
EM演算法(基礎及核心概念)
Jensen不等式
其實在運籌學以及基礎的優化理論中,便有涉及。設f是定義域為實數的函式,如果對於所有的實數x,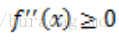
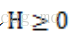
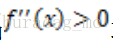
Jensen不等式表述如下:
如果f是凸函式,X是隨機變數,那麼
特別地,如果f是嚴格凸函式,當且僅當
(也就是說X是常量時),
成立,畫一個草圖可以直觀地看出:
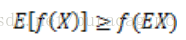
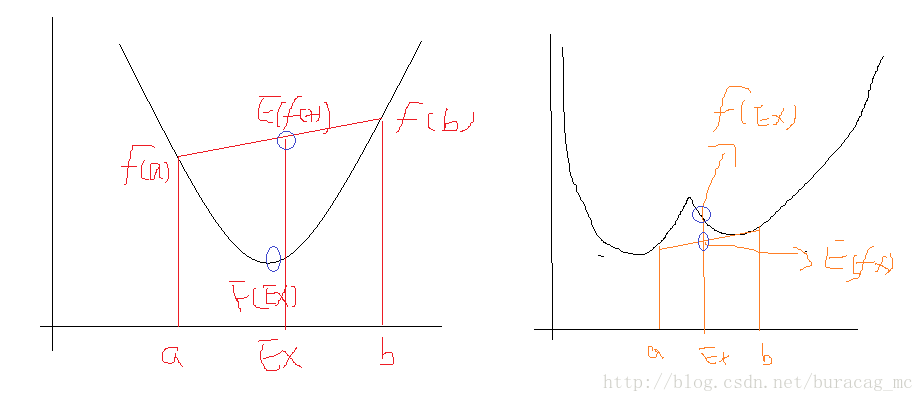
可以看到,左圖是符合我們對於凸函式的定義的,右圖則不符合。
同理我們可以知道,當Jensen不等式應用於凹函式時,不等號變向,即
最大似然估計
在講解EM演算法之前,還需要最大似然估計的相關知識。
假設我們需要調查學校的男生的身高分佈。我們進行簡單隨機抽樣(當然,分層抽樣啊,整群抽樣都是OK的~),隨機抽選了100個男生作為抽樣樣本。然後得到的100個樣本值。假設他們的身高(對應的男生總體)是服從高斯分佈(總體分佈)的。但是這個分佈的均值u和方差
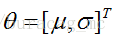
用數理統計的語言表達出來便是,我們獨立地按照概率密度p(x|θ)抽取100樣本組成樣本集X,我們想通過樣本集X來估計出未知引數θ。這裡假設概率密度p(x|θ)我們知道了是高斯分佈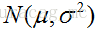
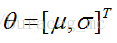
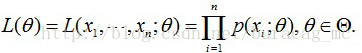
這個聯合概率反映了,在概率密度函式的引數是
極大似然估計,是一種概率論在統計學的應用,它是常見的引數估計的方法之一。其是建立在這樣的思想上:已知某個引數能使這個樣本集出現的概率最大,我們當然不會再去選擇使得這個樣本集出現的概率較小的引數,所以乾脆就把這個引數作為估計的真實值
比較拗口哈~,不過理解起來還是比較容易的。就拿前面的例子說,如果引數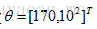
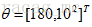
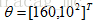
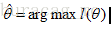
但通常為了便於分析,可以取對數得到對數似然函式,
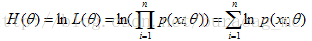
即:
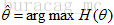
好了,現在我們知道了,要求解θ,只需要使θ的似然函式L(θ)極大化,然後極大值對應的θ就是我們的估計。這裡就回到了求最值的問題了。怎麼求一個函式的最值呢?當然,在存在解析解的情況下,我們直接求其偏導數並令其為0即可得出;
但是在不存在解析解或者直接求解比較困年的情況下,我們通常是採取梯度下降(上升)法來進行求解的,例如典型的LR的引數求解中便是利用了梯度下降法;又SVM在求解的實現時,利用SMO求解時,是同時對兩個拉格朗日乘子進行梯度上升法(由於SMO是求解max W(a),詳見博文http://blog.csdn.net/buracag_mc/article/details/76762249),同樣利用迭代來求解的。這裡不是本文的側重點,故不再展開贅述了。
大概總結一下,求解最大似然函式估計值的一般步驟:
求得聯合概率密度,寫出似然函式;
對似然函式取對數,並整理;
求偏導數,並令其為0,得到似然方程;
求解似然方程,得到的引數即為所求。
EM演算法
給定的訓練樣本集,樣本間獨立,我們想找到每個樣例隱含的類別z,能使得p(x,z)最大。p(x,z)的最大對數似然估計如下:
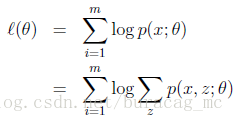
利用似然估計求解的思想。
求得似然函式
取對數,得到對數似然函式
對每個樣例的每個可能類別z求聯合分佈概率和。
但是直接求
EM是一種解決存在隱含變數優化問題的有效方法。既然不能直接最大化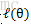
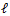
對於每一個樣本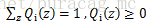
講的比較抽樣哈?沒關係,繼續用小例子來說明:
對於第二部分講的似然估計的內容,我們要估計的只有一個總體的引數(即學校男生的身高分佈引數);但是如果我們要同時估計男生和女生的身高分佈情況呢?
我們改變一下假設,同時隨機選取100個男生和100個女生混在一起,得到一個樣本值後(即身高值),我們不知道是從男生的那個身高分佈中選取的,還是從女生的那個身高分佈中選取的。對於每一個樣本,我們就有兩個東西需要進行估計的了:
其一是這個人是男生還是女生?
其二是男生和女生對應的身高的高斯分佈的引數是多少?
這裡假設隱藏變數z是身高,那麼隱藏變數對應的分佈就是連續的高斯分佈。如果隱藏變數z是男女,那麼就是伯努利分佈了。這樣講,應該是比較容易理解隱藏變數的意思了。
下面我們假設隱藏變數z是男女,可以由前面闡述的內容得到下面的公式:
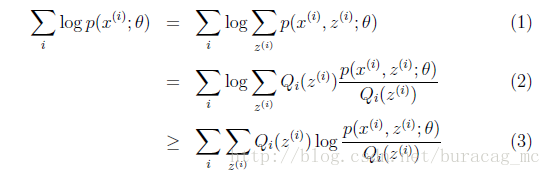
(1)式到(2)式沒問題,就是分子分母同乘以一個相等的函式,這裡即是隱藏變數的概率密度函式。(2)式到(3)式利用到了第一部分講的Jensen不等式,首先考慮到
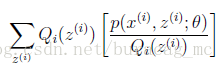
就是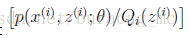
即將自變數看成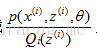
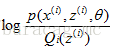
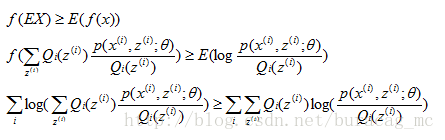
這個過程可以看作是對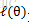
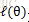
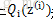
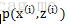
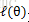
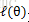
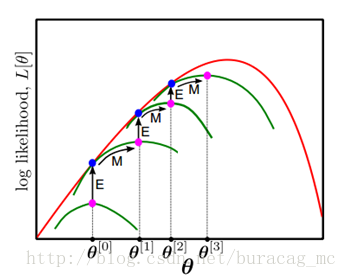
按照這個思路,我們要找到等式成立的條件。根據Jensen不等式,要想讓等式成立,需要讓隨機變數變成常數值,即:
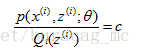
c為常量,不依賴於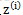
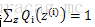
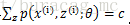
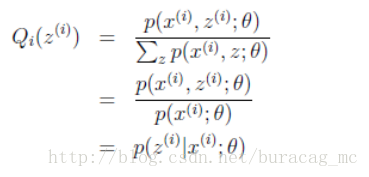
至此,我們推出了在固定其他引數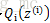
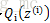
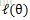
接下來的便是M步,就是在給定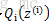
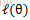
那麼一般的EM演算法的步驟如下:
初始化分佈引數
θ ;重複以下步驟直到收斂:
- E步驟:根據引數初始值或上一次迭代的模型引數來計算出隱性變數的後驗概率,其實就是隱性變數的期望。作為隱藏變數的現估計值:
- M步驟:將似然函式最大化以獲得新的引數值:
- E步驟:根據引數初始值或上一次迭代的模型引數來計算出隱性變數的後驗概率,其實就是隱性變數的期望。作為隱藏變數的現估計值:
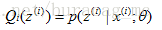
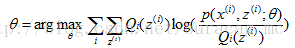
如何確保EM的引數估計值收斂呢?假定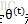
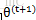
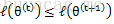
詳細證明可以參考部落格【2】
最終會得到證明結果:
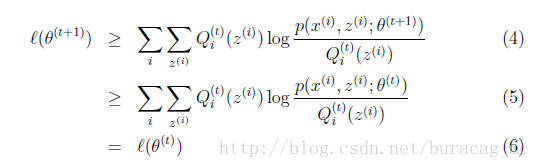
這樣就證明了會單調增加。一種收斂方法是不再變化,還有一種就是變化幅度很小。
OK,我們將EM演算法的思想用到我們這部分的例子上:
首先我們初始化引數
θ ,男生的總體分佈引數,女生的總體的分佈引數
;
然後我們將200個樣本值分別計算出隱藏變數的後驗概率,作為隱藏變數的現估計值。即在樣本
xi 的取值下,該樣本屬於男生的後驗概率是多少,屬於女生的後驗概率是多少,並將該樣本劃分到後驗概率最大的那類去。即E步。將200個樣本劃分給男生和女生完成後,重新根據對應的樣本,參照我們第二部分的內容,做極大似然估計,得到更新後的引數
θ 值。即M步重複二、三步,直到收斂
最後,輸出男生和女生對應總體分佈的引數值。
參考資料如下: