
caffe:cudaSuccess (2 vs. 0) out of memory
阿新 • • 發佈:2019-02-09
問題描述:
我試圖在Caffe上訓練一個網路。 我有512x640的影象大小。 批量大小是1.我試圖實現FCN-8s。
我目前在一個帶有4GB GPU記憶體的Amazon EC2例項(g2.2xlarge)上執行。 但是當我執行solver,它立即丟擲一個錯誤。
Check failed: error == cudaSuccess (2 vs. 0) out of memory
*** Check failure stack trace: ***
Aborted (core dumped)The error you get is indeed out of memory, but I guessed so. And yes, both train and test phases' batch size is 1. I think I have resize the training images to something smaller and try it out. But why is 4GB of GPU Memory turning out to be less space? It says The total number of bytes read was 537399810 which is much smaller than 4 當然也可以用cpu來計算,不過速度超慢,以下是我用cpu執行圖:
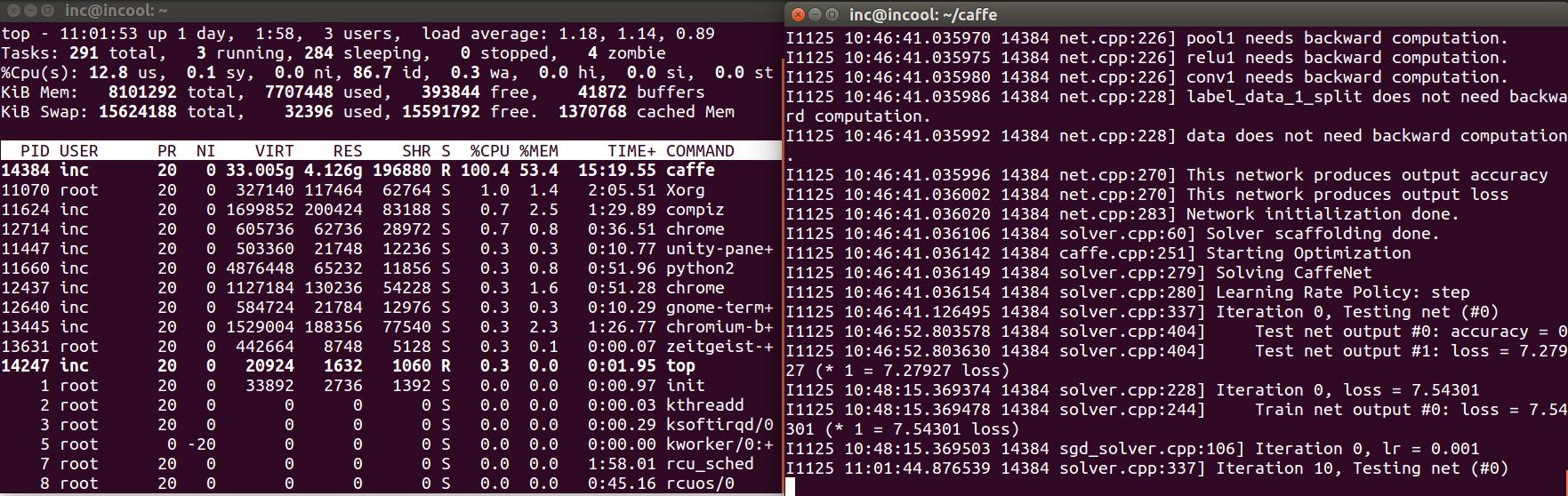
由圖中的時間可以看到cpu執行好慢。囧...