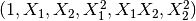常用的資料預處理方法
以下是基於Python_sklearn來實現的:
No1.標準化(Standardization or Mean Removal and Variance Scaling)
變換後各維特徵有0均值,單位方差。也叫z-score規範化(零均值規範化)。計算方式是將特徵值減去均值,除以標準差。
>>> from sklearn import preprocessing
>>> X=[[1.,-1.,2.],
[2.,0.,0.],
[0.,1.,-1.]]
>>> X_scaled = preprocessing.scale(X)
>>> X_scaled
array([[ 0. , -1.22474487, 1.33630621],
[ 1.22474487, 0. , -0.26726124],
[-1.22474487, 1.22474487, -1.06904497]] scale處理之後為零均值和單位方差:
>>> X_scaled.mean(axis=0)
array([ 0., 0., 0.])
>>> X_scaled.std(axis=0)
array([ 1., 1., 1.]) 同樣我們也可以通過preprocessing模組提供的StandardScaler 工具類來實現這個功能:
>>> scaler = preprocessing.StandardScaler().fit(X)
>>> scaler
StandardScaler(copy=True, with_mean=True, with_std=True)
>>> scaler.mean_
array([ 1. 簡單來說,我們一般會把train和test集放在一起做標準化,或者在train集上做標準化後,用同樣的標準化器去標準化test集,此時可以用scaler :
>>> scaler = sklearn.preprocessing.StandardScaler().fit(train)
>>> scaler.transform(train)
>>> scaler.transform(test)No2.最小-最大規範化(Scaling features to a range)
最小-最大規範化對原始資料進行線性變換,變換到[0,1]區間(也可以是其他固定最小最大值的區間)。通過MinMaxScaler or MaxAbsScaler來實現。
>>> X_train = np.array([[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]])
...
>>> min_max_scaler = preprocessing.MinMaxScaler()
>>> X_train_minmax = min_max_scaler.fit_transform(X_train)
>>> X_train_minmax
array([[ 0.5 , 0. , 1. ],
[ 1. , 0.5 , 0.33333333],
[ 0. , 1. , 0. ]])簡單來說:
>>> min_max_scaler = sklearn.preprocessing.MinMaxScaler()
>>> min_max_scaler.fit_transform(X_train)No3.Scaling data with outliers
當特徵中含異常值時:
>>> sklearn.preprocessing.robust_scaleScaling sparse data
No4.規範化(Normalization)
規範化是將不同變化範圍的值對映到相同的固定範圍,常見的是[0,1],此時也稱為歸一化。Normalize 有L1和L2兩個標準。
>>> X = [[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]]
>>> X_normalized = preprocessing.normalize(X, norm='l2')
>>> X_normalized
array([[ 0.40824829, -0.40824829, 0.81649658],
[ 1. , 0. , 0. ],
[ 0. , 0.70710678, -0.70710678]])
>>> normalizer = preprocessing.Normalizer().fit(X) # fit does nothing
>>> normalizer
Normalizer(copy=True, norm='l2')
>>> normalizer.transform(X)
array([[ 0.40824829, -0.40824829, 0.81649658],
[ 1. , 0. , 0. ],
[ 0. , 0.70710678, -0.70710678]])
>>> normalizer.transform([[-1., 1., 0.]])
array([[-0.70710678, 0.70710678, 0. ]])
簡單來說,將每個樣本變換成unit norm:
>>> X = [[ 1, -1, 2],[ 2, 0, 0], [ 0, 1, -1]]
>>> sklearn.preprocessing.normalize(X, norm='l2')得到:
array([[ 0.40, -0.40, 0.81], [ 1, 0, 0], [ 0, 0.70, -0.70]])可以發現對於每一個樣本都有,0.4^2+0.4^2+0.81^2=1,這就是L2 norm,變換後每個樣本的各維特徵的平方和為1。類似地,L1 norm則是變換後每個樣本的各維特徵的絕對值和為1。還有max norm,則是將每個樣本的各維特徵除以該樣本各維特徵的最大值。
在度量樣本之間相似性時,如果使用的是二次型kernel,需要做Normalization。而且,normalize and Normalizer接受scipy密集的陣列類和稀疏矩陣。
No5.特徵二值化(Binarization)
特徵二值化閾值的過程即將數值型資料轉化為布林型的二值資料,可以設定一個閾值(threshold)。即給定閾值,將特徵轉換為0/1。
>>> X = [[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]]
>>> binarizer = preprocessing.Binarizer().fit(X) # fit does nothing
>>> binarizer
Binarizer(copy=True, threshold=0.0) # 預設閾值為0.0
>>> binarizer.transform(X)
array([[ 1., 0., 1.],
[ 1., 0., 0.],
[ 0., 1., 0.]])
>>> binarizer = preprocessing.Binarizer(threshold=1.1) # 設定閾值為1.1
>>> binarizer.transform(X)
array([[ 0., 0., 1.],
[ 1., 0., 0.],
[ 0., 0., 0.]])簡單來說:
>>> binarizer = sklearn.preprocessing.Binarizer(threshold=1.1)
>>> binarizer.transform(X)normalize and Normalizer接受scipy密集的陣列類和稀疏矩陣。
No6.類別特徵編碼(Encoding categorical features)
有時候特徵是類別型的,而一些演算法的輸入必須是數值型,此時需要對其編碼。
>>> enc = preprocessing.OneHotEncoder()
>>> enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]])
OneHotEncoder(categorical_features='all', dtype=<... 'numpy.float64'>,
handle_unknown='error', n_values='auto', sparse=True)
>>> enc.transform([[0, 1, 3]]).toarray()
array([[ 1., 0., 0., 1., 0., 0., 0., 0., 1.]])簡單來說:
>>> enc = preprocessing.OneHotEncoder()
>>> enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]])
>>> enc.transform([[0, 1, 3]]).toarray() #array([[ 1., 0., 0., 1., 0., 0., 0., 0., 1.]])其實可以通過從字典載入特徵來實現上面的思想:
>>>measurements = [
{'city': 'Dubai', 'temperature': 33.},
{'city': 'London', 'temperature': 12.},
{'city': 'San Fransisco', 'temperature': 18.},
]
>>> from sklearn.feature_extraction import DictVectorizer
array([[ 1., 0., 0., 33.], [ 0., 1., 0., 12.], [ 0., 0., 1., 18.]])
>>> vec.get_feature_names()
['city=Dubai', 'city=London', 'city=San Fransisco', 'temperature']
No7.標籤編碼(Label encoding)
>>> le = sklearn.preprocessing.LabelEncoder()
>>> le.fit([1, 2, 2, 6])
>>> le.transform([1, 1, 2, 6]) #array([0, 0, 1, 2])
>>> #非數值型轉化為數值型
>>> le.fit(["paris", "paris", "tokyo", "amsterdam"])
>>> le.transform(["tokyo", "tokyo", "paris"]) #array([2, 2, 1])No8.標籤二值化(Label binarization)
LabelBinarizer通常通過一個多類標籤(label)列表,建立一個label指示器矩陣
>>> lb = preprocessing.LabelBinarizer()
>>> lb.fit([1, 2, 6, 4, 2])
LabelBinarizer(neg_label=0, pos_label=1)
>>> lb.classes_
array([1, 2, 4, 6])
>>> lb.transform([1, 6])
array([[1, 0, 0, 0],
[0, 0, 0, 1]])LabelBinarizer也支援每個例項資料顯示多個標籤(label)
>>> lb.fit_transform([(1, 2), (3,)]) #(1,2)例項中就包含兩個label
array([[1, 1, 0],
[0, 0, 1]])
>>> lb.classes_
array([1, 2, 3])No9.生成多項式特徵(Generating polynomial features)
這個其實涉及到特徵工程了,多項式特徵/交叉特徵。
>>> poly = sklearn.preprocessing.PolynomialFeatures(2)
>>> poly.fit_transform(X)原始特徵:
轉化後為: