、存儲設備等;
-
最優,它則是針對業務而言最優,所以一般負載均衡有很多算法;輪詢、加權輪詢、最小負載等;
LB是網絡技術所以業內就參考OSI模型用四層負載均衡、七層負載均衡進行分類。四層負載均衡工作在OSI的四層,這一層主要是TCP、UDP、SCTP協議,這種類型的負載均衡器不管數據包是什麽,只是通過修改IP頭部或者以太網頭部的地址實現負載均衡。七層負載均衡工作在OSI的七層,這一層主要是HTTP、Mysql等協議,這種負載均衡一般會把數據包內容解析出來後通過一定算法找到合適的服務器
實現LB的問題
無論哪種負載均衡都可以抽象為下面的圖形:
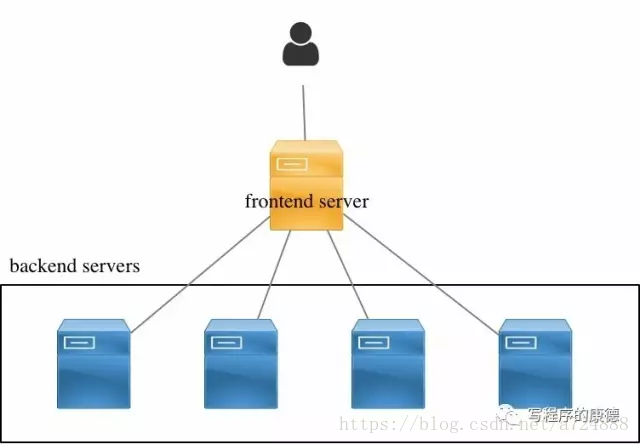
任何負載均衡都要解決三個問題:
-
修改數據包,使得數據包可以發送到backend servers;
-
frontend server要維護一個算法,可以選出最優的backend server
-
frontend server要維護一張表記錄Client和backend servers的關系(比如TCP請求是一系列數據包,所以在TCP關閉所有的數據包都應該發送到同一個backend server)
以Nginx為例,forntend server收到HTTP數據包後會通過負載均衡算法選擇出一臺backend server;然後從本地重新構造一個HTTP請求發送給backend server,收到backend server請求後再次重新封裝,以自己的身份返回給客戶端。在這個過程中forntend server的Nginx是工作在用戶空間的它代替Client訪問backend server。
LVS的實現
LVS( Linux Virtual Server)是國產開源中非常非常非常優秀的項目,作者是章文嵩博士(關於章博的簡歷各位自行搜索)。它是一款四層負載均衡軟件,在它的實現中forntend server稱為director;backend server稱為real server,它支持UDP、TCP、SCTP、IPSec( AH 、ESP兩種數據包 )四種傳輸層協議的負載。
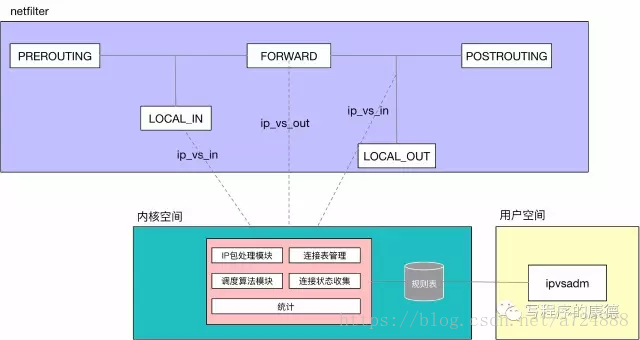
LVS以內核模塊的形式加載到內核空間,通過netfilter定義的hook來實現數據包的控制。 它用到了三個Hook(以Linux 4.8.15為例)主要“掛在”:local_in、inet_forward、local_out;所有發送給本機的數據包都會經過local_int,所有非本機的數據包都會經過forward,所有從本機發出的數據包都會經過local_out。
LVS由兩部分組成(很像iptables),用戶空間提供了一個ipvsadm的命令行工具,通過它定義負載均衡的“規則”;內核模塊是系統的主要模塊它包括:
-
IP包處理模塊,用於截取/改寫IP報文;
-
連接表管理,用於記錄當前連接的Hash表;
-
調度算法模塊,提供了八種負載均衡算法——輪詢、加權輪詢、最少鏈接、加權最少鏈接、局部性最少鏈接、帶復制的局部性最少鏈接、目標地址哈希、源地址哈希;
-
連接狀態收集,回收已經過時的連接;
-
統計,IPVS的統計信息;
LVS實戰
LVS術語定義:
-
DS:Director Server,前端負載均衡器節點(後文用Director稱呼);
-
RS:Real Server,後端真實服務器;
-
VIP:用戶請求的目標的IP地址,一般是公網IP地址;
-
DIP:Director Server IP,Director和Real Server通訊的內網IP地址;
-
RIP:Real Server IP,Director和Real Server通訊的內網IP地址;
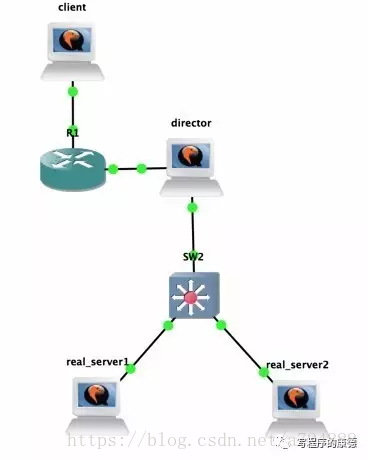
很多文章都羅列了一大堆LVS三種模式之間的區別,我最討厭的就是簡單的羅列——沒有什麽邏輯性很難記憶。其實LVS中三種模式只有一個區別——誰來返回數據到客戶端。在LB架構中客戶端請求一定是先到達forntend server(LVS中稱為Director),那麽返回數據包則不一定經過Director。
-
NAT模式中,RS返回數據包是返回給Director,Director再返回給客戶端;
-
DR(Direct Routing)模式中,RS返回數據是直接返回給客戶端(通過額外的路由);Director通過修改請求中目標地址MAC為選定的RS實現數據轉發,這就要求Diretor和Real Server必須在同一個廣播域內(關於廣播域請看《程序員學網絡系列》)。
-
TUN(IP Tunneling)模式中,RS返回的數據也是直接返回給客戶端,這種模式通過Overlay協議(把一個IP數據包封裝到另一個數據包內部叫Overlay)避免了DR的限制。
以上就是LVS三種模式真正的區別,是不是清晰多了?^_^
NAT模式
NAT(Network Address Translation)模式最簡單,real_server只配置一個內網IP地址(RIP),網關指向director;director配置2個IP地址分別是提供外部服務的VIP和用於內部通訊的DIP。
-
配置IP地址
VIP:10.10.10.10,DIP:192.168.122.100 RS1-DIP:192.168.122.101 RS2-DIP:192.168.122.102
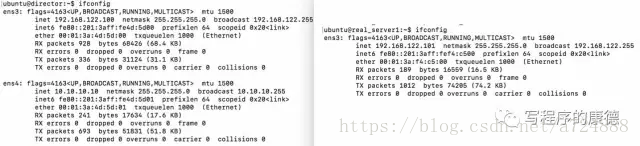
註意:Director配置了雙網卡,默認路由指向10.10.10.1。即——VIP所在的網卡設置網關,DIP所在的網卡不要設置網關。
-
配置director
Linux默認不會“轉發”數據包,通過echo 1 > /proc/sys/net/ipv4/ip_forward開啟forward功能。開啟forward後Linux表現的就像一個路由器,它會根據本機的路由表轉發數據包。
echo 1 > /proc/sys/net/ipv4/ip_forward #開啟forward功能
ipvsadm -A -t 10.10.10.10:80 -s rr # 添加LVS集群,DR 負載均衡算法為輪詢(rr)
ipvsadm -a -t 10.10.10.10:80 -r 192.168.122.101 -m -w 1 RS1 # 添加LVS集群主機(10.10.10.10:80),LVS調度模式為NAT(-m)及RS權重為1
ipvsadm -a -t 10.10.10.10:80 -r 192.168.122.102 -m -w 1 # RS2 同上
-
驗證
通過client訪問10.10.10.10的HTTP服務

NAT模式原理解析
-
client發送數據包,被路由到director服務器上;
-
director的netfilter local_in hook被觸發,lvs模塊收到該請求
-
lvs查詢規則庫(ipvsadm生成的規則),發現10.10.10.10:80端口被定義為NAT模式,執行輪詢算法
-
IP包處理模塊修改數據包,把目標IP地址修改為192.168.122.101,從DIP的所在網卡發送出去(所以源MAC是DIP網卡的MAC)。此時的數據包是:源MAC地址變成了00:01:3a:4d:5d:00(DIP網卡的MAC地址)源IP地址是172.10.10.10(client的IP地址),目標MAC和目標IP地址是RS1地址。通過在RS1上抓包驗證這一點
註意,Linux不會“校驗”源IP地址是否是本機IP地址所以即便172.10.10.10不在DIP上數據包也是可以被發送的,此時的行為相當於“路由”(想一下“網關”如何給你發送某個公網返回的數據包)。
-
RS1收到請求目標MAC和IP都是本機,所以直接交給Nginx處理
-
Nginx的返回數據包交給Linux協議棧,系統發現目標地址是172.10.10.10和自己不在同一個網段,則把數據包交給網關——192.168.122.100(director)。這就是Real Server必須把網關指向Director Server的原因
-
director上的lvs的local_out的hook被觸發,發現是返回數據包是:源MAC地址和IP地址是VIP網卡的MAC地址
這種模式雖然叫NAT模式,其實和NAT關系並不大,只是借用NAT的概念而已(發送到RS的源IP地址是客戶端的IP地址而不是DIP)。
DR模式
DR(Direct Route,直接路由)和NAT模式最大的區別是RS返回數據包不經過Director而是直接返回給用戶。用戶到達Director後,LVS會修改用戶數據包中目標MAC地址為Real Server然後從DIP所在網卡轉發出去,RS的返回數據包直接從單獨的鏈路(拓撲圖中是SW2<->R1)返回給用戶。
所以DR模式中要求
-
Director和RS必須在同一個廣播域中,也就是二層可達(實驗的拓撲中是通過SW2實現的) ,因為Director要修改目標MAC地址所以數據包只能在廣播域內轉發;
-
RS必須可以路由到用戶,也就是三層可達(實驗的拓撲中Director和Real server共享同一個路由),因為Real Server的返回數據包是直接返回給用戶的不經過Director;
-
配置IP
VIP:10.10.10.10,DIP:192.168.122.100RS1-DIP:192.168.122.101RS2-DIP:192.168.122.102
-
配置Real Server
#綁定VIP到本機的環回口
ifconfig lo:0 10.10.10.10 netmask 255.255.255.255 broadcast 10.10.10.10 up
#禁用ARP響應
echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore
echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce
RS是直接返回數據給用戶,所以必須綁定VIP地址;因為Director和Real Server都綁定了VIP所以RS必須禁用ARP信息,否則可能導致用戶請求不是發送給Director而是直接到RS,這和LVS的期望是不相符的。。不同於NAT,在DR模式下RS的網關是指向默認網關的也就是能“返回”數據到客戶端的網關(試驗中R1充當默認網關)。
-
配置Director
ipvsadm -A -t 10.10.10.10:80 -s rr # 添加LVS集群,負載均衡算法為輪詢(rr)
ipvsadm -a -t 10.10.10.10:80 -r 192.168.122.101 -g -w 1 # 添加LVS集群主機(10.10.10.10:80),VS調度模式為DR(-g)及RS權重為1
ipvsadm -a -t 10.10.10.10:80 -r 192.168.122.102 -g -w 1 # 同上
-
驗證
通過client訪問10.10.10.10的HTTP服務
DR模式原理解析
-
client發送數據包,被路由到director服務器上;
-
director的netfilter local_in hook被觸發,lvs模塊收到該請求
-
lvs查詢規則庫(ipvsadm生成的規則),發現10.10.10.10:80端口被定義為DR模式,執行輪詢算法
-
IP包處理模塊修改數據包,把目標MAC修改為選中的RS的MAC地址,從DIP的所在網卡發送出去(所以源MAC是DIP網卡的MAC)。此時的數據包是:源MAC地址變成了00:01:3a:4d:5d:00(DIP網卡的MAC地址)源IP地址是172.10.10.10(client的IP地址),目標MAC是00:01:3a:f4:c5:00(RS的MAC)目標IP地址10.10.10.10(VIP)。通過在RS1上抓包驗證這一點
-
RS1收到請求目標MAC和IP都是本機(VIP配置在本機的環回口),所以直接交給Nginx處理
-
Nginx的返回數據包交給Linux協議棧,系統發現目標地址是172.10.10.10和自己不在同一個網段,則把數據包交給網關——192.168.122.1。在我們的試驗中R1是網關,它是可以直接返回數據給客戶端的,所以數據被成功返回到客戶端。
註意:在操作系統中(無論是Linux或者Windows)返回數據的時候是根據IP地址返回的而不是MAC地址,RS收到數據包MAC地址是Director的而IP地址則是客戶端的RS如果按MAC地址返回那麽數據包就發送到Director了,很顯然是不正確的。而LVS的DR模式正是利用了這一點。
TUN模式
TUN(IP Tunneling,IP通道)是對DR模式的優化。和DR一樣,請求數據包經過Director到Real Server返回數據包則是Real Server直接返回客戶端。區別是:DR模式要求Director和Real Server在同一個廣播域(通過修改目標MAC地址實現數據包轉發)而TUN模式則是通過Overlay協議。Overlay協議就是指把一個IP數據包封裝在另一個數據包裏面,LVS裏面的Overlay協議屬於比較原始的實現叫IP-in-IP,目前常見的Overlay協議包括:VxLAN、GRE、STT之類的。TUN模式要求
-
Director和Real Server必須三層可達,拓撲圖中故意加上一個R2用於分割兩個廣播域;
-
Real Server必須可以路由到用戶,也就是三層可達(實驗的拓撲中Director和Real server共享同一個路由),因為RS的返回數據包是直接返回給用戶的不經過Director;
-
因為采用Overlay協議,Real Server的MTU值必須設置為1480(1500-20)——即實際上能發送的數據要加上外層IP頭部
TUN模式和DR模式沒有本質區別(配置是一摸一樣的,只是網絡要求不一樣),兩者都不是特別實用所以本文就不展開介紹了。
總結
LVS的基本原理是利用Linux的netfilter改變數據包的流向以此實現負載均衡。基於性能考慮LVS提供了二種模式,請求和返回數據包都經過Director的NAT模式;請求經過Director返回數據包由Real Server獨立返回的是DR和TUN模式(DR和TUN的區別是網絡二層可達還是三層可達)。DR和TUN理論上可能性能更高一些,但是這種假設的前提是——性能是出現在數據包轉發,而以目前軟硬件的架構而言數據轉發已經不成問題了。原因有兩點:首先Linux引入的NAPI可以平衡網卡中斷模式和Polling的性能問題,所以內核本身的轉發能力已經不是1998(LVS設計的時間)的情況,一般而言千兆的網絡轉發是不成問題的;其次大量的“數據平面加速”方案噴湧而出如果真是數據轉發的問題我們有智能網卡、DPDK等方案能很好解決。那麽比較實用的只剩下NAT模式了,但是LVS的NAT模式有一個很大的缺陷——Real Server的網關是指向Director。
LVS NAT的改進
一般面向外部提供服務的集群環境中網絡工程師會給我們一個外部IP,它可能是一個公網IP也可能是躲在防火墻後面的“私網IP”。總之只要我們把這個IP地址配置在某個機器上就能正常對外提供服務了。這種環境中LVS的DR模式、TUN模式顯的都比較繁瑣(需要滿足一定網絡條件),所以NAT模式是最合適的,但是LVS中的NAT要求Real Server必須把網關指向Director,這就意味著Real Server之前可以三層可達的網絡現在全部不行了(比如之前可以通過網關上網,現在則不行了)回憶一下問題:當Director發送數據包的時候源地址是客戶端IP地址,所以Real Server會把返回數據發送給網關,如果不把Director設置為Real Server的網關那麽返回數據就“丟”了。改進方法也呼之欲出了,讓Director發送數據包的時候使用DIP而不是客戶端的IP地址就可以了。按道理說通過LVS+SNAT可以實現,遺憾的是LVS和Iptables是不兼容的,LVS內部處理完數據包後Iptables會忽略這個數據包,所以解決辦法只剩下兩個:
-
在用戶空間實現一個反向代理,比如Nginx,並且VIP和DIP配置一樣;
-
修改LVS代碼重新編譯內核
第一種方法操作非常簡單,在Director上安裝一個反向代理,LVS配置的VIP和DIP保持一致就可以了,比如:
ipvsadm -A -t 192.168.122.100:80 -s rr
ipvsadm -a -t 192.168.122.100:80 -r 192.168.122.101 -m -w 1
ipvsadm -a -t 192.168.122.100:80 -r 192.168.122.102 -m -w 1
第二種方法就是阿裏後來貢獻的FullNat模式。
兩個疑問
-
為啥LVS不直接做徹底的NAT而直接使用客戶端IP地址呢?改進後的NAT怎麽規避這個問題?
這是由於LVS追求的是透明,試想Real Server如何拿到客戶端的IP地址?改進後的NAT Real Server只能看到Director的IP地址,客戶端的IP地址通過“額外途徑”發送。反向代理方案中直接通過應用層的頭部(比如HTTP的 x-forwarded-for);FullNAT方案中則通過TCP的Option帶到Real Server。
-
Linux內核為什麽不吸納FullNAT模式?
是的,FullNAT配置簡單速度也不慢所以是非常好的選擇。Linux Kernel沒有把它合並到內核代碼的原因是認為:FullNAT本質上是LVS+SNAT,當我們提到SNAT的時候其實就是在說“用戶空間”它不應該屬於內核。這是Linux的一大基本原則。https://www.mail-archive.com/[email protected]/msg06046.html 這裏你可以看到撕逼過程。
https://img-blog.csdn.net/2018062221223836?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2E3MjQ4ODg=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70
Iptables
前提基礎:**
當主機收到一個數據包後,數據包先在內核空間中處理,若發現目的地址是自身,則傳到用戶空間中交給對應的應用程序處理,若發現目的不是自身,則會將包丟棄或進行轉發。
iptables實現防火墻功能的原理是:在數據包經過內核的過程中有五處關鍵地方,分別是PREROUTING、INPUT、OUTPUT、FORWARD、POSTROUTING,稱為鉤子函數,iptables這款用戶空間的軟件可以在這5處地方寫規則,對經過的數據包進行處理,規則一般的定義為“如果數據包頭符合這樣的條件,就這樣處理數據包”。
iptables中定義有5條鏈,說白了就是上面說的5個鉤子函數,因為每個鉤子函數中可以定義多條規則,每當數據包到達一個鉤子函數時,iptables就會從鉤子函數中第一條規則開始檢查,看該數據包是否滿足規則所定義的條件。如果滿足,系統就會根據該條規則所定義的方法處理該數據包;否則iptables將繼續檢查下一條規則,如果該數據包不符合鉤子函數中任一條規則,iptables就會根據該函數預先定義的默認策略來處理數據包
iptables中定義有表,分別表示提供的功能,有filter表(實現包過濾)、nat表(實現網絡地址轉換)、mangle表(實現包修改)、raw表(實現數據跟蹤),這些表具有一定的優先級:raw-->mangle-->nat-->filter
一條鏈上可定義不同功能的規則,檢查數據包時將根據上面的優先級順序檢查


在講LVS之前要先搞懂vip和loopback的概念和原理
虛擬IP原理
高可用性HA(High Availability)指的是通過盡量縮短因日常維護操作(計劃)和突發的系統崩潰(非計劃)所導致的停機時間,以提高系統和應用的可用性。HA系統是目前企業防止核心計算機系統因故障停機的最有效手段。
實現HA的方式,一般采用兩臺機器同時完成一項功能,比如數據庫服務器,平常只有一臺機器對外提供服務,另一臺機器作為熱備,當這臺機器出現故障時,自動動態切換到另一臺熱備的機器。
怎麽實現故障檢測的那?
心跳,采用定時發送一個數據包,如果機器長時間沒響應,就認為是發生故障,自動切換到熱備的機器上去。
怎麽實現自動切換那?
虛IP。何為虛IP那,就是一個未分配給真實主機的IP,也就是說對外提供數據庫服務器的主機除了有一個真實IP外還有一個虛IP,使用這兩個IP中的 任意一個都可以連接到這臺主機,所有項目中數據庫鏈接一項配置的都是這個虛IP,當服務器發生故障無法對外提供服務時,動態將這個虛IP切換到備用主機。
原理:開始我也不明白這是怎麽實現的,以為是軟件動態改IP地址,其實不是這樣,其實現原理主要是靠TCP/IP的ARP協議。因為ip地址只是一個邏輯地址,在以太網中MAC地址才是真正用來進行數據傳輸的物理地址,每臺主機中都有一個ARP高速緩存,存儲同一個網絡內的IP地址與MAC地址的對應關 系,以太網中的主機發送數據時會先從這個緩存中查詢目標IP對應的MAC地址,會向這個MAC地址發送數據。操作系統會自動維護這個緩存。這就是整個實現 的關鍵。
下邊就是我電腦上的arp緩存的內容。
(192.168.1.219) at 00:21:5A:DB:68:E8 [ether] on bond0 (192.168.1.217) at 00:21:5A:DB:68:E8 [ether] on bond0 (192.168.1.218) at 00:21:5A:DB:7F:C2 [ether] on bond0
192.168.1.217、192.168.1.218是兩臺真實的電腦,
192.168.1.217為對外提供數據庫服務的主機。
192.168.1.218為熱備的機器。
192.168.1.219為虛IP。
大家註意紅字部分,219、218的MAC地址是相同的。
再看看那217宕機後的arp緩存
(192.168.1.219) at 00:21:5A:DB:7F:C2 [ether] on bond0 (192.168.1.217) at 00:21:5A:DB:68:E8 [ether] on bond0 (192.168.1.218) at 00:21:5A:DB:7F:C2 [ether] on bond0
這就是奧妙所在。當218 發現217宕機後會向網絡發送一個ARP數據包,告訴所有主機192.168.1.219(虛IP對外提供服務)這個IP對應的MAC地址是00:21:5A:DB:7F:C2,這樣所有發送到219的數據包都會發送到mac地址為00:21:5A:DB:7F:C2的機器,
也就是218的機器。
總結一下就是:
我們知道一般的IP地址是和物理網卡綁定的,而VIP相反,是不與實際網卡綁定的的IP地址。當外網的上的一個機器,通過域名訪問某公司內網資源時,內網的DNS服務器會把域名解析到一個VIP上。當外網主機經過域名解析得到這個VIP後,就將數據包發往這個VIP。但是在內網中,這個VIP是不與具體的設備相連接的,所以外網發過來的目的地址是VIP的IP數據包,最終會到哪臺機器是通過ARP協議來完成的。也就是說這個VIP可以映射到的MAC地址是可以控制的。VIP在內網中被動態的映射到不同的MAC地址上,也就是映射到不同的機器設備上,那麽就可以起到負載均衡的效果啦。
Linux回環接口 Loopback
Loopback接口是一個虛擬網絡接口,在不同的領域,其含義也大不一樣。
1. TCP/IP協議棧中的loopback接口
在TCP/IP中回環設備是一個通過軟件實現的虛擬網絡接口,它不與任何硬件相關聯。loopback接口一般被完整的集成在計算機系統的內部網絡框架中。
IP協議中的loopback地址 RFC2606中明確指出了loopback地址的標準域名為localhost。在IPv4中,其對應的IP地址一直是127.0.0.1;理論上,整個127IP段(127.0.0.0~127.255.255.255)的IP地址都為loopback地址,與localhost對應。在IPv6中,localhost對應的IP地址為0:0:0:0:0:0:0:1,一般寫作::1。
loopback接口的功能
-
用於網絡服務測試,避免由於遠程網絡接入帶來的安全問題; 一般用作client/server類的網絡服務的測試,在測試時,client與server運行在同一臺主機上,client通過使用loopback地址訪問server。最常見的例子就是web服務的測試,一般我們用http://127.0.0.1/或者http://localhost/來訪問本地的web服務。
-
測試IP協議棧 我們通過ping loopback地址的方式來測試操作系統中IP協議棧是否正常。
-
在網絡中,所有源地址屬於loopback地址的數據包將會被丟棄 IP協議規定loopback數據包是不允許在網絡中傳輸的。網絡網絡接口必須丟棄接收到的loopback數據包。
2. 網絡設備中的loopback 在網絡設備中,loopback被用來代表某些用於管理目的的虛擬接口,其含義並沒有"回環"的意思。
loopback虛擬接口會分配到一個IP地址,但是這個IP地址不會對應到實際的物理接口。網絡設備中的loopback地址主要用於管理目的,例如設備發出的報警。網絡設備中的應用程序(管理程序)使用loopback地址發送可接收數據流,而不是使用實際物理接口的地址。對外部來說,直接使用loopback地址來查看設備對應的信息(如報警信息),與網卡的物理地址無關。
這裏我們也可以把這種地址理解為網絡設備提供的某個服務的地址。
linux的網絡接口之掃盲
(1)網絡接口的命名
這裏並不存在一定的命名規範,但網絡接口名字的定義一般都是要有意義的。例如:
eth0: ethernet的簡寫,一般用於以太網接口。
wifi0:wifi是無線局域網,因此wifi0一般指無線網絡接口。
ath0: Atheros的簡寫,一般指Atheros芯片所包含的無線網絡接口。
lo: local的簡寫,一般指本地環回接口。
(2)網絡接口如何工作
網絡接口是用來發送和接受數據包的基本設備。
系統中的所有網絡接口組成一個鏈狀結構,應用層程序使用時按名稱調用。
每個網絡接口在linux系統中對應於一個struct net_device結構體,包含name,mac,mask,mtu…信息。
每個硬件網卡(一個MAC)對應一個網絡接口,其工作完全由相應的驅動程序控制。
(3)虛擬網絡接口
虛擬網絡接口的應用範圍非常廣泛。最著名的當屬“lo”了,基本上每個linux系統都有這個接口。
虛擬網絡接口並不真實地從外界接收和發送數據包,而是在系統內部接收和發送數據包,因此虛擬網絡接口不需要驅動程序。
虛擬網絡接口和真實存在的網絡接口在使用上是一致的。
(4)網絡接口的創建
硬件網卡的網絡接口由驅動程序創建。而虛擬的網絡接口由系統創建或通過應用層程序創建。
驅動中創建網絡接口的函數是:register_netdev(struct net_device *)或者register_netdevice(struct net_device *)。
這兩個函數的區別是:register_netdev(…)會自動生成以”eth”作為打頭名稱的接口,而register_netdevice(…)需要提前指定接口名稱.事實上,register_netdev(…)也是通過調用register_netdevice(…)實現的。
2、LINUX中的lo(回環接口)
1) 什麽是LO接口?
在LINUX系統中,除了網絡接口eth0,還可以有別的接口,比如lo(本地環路接口)。
2) LO接口的作用是什麽?
假如包是由一個本地進程為另一個本地進程產生的, 它們將通過外出鏈的’lo’接口,然後返回進入鏈的’lo’接口.具體參考包過濾器的相關內容。
為什麽要把vip綁定在lo上
因為數據幀的MAC地址是選出的服務器,所以服務器肯定可以收到這個數據幀,從中可以獲得該IP報文。當服務器發現報文的目標地址VIP是在本地的網絡設備上,服務器處理這個報文,然後根據路由表將響應報文直接返回給客戶。
收到VIP轉發數據幀的,不是lo,而是real server的物理網卡。
物理網卡收到數據幀之後,拆開看到目的地址是VIP
查找路由表,自己的lo上綁著VIP,說明這個包是自己需要處理的,就把這個活接了,產生響應報文
real server返回給客戶端的數據幀,源mac是real server物理網卡的mac,裏面的源IP地址是VIP
客戶端收到數據幀之後,看到目的mac和目的IP都是自己,就會接收。並不會去檢查源mac
附:FAQ
1、LVS/DR如何處理請求報文的,會修改IP包內容嗎?
vs/dr本身不會關心IP層以上的信息,即使是端口號也是tcp/ip協議棧去判斷是否正確,vs/dr本身主要做這麽幾個事:
接收client的請求,根據你設定的負載均衡算法選取一臺realserver的ip; 以選取的這個ip對應的mac地址作為目標mac,然後重新將IP包封裝成幀轉發給這臺RS; 在hashtable中記錄連接信息。 vs/dr做的事情很少,也很簡單,所以它的效率很高,不比硬件負載均衡設備差多少。
2、RealServer為什麽要在lo接口上配置VIP,在出口網卡上配置VIP可以嗎?
既然要讓RS能夠處理目標地址為vip的IP包,首先必須要讓RS能接收到這個包。在lo上配置vip能夠完成接收包並將結果返回client。
不可以將VIP設置在出口網卡上,否則會響應客戶端的arp request,造成client/gateway arp table紊亂,以至於整個loadbalance都不能正常工作。
3、RealServer為什麽要抑制arp幀?
這個問題在上一問題中已經作了說明,這裏結合實施命令進一步闡述。我們在具體實施部署的時候都會作如下調整:
echo "1" >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo "2">/proc/sys/net/ipv4/conf/lo/arp_announce
echo "1">/proc/sys/net/ipv4/conf/all/arp_ignore
echo "2">/proc/sys/net/ipv4/conf/all/arp_announce
我相信很多人都不會弄懂它們的作用是什麽,只知道一定得有。我這裏也不打算拿出來詳細討論,只是作幾點說明,就當是補充吧。
第一 echo "1" >/proc/sys/net/ipv4/conf/lo/arp_ignore echo "2" >/proc/sys/net/ipv4/conf/lo/arp_announce 1 2 這兩條是可以不用的,因為arp對邏輯接口沒有意義。
第二 如果你的RS的外部網絡接口是eth0,那麽
echo "1">/proc/sys/net/ipv4/conf/all/arp_ignore
echo "2">/proc/sys/net/ipv4/conf/all/arp_announce
其實真正要執行的是:
echo "1">/proc/sys/net/ipv4/conf/eth0/arp_ignore echo "2">/proc/sys/net/ipv4/conf/eth0/arp_announce
所以我個人建議把上面兩條也加到你的腳本裏去,因為萬一系統裏上面兩條默認的值不是0,那有可能是會出問題滴。
4、LVS/DR loadbalancer(director)與RS為什麽要在同一網段中?
從第一個問題中大家應該明白vs/dr是如何將請求轉發給RS的了吧?它是在數據鏈路層來實現的,所以director必須和RS在同一網段裏面。
5、為什麽director上eth0接口除了VIP另外還要配一個ip(即DIP)?
如果是用了keepalived等工具做HA或者LoadBalance,則在健康檢查時需要用到DIP, 沒有健康檢查機制的HA或者Load Balance則沒有存在的實際意義.
6、LVS/DR ip_forward需要開啟嗎?
不需要。因為director跟realserver是同一個網段,無需開啟轉發。
7、lvs/dr裏,director的vip的netmask 沒必要設置為255.255.255.255,也不需要再去 route add -host $VIP dev eth0:0,director的vip本來就是要像正常的ip地址一樣對外通告的,不要搞得這麽特殊。
搞懂分布式技術10:LVS實現負載均衡的原理與實踐