字串的模式匹配--BF演算法&KMP演算法
BF演算法是基於主串指標回溯,重新與子串進行逐字元進行比較,主串為S什麼要進行回溯呢,原因在於模式P中存在相同的字元或者說由字元(串)存在重複(模式的部分匹配性質),設想如果模式P中字元各不相同,主串就S的指標就根本不需要回溯;然而,我們可以發現在主串S與模式發生失配時,主串指標進行回溯會影響效率,因為由於模式S本身字元的部分部分匹配性質,回溯之後,主串S與模式T有些部分比較是沒有必要的,這就是對BF演算法所要改進的地方。
BF演算法的執行過程:
例:S =″aaaaaaaaaaab″
T =″aaab″
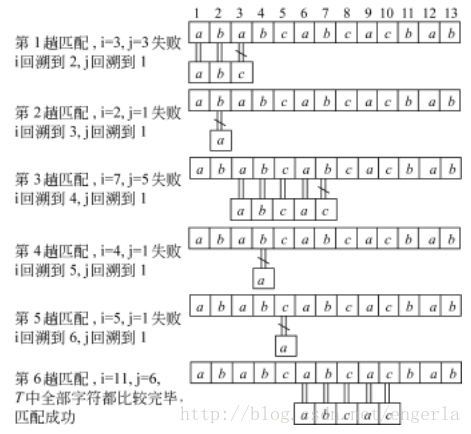
KMP演算法的執行過程:
例:S =″ababcabcacbab″
T =″abcac″
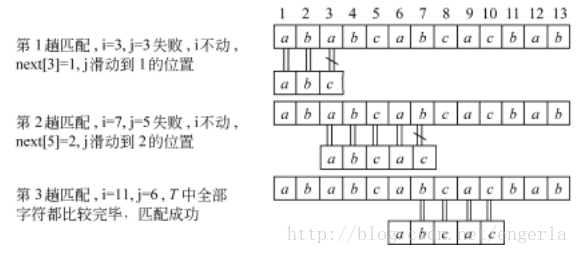
經過以上對比,我們可以發現KMP演算法的效率要比BF演算法的效率高,接下來看一下程式碼。
BF演算法
BF演算法思想
- 在串 S 和串 T 中分別設比較的起始下標 i 和 j;
- 迴圈直到 S 中所剩字元個數小於 T 的長度或 T 的所有字元均比較完
2 .1如果 S[i] = T [j] ,則繼續比較 S 和 T 的下一個字元 ;
2 .2 如果S[i] != T [j],將 i 和 j 回溯 ,準備下一趟比較 ;- 如果 T 中所有字元均比較完 , 則匹配成功 , 返回匹配的起始比較下標 ;
否則 ,匹配失敗 ,返回 0;
int KMP演算法
KMP的演算法中需要用到一個next陣列,該陣列是用來確定失配後模式串迴圈變數j回溯的位置的。
next陣列的計算
在“aba”中,字首是真字首的所有子串的集合,包括“a”、“ab”,除去最後一個字元的剩餘字串叫做真字首在“aba”中,真字首“ab”。同理,真字尾就是除去第一個字元的後面全部的字串。
next就是字首和字尾中相同的子串的最大長度
例如:
1. 在“aba”中,字首是“a”,字尾是“a”,那麼兩者相同子串最長的就是“a”,相同的子串的最的長度就是1;
2. 在“ababa”中,字首是“aba”,字尾是“aba”,二者相同子串最長的是“aba”,相同的子串的最的長度就是3;
3. 在“abcabcdabc”中,字首是“abc”,字尾是“abc”,二者相同子串最長的是“abc”,相同的子串的最的長度就是3;
這裡有一點要注意,字首必須要從頭開始算,字尾要從最後一個數開始算,中間截一段相同字串是不行的
next陣列的計算還有簡單的方法,上述使用最基礎的方法計算的,便於理解
KMP演算法思想
- 在串 S 和串 T 中分別設比較的起始下標 i 和 j;
- 迴圈直到 S 中所剩字元長度小於 T 的長度或 T 中所有字元均比較完畢
2 .1 如果 S[i] = T [j],則繼續比較 S 和 T 的下一個字元 ;
2 .2 如果S[i] != T [j],將 j 向右滑動到 next[ j] 位置 ,即 j = next[j] ;
2 .3 如果 j = 0 ,則將 i 和 j 分別加 1 ,準備下一趟比較;- 如果 T 中所有字元均比較完畢 , 則返回匹配的起始下標 ,否則返回 0;
此處next陣列使用一種簡單的方法計算的,此處就不過多解釋了,可以去網上學習一下,網上資源很多
//計算next的值
void getNext(String T, int next[]) {
int i;//迴圈變數
int k;
next[0] = -1;
for (i = 1; T.str[i] != '\0'; ++i) {
k = next[i - 1];
while (k != -1) {
if (T.str[i - 1] == T.str[k]) {
next[i] = k + 1;
break;
} else {
k = next[k];
}
}
if (k == -1) {
next[i] = 0;
}
}
}KMP演算法的匹配
int KMP(String S, String T, int next[]) {
int start = 0;
int i = 0;//主串的迴圈變數
int j = 0;//模式串的迴圈變數
while (i < S.length && j < T.length) {
if (S.str[i] == T.str[j]) {//若主串和模式串的字元相同,都向後移一位
i++;
j++;
} else {//若失配了,模式串的迴圈變數就要根據next陣列回溯
j = next[j];
if (j == -1) {
i++;
j++;//j=-1時,j必須要加1,否則下標越界導致執行出錯
}
}
}
if (j == T.length) {//判斷匹配是否成功
start = i - T.length + 1;
return start;
}
return -1;
}此外還需要做一些準備工作
#include <stdio.h>
#define MAX_SIZE 100
typedef struct {//定義一個字串的結構體
char str[MAX_SIZE];
int length;//字串的長度
} String;
//初始化
int initString(String *S) {
S->length = 0;
return 1;
}用main函式測試一下
int main() {
String S;//主串
String T;//模式串
initString(&S);//初始化
initString(&T);
createStr(&S);//從輸入字串
createStr(&T);
printf("----------BF&KMP----------\n");
BF(S, T, 0);
printf("----------KMP----------\n");
int next[T.length];
getNext(T, next);
for (int i = 0; i < T.length; ++i) {
printf("next[%d] = %d\t", i, next[i]);
}
printf("\n");
int start = KMP(S, T, next);
printf("\nstart position = %d\n", start);
return 0;
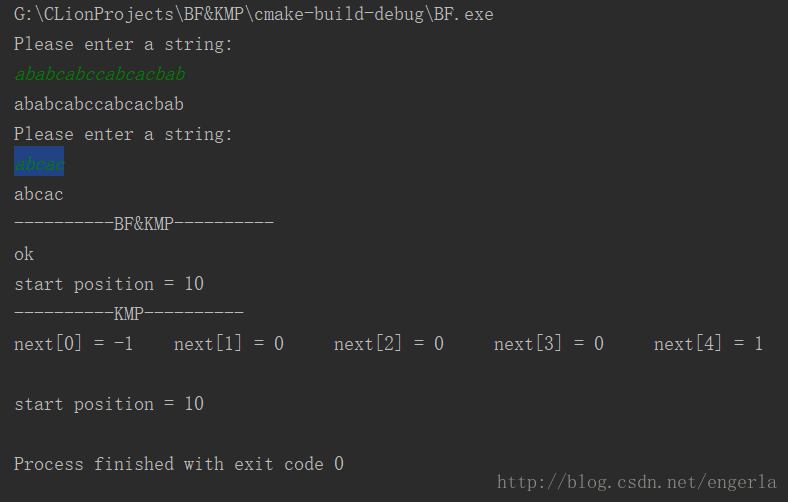
}例:
S = “ababcabccabcacbab”
T = “abcac”
執行結果: