
強化學習: Experience Replay
我第一次接觸 Experience Replay 概念是李巨集毅老師的視訊課上。當時李巨集毅老師說 為什麼Experience Replay 可行留作自己思考,然後並沒有做太詳細的解釋。接下來,我就把我對Experience Replay 的理解寫下來。
首先,我把李巨集毅老師的Q-learning 演算法貼出來,他的Q-learning 演算法跟傳統Q-learning 演算法有一些微小的區別

以下是Experience Replay
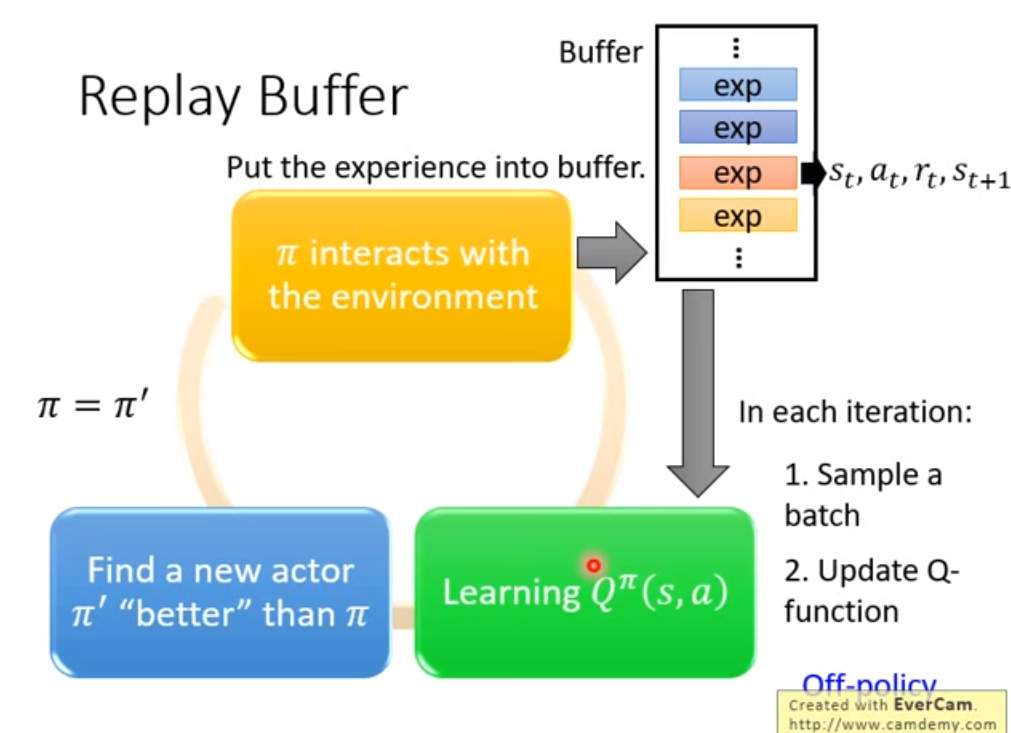
在看到這裡的時候,就會有一個疑問,在buffer 中儲存的是很多之前的策略,用這個策略能夠作為 當前策略的學習資料嗎?
結論當然是可以的。
因為這些只是資料,並不是策略。(st,at,rt,st+1)這樣一組資料,其實跟策略是沒有什麼關係的。rt是環境返回的,可以當作是個常量,st+1 這個也是環境決定的。 我們的目標學習是(st,at)狀態對的 Q value.
所以這個 Experience Buffer是可以一定程度上 增加資料多樣性的。因為同一個策略 在st上產生的行為 總是at,而我們的Q-learning是希望能夠學習更多的狀態對,這樣他的泛化效能也會更好。在這裡我舉個例子:
我們在訓練神經網路的時候,在每個batch裡面,我們希望資料之間會更加多樣性(還有很多其他說法,更加獨立,更加diverse 其實都死一個意思)。為什麼呢?
加入我們要一個語義相似度任務,跟sentence1 和 sentence2 判斷他們相似還是不相似,相似的話 輸出結果為1 ,不相似的話,輸出結果為2
這個時候我們一定是要資料打亂在傳入神經網路。如果你嘗試把相似句子為一批傳進神經網路 不相似資料為一批 在傳進神經網路,你會發現網路根本沒法訓練。網路就不斷地交替學習 所有輸出資料全部輸出1 或者全部輸出 0。
在同一個策略上產生的資料顯然不能滿足這樣的要求。而Experience Replay就可以解決這樣的問題。