
HashMap的底層實現原理
最近做的幾個專案都是用Map來儲存的資料 ,雖然用得挺順手,但是對HashMap的底層原理卻只知甚少,今天便來簡單學習和整理一下。
資料結構中有陣列和連結串列這兩個結構來儲存資料。
陣列儲存區間是連續的,佔用記憶體嚴重,故空間複雜的很大。但陣列的二分查詢時間複雜度小,為O(1);陣列的特點是:定址容易,插入和刪除困難;
連結串列儲存區間離散,佔用記憶體比較寬鬆,故空間複雜度很小,但時間複雜度很大,達O(N)。連結串列的特點是:定址困難,插入和刪除容易。
綜合這兩者的優點,摒棄缺點,雜湊表就誕生了,既滿足了資料查詢方面的特點,佔用的空間也不大。
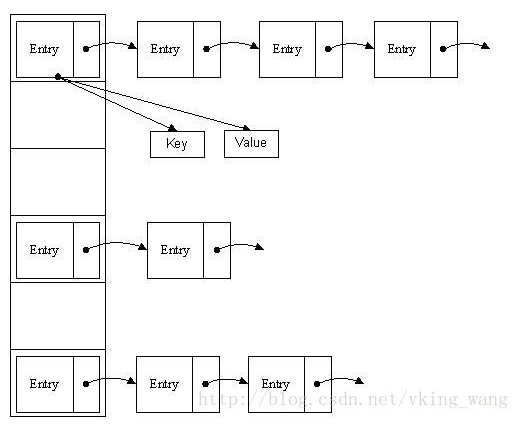
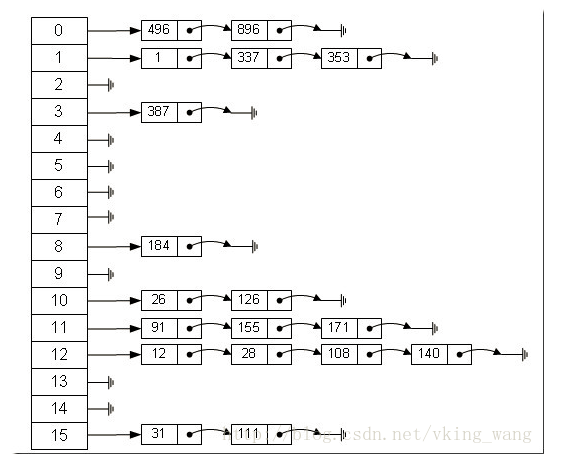
雜湊表可以說就是陣列連結串列,底層還是陣列但是這個陣列每一項就是一個連結串列。
在這個陣列中,每個元素儲存的其實是一個連結串列的頭,元素的儲存位置一般情況是通過hash(key)%len獲得,也就是元素的key的雜湊值對陣列長度取模得到。比如上述雜湊表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都儲存在陣列下標為12的位置。
HashMap的建構函式
HashMap實現了Map介面,繼承AbstractMap。其中Map介面定義了鍵對映到值的規則,而AbstractMap類提供 Map 介面的骨幹實現。
HashMap提供了三個建構函式:
HashMap():構造一個具有預設初始容量 (16) 和預設載入因子 (0.75) 的空 HashMap。
HashMap(int initialCapacity):構造一個帶指定初始容量和預設載入因子 (0.75) 的空 HashMap。
HashMap(int initialCapacity, float loadFactor):構造一個帶指定初始容量和載入因子的空 HashMap。

public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();
每次初始化HashMap都會構造一個table陣列,而table陣列的元素為Entry節點。
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
}
HashMap也可以說是一個數組連結串列,HashMap裡面有一個非常重要的內部靜態類——Entry,這個Entry非常重要,它裡面包含了鍵key,值value,下一個節點next,以及hash值,Entry是HashMap非常重要的一個基礎Bean,因為所有的內容都存在Entry裡面,HashMap的本質可以理解為 Entry[ ] 陣列。
HashMap.put(key,value)
public V put(K key, V value) {
//當key為null,呼叫putForNullKey方法,儲存null與table第一個` 位置中,這是HashMap允許為null的原因
if (key == null)
return putForNullKey(value);
//計算key的hash值
int hash = hash(key.hashCode()); ------(1)
//計算key hash 值在 table 陣列中的位置
int i = indexFor(hash, table.length); ------(2)
//從i出開始迭代 e,找到 key 儲存的位置
for (Entry<K, V> e = table[i]; e != null; e = e.next) {
Object k;
//判斷該條鏈上是否有hash值相同的(key相同)
//若存在相同,則直接覆蓋value,返回舊value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value; //舊值 = 新值
e.value = value;
e.recordAccess(this);
return oldValue; //返回舊值
}
}
//修改次數增加1
modCount++;
//將key、value新增至i位置處
addEntry(hash, key, value, i);
return null;
}
我簡單的理解一下,當執行put操作的時候,HashMap會先判斷一下要儲存內容的key值是否為null,如果為null,如果為null,則執行putForNullKey方法,這個方法的作用就是將內容儲存到Entry[]陣列的第一個位置,如果key不為null,則去計算key的hash值,然後對陣列長度取模,得到要儲存位置的下標,再迭代該陣列元素上的連結串列,看該連結串列上是否有hash值相同的,如果有hash值相同的,就直接覆蓋value的值,如果沒有hash值相同的情況,就將該內容儲存到連結串列的表頭,最先儲存的內容會放在連結串列的表尾,其實這帶程式碼也順道解釋了HashMap沒有Key值相同的情況。這裡還有一個情況也要說明一下,會不會出現連結串列過長的情況?隨著要儲存的內容越來越多,HashMap裡面的東西也越來越多,相同下標的情況也增多,那麼迭代連結串列的也無疑增加了,這會影響資料的查詢效率,HashMap對此也做了優化,當HashMap中儲存的內容超過陣列長度 *loadFactor時,陣列就會進行擴容,預設的陣列長度是16,loadFactor為載入因子,預設的值為0.75。對於擴容需要說明的一點就是,擴容是一個非常“消耗”的過程,需要重新計算資料在新陣列中的位置,並且將內容複製到新陣列中,如果我們預先知道HashMap中的元素個數,預設元素的個數,能有效的提高HashMap的儲存效率。
HashMap.get(key)
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
get(key)方法的程式碼比較好理解,根據key的hash值找到對應的Entry即連結串列,然後在返回該key值對應的value。
HashMap的遍歷
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
|
使用HashMap的匿名內部類Entry遍歷比使用keySet()效率要高很多,使用forEach迴圈時要注意不要在迴圈的過程中改變鍵值對的任何一方的值,否則出現雜湊表的值沒有隨著鍵值的改變而改變,到時候在刪除的時候會出現問題。 此外,entrySet比keySet快些。對於keySet其實是遍歷了2次,一次是轉為iterator,一次就從hashmap中取出key所對於的value。而entrySet只是遍歷了第一次,他把key和value都放到了entry中,所以就快了。