
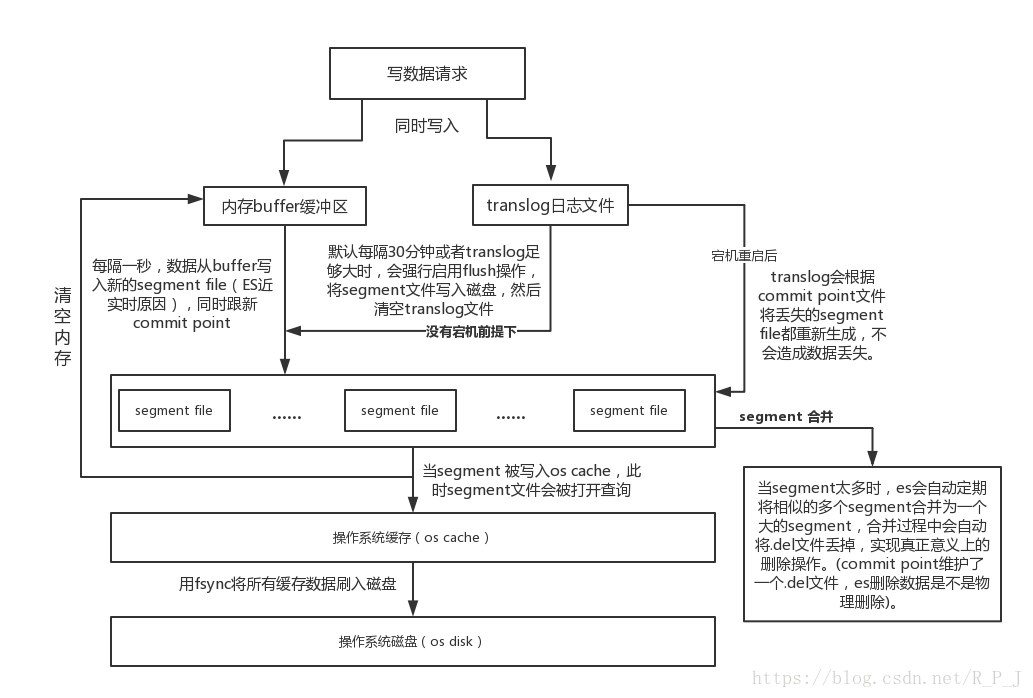
圖解elasticsearch的寫入流程
####elasticsearch寫入資料時涉及到的核心概念講解:
- segment file: 儲存倒排索引的檔案,每個segment本質上就是一個倒排索引,每秒都會生成一個segment檔案,當檔案過多時es會自動進行segment merge(合併檔案),合併時會同時將已經標註刪除的文件物理刪除;
- commit point(重點理解): 記錄當前所有可用的segment,每個commit point都會維護一個.del檔案(es刪除資料本質是不屬於物理刪除),當es做刪改操作時首先會在.del檔案中宣告某個document已經被刪除,檔案內記錄了在某個segment內某個文件已經被刪除,當查詢請求過來時在segment中被刪除的檔案是能夠查出來的,但是當返回結果時會根據commit point維護的那個.del檔案把已經刪除的文件過濾掉;
- translog日誌檔案: 為了防止elasticsearch宕機造成資料丟失保證可靠儲存,es會將每次寫入資料同時寫到translog日誌中(圖中會有詳解)。
####完整elasticsearch的寫入資料流程如下:
相關推薦
圖解elasticsearch的寫入流程
####elasticsearch寫入資料時涉及到的核心概念講解: segment file: 儲存倒排索引的檔案,每個segment本質上就是一個倒排索引,每秒都會生成一個segment檔案,當檔案過多時es會自動進行segment merge(合併檔案),
ElasticSearch最佳入門實踐(七十)優化寫入流程實現海量磁碟檔案合併(segment merge,optimize)
每秒一個segment file,檔案過多,而且每次search都要搜尋所有的segment,很耗時 預設會在後臺執行segment merge操作,在merge的時候,被標記為deleted的document也會被徹底物理刪除 每次merge
ElasticSearch最佳入門實踐(六十九)優化寫入流程實現durability可靠儲存(translog,flush)
(1)資料寫入buffer緩衝和translog日誌檔案 (2)每隔一秒鐘,buffer中的資料被寫入新的segment file,並進入os cache,此時segment被開啟並供search使用 (3)buffer被清空 (4)重複1~3,新的segment不斷新增,buf
ElasticSearch最佳入門實踐(六十八)優化寫入流程實現NRT近實時(filesystem cache,refresh)
現有流程的問題,每次都必須等待fsync將segment刷入磁碟,才能將segment開啟供search使用,這樣的話,從一個document寫入,到它可以被搜尋,可能會超過1分鐘!!!這就不是近實時的搜尋了!!!主要瓶頸在於fsync實際發生磁碟IO寫資料進磁碟,是很耗時的。
圖解Elasticsearch之一——索引建立過程
0、引言 這是國外培訓ppt課程的節選內容。 以下是我們的Core Elasticsearch:Operations課程中的一些很棒的幻燈片,它們有助於解釋分片分配的概念。 我們建議您更全面地瞭解這一點,但我會在此提供我們培訓的概述: 分片分配是將分片分配給節點的過程。 這可能發
2018.10.9 上線發現elasticsearch寫入速度超級慢,原來罪魁禍首是阿里雲服務的OSS的鍋
問題描述: 按照專案計劃,今天上線部署日誌系統(收集線上的所有日誌,便於問題排查)。 運維按照以前的部署過程,部署elasticsearch,部署結束之後,通過x-pack的monitor發現elasticsearch的索引速度只有幾百/秒的索引速度,遠遠小於同樣的配置,沒有做優化的另一個es叢集
elasticsearch 寫入優化
hold dice cal cluster ast int 數據 pre ber 全量dump數據時,為優化性能,可做如下優化。 分片設置,不分片 http://localhost:9200/test_index/_settings/ { "index": {
IOS圖解cookie使用流程
先看一張圖,清晰的解釋了cookie的使用流程,IOS開發中的程式碼也是根據這張圖的流程來進行的。概括來說就是這樣 HTTP請求,Cookie的使用過程 1、server通過HTTP Response中的"Set-Cookie: header"把cookie傳送給client 2、
圖解 Elasticsearch 原理
摘要 先自上而下,後自底向上的介紹ElasticSearch的底層工作原理,試圖回答以下問題: 為什麼我的搜尋 *foo-bar* 無法匹配 *foo-bar* ? 為什麼增加更多的檔案會壓縮索引(Index)? 為什麼ElasticSea
優化ElasticSearch寫入效率
最近在做日誌蒐集系統,涉及到Kafka到ES的資料解析寫入,但是Kafka的寫入效率遠遠高於ES,造成大量的資料在Kafka中積累,且ES的資料更新非常緩慢,最終造成了在Kibana中查詢的時候發現,ES中的資料有接近9個小時的資料延遲,這顯然是不可接受的。因此,必須著手優化ES的寫入效率。在儘可能不改
Elasticsearch寫入原理深入詳解
1、題記: Elasticsearch寫入流程,網上有視訊、筆記等各種版本,本文結合最新官方文件進行重新梳理,節省大家的時間。 思考如下幾個問題? 1、為什麼Elasticsarch是近實時,而不是準實時? 2、為什麼文件的CRUD操作是實時的? 3、為什麼Elastic
資料寫入流程解析
眾所周知,HBase預設適用於寫多讀少的應用,正是依賴於它相當出色的寫入效能:一個100臺RS的叢集可以輕鬆地支撐每天10T 的寫入量。當然,為了支援更高吞吐量的寫入,HBase還在不斷地進行優化和修正,這篇文章結合0.98版本的原始碼全面地分析HBase的寫入流程,全文分為
將 ELASTICSEARCH 寫入速度優化到極限
基於版本: 2.x – 5.x在 es 的預設設定,是綜合考慮資料可靠性,搜尋實時性,寫入速度等因素的,當你離開預設設定,追求極致的寫入速度時,很多是以犧牲可靠性和搜尋實時性為代價的.有時候,業務上對兩者要求並不高,反而對寫入速度要求很高,例如在我的場景中,要求每秒200w
JavaWeb 自動登入和退出(圖解程式碼執行流程)
自動登入 主要通過cookie和session的使用,實現自動登入 第一次登入執行流程 使用者第一次登入的時候,只要勾選自動登入功能,我們就生成一個cookie,並將使用者名稱和密碼儲存到cookie中存放到使用者的瀏覽器中 生成cookie的程式碼
RocksDB 寫入流程詳解
摘要: 最初的寫入流程,繼承自 leveldb,多個 寫執行緒組成一個 group, leader 負責 group 的 WAL 及 memtable 的提交,提交完後喚醒所有的 follwer,向上層返回。 支援 allow_concurrent_memtab
圖解Elasticsearch中的_source、_all、store和index屬性
Elasticsearch中有幾個關鍵屬性容易混淆,很多人搞不清楚_source欄位裡儲存的是什麼?store屬性的true或false和_source欄位有什麼關係?store屬性設定為true和_all有什麼關係?index屬性又起到什麼作用?什麼時候設定store屬性為true?什麼時候應該開啟_a
ElasticSearch寫入效能優化
背景: ES讀取檔案入庫速度比其它系統寫檔案速度慢,導致檔案大量堆積 ES入庫方式採取:python呼叫ElasticSearch的bulk介面實現資料的批量插入 嘗試的優化方案 方案一 建立更多的python子程序去讀取檔案
圖解 Elasticsearch
內容 圖解ElasticSearch 圖解Lucene 搜尋發生時 快取的故事 在Shard中搜索 如何Scale 一個真實的請求 參考 摘要 先
圖解SM2演算法流程(合)
A. SM2主要功能A.1. 公私鑰私鑰:BN_大整數公鑰:EC-Point橢圓曲線上的點整體結構A.2 第2部分——數字簽名演算法A.2.1 簽名(User A)l 簽名者使用者A的金鑰對包括其私鑰dA和公鑰PA=[dA]G= (xA,yA)l 簽名者使用者A具有長度為
ElasticSearch讀流程
基於版本:2.3.2 這次分析的讀流程指 GET/MGET 過程,不包含搜尋過程。 GET/MGET 必須指定三元組: index type id。 type 可以使用 _all 表示從所有 type 獲取第一個匹配 id 的 doc。 mget 時