
目標檢測模型的評價指標 mAP
在使用機器學習解決實際問題時,通常有很多模型可用。每個模型都有自己的怪癖(quirks),並且基於各種因素,效能會有所不同。
模型效能的評定都是在某個資料集上進行的,通常這個資料集被稱為 “validation 或 test” 資料集。模型效能的評價常用的指標有:accuracy、precision、recall等。這些指標的選擇需要根據應用場景具體而定。對於特定應用,使用合適的評價指標來客觀地比較不同模型的效能是非常重要的。
在本篇,我們將討論目標檢測問題中常用的評價指標 —– Mean Average Precision (mAP)。
一般來說,評價指標是很容易理解、計算的。例如,在二分類任務中,precision 和 recall 是最簡單、最容易想到的評價指標。但目標檢測與二分類任務不同。目標檢測不僅需要檢測有沒有目標,還需要檢測在哪裡,什麼類別。因此怎麼來定量地評價目標檢測系統的效能變得有點難度。
1. 目標檢測問題
要定量地評估一個目標檢測系統的效能,那你首先得知道目標檢測系統到底解決的問題是什麼?
目標檢測問題:給定一張影象,找出其中有哪些物體,給出物體的位置,以及類別(原文:Given an image, find the objects in it, locate their position and classify them)。
目標檢測模型訓練使用的資料集一般只有固定數量的類別,所以模型只能定位、分類影象中特定類別的物體。另外,目標檢測系統一般採用 矩形邊框 表示目標的位置。
下面的圖片展示了 “分類”、“分類+定位”、“目標檢測”、“例項分割” 四個任務的目的及區別。
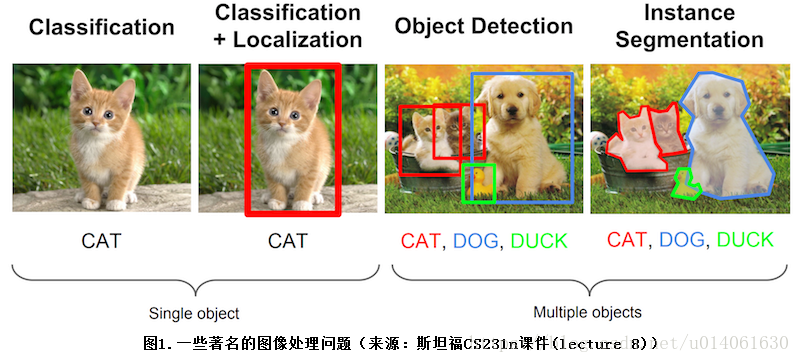
mAP 一般用於目標檢測演算法(需要同時檢出 目標的位置、類別)。當然,mAP 對於 “分類+定位”、“例項分割” 任務的模型的評估也非常有用。
2. 目標檢測模型的評估
2.1 為什麼選擇 mAP ?
在目標檢測中,每張圖片可能包含多個類別的多個目標。因此,目標檢測模型的評價需要同時評價模型的 定位、分類效果。
因此,在影象分類問題中常使用的 precision 指標不能直接用於目標檢測。這時 mAP 進入了人們的視野。我們希望你看完本篇文章後,知道 “什麼是 mAP” 及 “其代表的實際意義”。
2.2 什麼是 Ground Truth?
對於任何演算法,評估的過程其實就是 評估預測值與真實值的差距。我們只知道 訓練、驗證、測試集上的真實值(ground truth)。
對於目標檢測問題,ground truth 包括 “image”、“classes of the objects in it” 及 “true bounding boxes of each of the objects in that image”。
一個例子:

我們有實際的 image 及 annotations(bbox(x,y,w,h) 和 class)。
對這個特定的例子,我們的模型在訓練過程中可以利用的資訊有:

以及三組標記(假設影象的尺寸為 1000×800px,並且所有的位置是畫素級別的)。
| 類別 | x 座標 | y 座標 | 邊框寬度 | 邊框高度 |
|---|---|---|---|---|
| Dog | 100 | 600 | 150 | 100 |
| Horse | 700 | 300 | 200 | 250 |
| Person | 400 | 400 | 100 | 500 |
2.3 計算 mAP 的準備工作
目標檢測時,模型返回很多的 predictions,但是其中大多數有非常低的 confidence,因此我們只考慮 confidence 大於指定閾值的 predictions。
帶 bbox 的 image:

因為人類是目標檢測專家,所以我們能夠說這些檢測是正確的,但是我們該怎麼量化評估這些預測呢?
我們首先需要去判斷每個預測的正確性。(Intersection over Union)IoU 可以告訴我們每個預測 bbox 的正確性。IoU 是一個非常簡單、視覺化評價指標。
從 IoU 的字面來看,其的意思顯而易見,但是我們需要一個更加詳細的解釋。我將用一個簡單的形式解釋 IoU,如果想看更加詳細的解釋,Adrian Rosebrock 有一篇文章你可以參考。
2.3.1 什麼是 IoU?
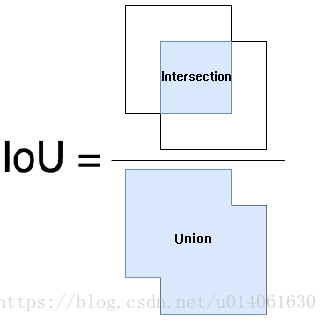
預測的邊框 和 真實的邊框 的交集和並集的比例 稱為 IoU(Intersection over Union)。這個指標又名 “Jaccard Index”,由 Paul Jaccard 在 19 世紀早期提出。
為了獲得 IoU 值,我們首先將預測邊框和真實邊框放在一張影象上(見下圖)。對於預測的,預測邊框和真實邊框的重疊區的面積是 intersection area,總面積是 union。

上圖中馬的 IoU 的計算方式如下:

Intersection 包含青色區域,Union 包含橙色和青色區域。
IoU 將按照如下方式計算:
2.3.2 什麼樣的預測時正確的?怎麼計算 precision 及 recall?
同其他機器學習問題一樣,為了計算 precision、recall,我們不得不去判定 True Positives (TP)、False Positives (FP)、True Negatives (TN)、False Negatives (FN)。
為了得到 TP、FP,我們使用 IoU 來判定預測結果是正確的還是錯誤的。最常用的 IoU 閾值是 0.5。如果 IoU 大於 0.5,則認為該預測是 TP,否則認為是 FP。COCO 評估指標建議使用不同的 IoU 閾值,但是為了簡單,我們假設閾值是0.5,這就是 Pascal VOC 資料集的評價指標。
為了計算 recall,我們需要統計 negatives 的數量。因為影象中沒有目標的區域都是 negative,故衡量 TN 是沒有意義的。所以我們只統計 FN(模型漏檢的目標)。
另一個需要被考慮的因素是模型檢測到的目標的 confidence。通過改變 confidence 閾值,我們能夠改變預測的 box 是否是正確的。基本上,高於閾值的所有預測(box + class)被認為是 positive boxes,低於閾值則為 negatives。
到目前為止,對於每一張圖片,我們有 ground truth
現在,我們計算 Ground Truth 和 模型預測的 Positive detection 的 IoU。基於設定的 IoU 閾值(這裡我們暫且設定IoU閾值為0.5),我們為每一張影象的各類目標計算正確檢測的數量(TP)。然後用其來為每一類計算 Precision ——— TP / (TP+FP)。
因為我們已經計算了正確檢出的數量(TP)、漏檢的數量(FP),因此我們可以為每一類計算 recall 了。
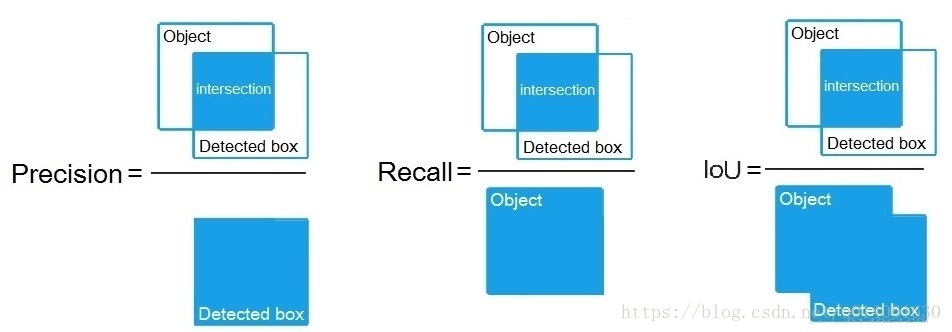
precision、recall、IoU 的區別:
只是分母不一樣而已!
2.4 計算 mAP
2.4.1 使用 Pascal VOC 挑戰賽的評估指標
mAP 其實有很多種不同的定義。這個指標通常用於資訊檢索、目標檢測領域。mAP 在不同領域,有不同的計算方法。我們在本篇將討論目標檢測領域 mAP 的計算方法。
目標檢測中 mAP 的使用需要追溯到 Pascal Visual Objects Classes challenge,該比賽包括了各種計算機視覺任務。關於該比賽的細節見 [link] (備份)
我們對於 precision 和 recall 的計算採用上節敘述的方法。
但是,正如上節介紹的一樣,有兩個影響 precision 和 recall 計算的變數(IoU 閾值、confidence 閾值)。
IoU 是一個簡單的幾何指標,其可以很容易被標準化,例如:VOC 挑戰賽評估指標基於 50% IoU 計算 mAP,然而 COCO 挑戰賽更進一步,計算 mAP 時使用的 IoU 閾值從 5%-95%。不同模型預測值的 confidence 可能不同,你的模型的 50% confidence 可能對應其他人模型的 80% confidence。這將改變 precision recall 曲線的形狀。因此 VOC 組織者想出了一個與模型無關的評價方式。
VOC 建議我們計算一個稱為 Average Precision(AP) 的指標:
對於給定的任務和類別,根據 “依據 IoU 排序後的預測” 來計算 precision / recall 曲線。AP 總結了 PR 曲線的形狀,AP 被定義為等間隔[0, 0.1, …, 1]的 recall 級別上 precision 的均值。
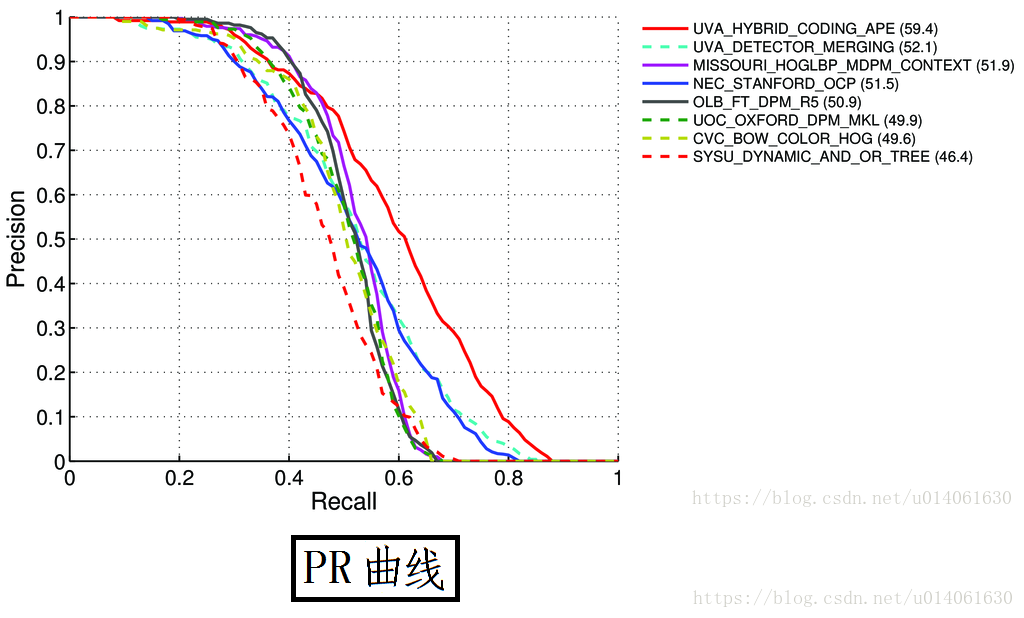
具體來講,我們選擇了 11 個不同的 IoU 閾值來得到 PR 曲線。AP 被定義為所選的 11 個 IoU 閾值對應的 Recall 值的 Precision 值的平均值。這使得 mAP 成為整個 PR 曲線的整體概括。
本文下來詳細介紹上面的計算中的 precision 的計算。
在每一個 recall 等級 r 的 precision 的計算方法為:在 recall 不超過 r 時,最大的 precision。
具體來說,對於給定的 recall 值,我們使用最大的 precision。
mAP 就是所有類別的 AP 的均值。
上面講述了 mAP 的計算。當然在某些情況下,mAP 的計算可能發生一些變化。例如,COCO 資料集使用的直接指標更加嚴謹(使用不同的 IoU 閾值 和 目標尺寸 more details here)。
當我們計算 mAP 值時,需要注意一些 “點”:
- mAP 的計算通常都是在一個數據集上計算的。
- 儘管很難去解釋模型的絕對效能,但 mAP 作為一個較好的相對指標,有助於評價模型。當我們在一些流行的公開資料集上計算該指標時,可以很容易地使用 mAP 去比較目標檢測新舊演算法的效能。
- 根據訓練集的類別分佈情況,不同類別的 AP 值可能會出現較大差異(訓練資料較好的類別有較高的 AP 值,訓練資料不好的類別有較低的 AP 值)。所以你的 mAP 可能是穩健的,但是你的模型可能對某些類別的效果較好,對於某些類別的效果不好。因此在分析模型時,建議去檢視下各類別的 AP 值。這些值可以作為新增訓練資料的一個參考指標。