
MNIST手寫體識別任務
下面我們介紹一個神經網路中的經典示例,MNIST手寫體識別。這個任務相當於是機器學習中的HelloWorld程式。
MNIST資料集介紹
MNIST是一個簡單的圖片資料集,包含了大量的數字手寫體圖片。下面是一些示例圖片:

MNIST資料集是含標註資訊的,以上圖片分別代表5, 0, 4和1。
由於MNIST資料集是TensorFlow的示例資料,所以我們不必下載。只需要下面兩行程式碼,即可實現資料集的讀取工作:
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets MNIST資料集一共包含三個部分:訓練資料集(55,000份,mnist.train)、測試資料集(10,000份,mnist.test)和驗證資料集(5,000份,mnist.validation)。一般來說,訓練資料集是用來訓練模型,驗證資料集可以檢驗所訓練出來的模型的正確性和是否過擬合,測試集是不可見的(相當於一個黑盒),但我們最終的目的是使得所訓練出來的模型在測試集上的效果(這裡是準確性)達到最佳。
MNIST中的一個數據樣本包含兩塊:手寫體圖片和對於的label。這裡我們用xs和ys分別代表圖片和對應的label,訓練資料集和測試資料集都有xs和ys,我們使用
mnist.train.images 和 mnist.train.labels 表示訓練資料集中圖片資料和對於的label資料。
一張圖片是一個28*28的畫素點矩陣,我們可以用一個同大小的二維整數矩陣來表示。如下:

但是,這裡我們可以先簡單地使用一個長度為28 * 28 = 784的一維陣列來表示影象,因為下面僅僅使用softmax regression來對圖片進行識別分類(儘管這樣做會損失圖片的二維空間資訊,所以實際上最好的計算機視覺演算法是會利用圖片的二維資訊的)。
所以MNIST的訓練資料集可以是一個形狀為55000 * 784位的tensor,也就是一個多維陣列,第一維表示圖片的索引,第二維表示圖片中畫素的索引(”tensor”中的畫素值在0到1之間)。如下圖:

MNIST中的數字手寫體圖片的label值在1到9之間,是圖片所表示的真實數字。這裡用One-hot vector來表述label值,vector的長度為label值的數目,vector中有且只有一位為1,其他為0.為了方便,我們表示某個數字時在vector中所對應的索引位置設定1,其他位置元素為0. 例如用[0,0,0,1,0,0,0,0,0,0]來表示
3。所以,mnist.train.labels是一個55000
* 10的二維陣列。如下:

以上是MNIST資料集的描述及TensorFlow中表示。下面介紹Softmax Regression模型。
Softmax Regression模型
數字手寫體圖片的識別,實際上可以轉化成一個概率問題,如果我們知道一張圖片表示9的概率為80%,而剩下的20%概率分佈在8,6和其他數字上,那麼從概率的角度上,我們可以大致推斷該圖片表示的是9.
Softmax Regression是一個簡單的模型,很適合用來處理得到一個待分類物件在多個類別上的概率分佈。所以,這個模型通常是很多高階模型的最後一步。
Softmax Regression大致分為兩步(暫時不知道如何合理翻譯,轉原話):
Step 1: add up the evidence of our input being in certain classes;
Step 2: convert that evidence into probabilities.

具體計算方式如下:
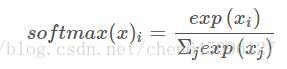
這裡的softmax函式能夠得到類別上的概率值分佈,並保證所有類別上的概率值之和為1.
下面的圖示將有助於你理解softmax函式的計算過程:
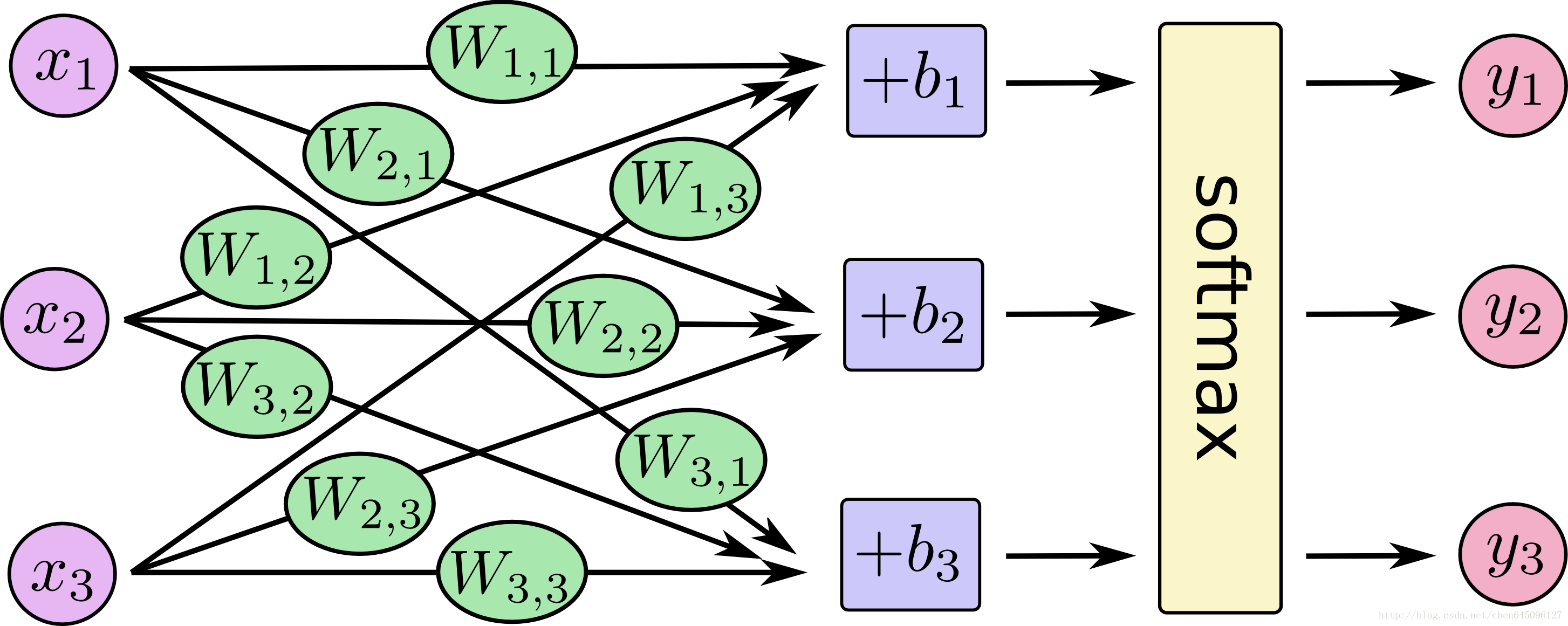
如果我們將這個過程公式化,將得到
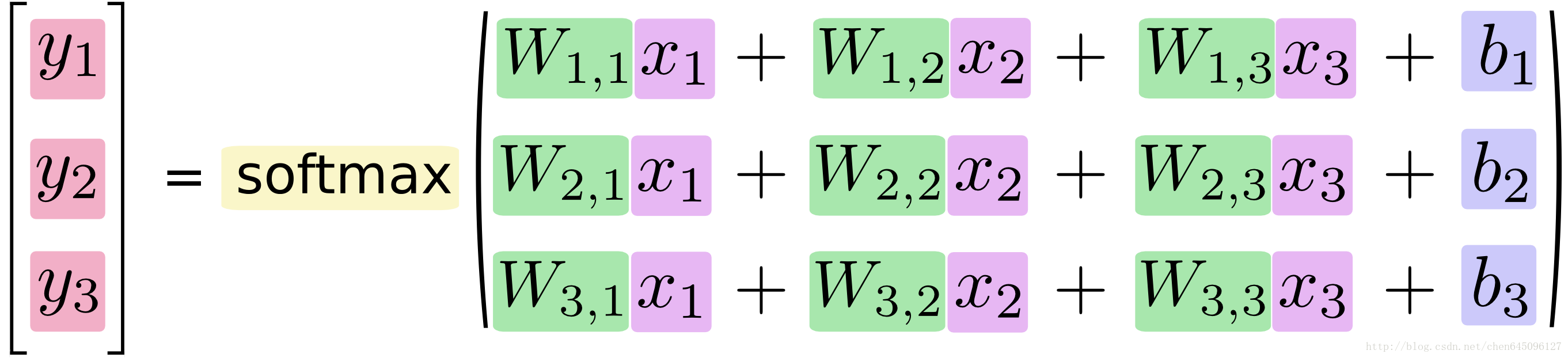
實際的計算中,我們通常採用向量計算的方式,如下:
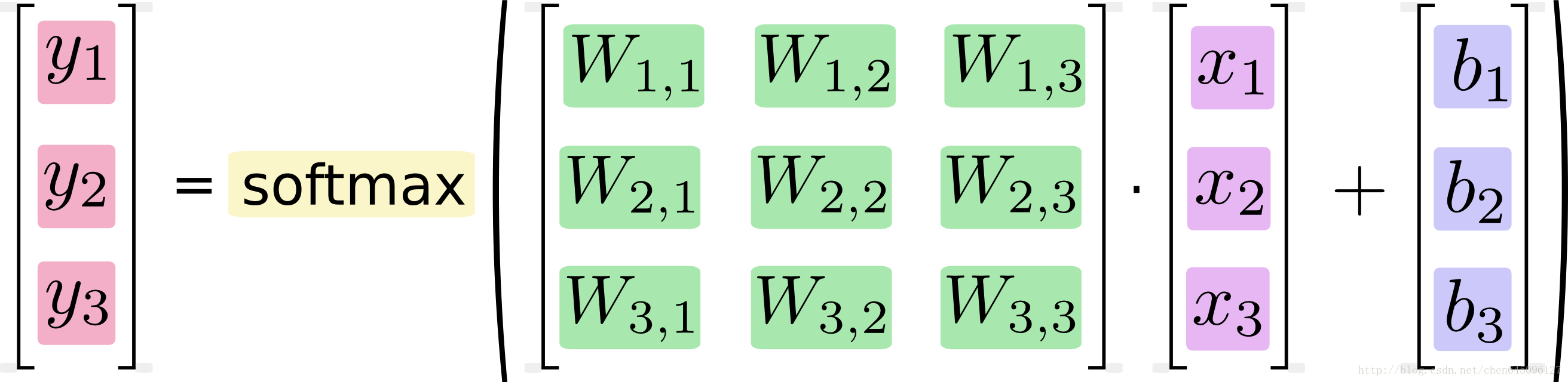
Softmax Regression的程式實現如下:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
#載入資料集
mnist = input_data.read_data_sets('MNIST_data',one_hot = True)
#每個批次100張照片
batch_size = 100
#計算一共有多少個批次
n_batch = mnist.train.num_examples // batch_size
#定義兩個placeholder
x = tf.placeholder(tf.float32,[None,784])
y = tf.placeholder(tf.float32,[None,10])
#建立一個簡單的神經網路,輸入層784個神經元,輸出層10個神經元
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
prediction = tf.nn.softmax(tf.matmul(x,W)+b)
#二次代價函式
# loss = tf.reduce_mean(tf.square(y-prediction))
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=prediction))
#使用梯度下降法
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
#初始化變數
init = tf.global_variables_initializer()
#結果存放在一個布林型列表中
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))
#求準確率
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
with tf.Session() as sess:
sess.run(init)
for epoch in range(11):
for batch in range(n_batch):
batch_xs,batch_ys = mnist.train.next_batch(batch_size)
sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys})
acc = sess.run(accuracy,feed_dict = {x:mnist.test.images,y:mnist.test.labels})
print("Iter " + str(epoch) + ",Testing Accuracy " + str(acc))
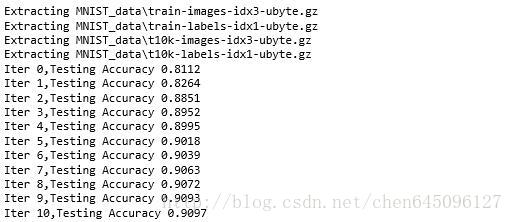
總結:該網路只有兩層(輸入與輸出),增加網路的深度準確率會增加,引數的初始化為‘0’,若改為隨機初始化也會增加準確率。。。