
中文相似度匹配演算法
基於音形碼的中文字串相似度演算法
背景介紹
字串相似度演算法是指通過一定的方法,來計算兩個不同字串之間的相似程度。通常會用一個百分比來衡量字串之間的相似程度。字串相似度演算法被應用於許多計算場景,在諸如資料清洗,使用者輸入糾錯,推薦系統, 剽竊檢測系統,自動評分系統,以及網頁搜尋和DNA序列匹配這些方向都有著十分廣泛的應用。
常見的字串相似度演算法包括編輯距離演算法(EditDistance),n-gram演算法,JaroWinkler演算法以及Soundex演算法。本文接下來大略的介紹一下這幾種演算法,有興趣的讀者可以在網際網路找到一些更詳細的資料。
最常見的相似度演算法為編輯距離演算法(EditDistance),該演算法將兩個字串的相似度問題,歸結為將其中一個字串轉化成另一個字串所要付出的代價。轉化的代價越高,說明兩個字串的相似度越低。通常可以選擇的轉化方式包含插入,替換以及刪除。
N-Gram演算法則是基於這樣的一個假設: 即在字串中第n個詞的出現只與前面n-1個詞相關,而與其他任何詞都不相關,整個字串出現的概率就是各個詞出現的概率的乘積。 N-gram本身也代表目標字串中長度為n的子串,舉例,“ARM”在“ARMY”中,便是一個3-gram。當兩個字串中,相同的n-gram越多時,兩個字串就會被認為更加相似。
Jaro Winkler則是將n-gram演算法更進了一步。將n-gram中的不匹配的部分同時進行了換位的考慮,使得能獲得更準確的相似程度。JaroWinkler在比較兩個較短字串的情況下,能夠取得很好的結果。
Soundex演算法與前面幾種都不太相同。該演算法的特點是,它所關注的問題並非兩個字串文字上的相似程度,而是發音的近似。首先,該演算法會將兩個字串分別通過一定的hash演算法轉換成一個hash值,該值由四個字元構成,第一個字元為英文字母,後面三個為數字。進行轉化的hash演算法並非隨機選取,而是利用了該拉丁文字串的讀音近似值。
當獲得了兩個字串的讀音上的hash值之後,該演算法再對兩個hash的相似度進行計算,便可以得出輸入字串的讀音相似度。
Soundex演算法的另一個應用場景在於,使用者進行模糊查詢時,可以通過Soundex值進行過濾,以提高查詢效能。
問題描述
這些常見的字串相似度演算法在處理拉丁文字的文字匹配時,都能起到非常好的效果。它們本身最初的發明者也是為了解決拉丁文字中遇到的問題。然而,對於象形文字相似度計算,比如說中文,這些演算法就顯得捉襟見肘了。
舉例來說明:
南通市 – 難通市 – 北通市
對於編輯距離演算法而言,南通市和難通市之間的相似度,與南通市和北通市的相似度,是一模一樣的,因為兩者都需要付出相同的代價來轉換成另一個。 使用N-Gram演算法,得出的也是相同的結果。然而,對於熟悉漢字的人來講,南通市和難通市理應有著更加接近的相似度。因為兩者的發音完全相同。
既然是發音的問題,那麼有沒有可能利用Soundex演算法來解決呢? 目前看來,還是無法做到,因為Soundex演算法更多的是針對拉丁文字的發音,對於中文而言,Soundex演算法無能為力。
如果說這個例子僅僅說明是發音上的相同,拉丁文字也有相似的問題,那麼下面這個例子則描述了只存在於象形文字中的相似度問題:
彬彬有禮 – 杉杉有禮
如果站在解決拉丁文字的相似度的角度來看,那麼這兩個字串大約只有50%的相似度,因為在四個字元中,就有兩個字元是完全不同的。這兩個字元不僅外形不同,即使是發音,也是完全不同。
然而對於熟悉漢字的人來說,這兩個輸入應該有著相當高的相似度。因為第一個和第二個字元,雖然不同,卻有著十分接近的字形。
這樣的案例常常出現在錄入手寫輸入時,舉例來說,某個顧客填寫了一張快遞單:
江蘇省 南通市 紫琅路 100號
當快遞員簽收快遞時,可能需要在系統中錄入該地址,又或者,這家快遞公司採用的是先進的掃描器器,可以將地址通過掃描器掃入。假設顧客的字寫的十分潦草,那麼快遞員粗心大意或者不夠智慧的掃描器,都有可能導致下面的文字被錯誤的錄入:
江蘇省 南通市 紫娘路 100號
如何識別這樣的相似中文片語,在現有的演算法中,很難解決該問題。
中文的字串相似度有著其獨特的特徵,不同於其他任何語言,而在現實世界中,我們又卻是時常面臨這樣的問題,正如我們剛才看到的例子,其中最常見的場景便是中文糾錯。
我們急需要需找一種新型的演算法來解決該問題。
問題分析
想要解決中文字串的相似度匹配問題,並且量化中文相似度的結果,必須首先對單個漢字的特性有一定的瞭解。“琅“和“狼”的相似度,跟“琅”和“娘”之間的相似度比較,究竟哪個更高一些,量化的依據是什麼?“籃”和“南”呢?他們之間有相似之處麼?只有把這些問題都搞清楚了,我們才能設計出優秀的演算法,來計算中文字串之間的相似度。
經過長時間的調研和準備,在工作中不斷的思考總結遇到的中文相似度的問題,我們做出如下的總結,中文的相似度問題,主要歸結在三個方面。
同音字
漢字中的同音字可謂是外國人學習中文的一大難題,兩個截然不同的漢字,可能有著相同的發音。
當我們對兩個漢字進行相似度匹配時,發音的相同或是相近,應當在考慮之列。
對於同音字,如果僅僅考慮其發音的相似程度,那麼提供這樣的一個相似度演算法還是十分容易的,只需要現將漢字轉化成其對應的拼音,再進行傳統的相似度匹配演算法,譬如編輯距離演算法,即可達到很好的效果。
方言易混淆發音字
在中國的各個省市中,不同地區有著各自截然不同的方言。這也導致了一些口音很重的地區無法識別一些拼音之間的區別。
最常見的例子便是,許多南方人很難分別“L”和“N”,他們常常會將這兩個音弄混,將“籃球”讀作“南球”,而“劉德華”就變成了“牛德華”。
解決方言易混淆發音字的辦法和同音字的方法很相似,只需要在將漢字轉化成拼音之後,再對一些易混淆的音標再進行一次轉化,然後再去識別他們的相似度即可。
當然,也可以在計算近似度的時候,給易混淆音標設定一個相對較高的比值,也可以解決該問題。
還有些常見的易混淆音標包括:
“AN” – “ANG”
“Z” – “ZH”
“C” – “CH”
“EN” – “ENG”
字形相似
最後一種相似度問題,同時也是最難解決的問題,便是漢字字形上的相似。
漢字,作為世界上僅存的幾種象形文字之一,有著和世界主流使用的拉丁語系截然不同的表現形式。拉丁文字作為一種拼音文字,在於表音,即文字形態表示了它的發音。而象形文字,則是表意文字,一個漢字本身,便表達了它所隱含的意思。
在文章開篇中,我們所提到的所有相似度匹配演算法,都無法恰當的區分兩個不同漢字之間字形上的異同,更罔論計算他們的相似度了。
對於這個問題,一種樸素的思想,便是首先將漢字轉化成一組的字母數字的序列,而這個轉化所用到的hash演算法必須能夠將該漢字的字形特徵保留下來。利用這樣的轉化,我們便將漢字字形的相似度問題,變成了兩組字母數字序列的相似度問題。而這正是傳統相似度匹配演算法的強項。
這種解決方案的核心,就在於找到一個恰當的hash演算法,能夠將漢字進行適當的轉化,並在轉化結果中,保留住漢字的字形特徵。
在另一篇論文中,作者提到了使用一種名為四角編碼的漢字檢字法來實現這樣的演算法。四角演算法是由王雲五於1925年發明,這種編碼方式根據漢字所含的單筆或復筆對漢字進行編號,取漢字的左上角,右上角,左下角以及右下角四個角的筆形,將漢字轉化成最多五位的阿拉伯數字。 通過將漢字轉化成四角編碼,再對四角編碼的相似度進行計算,便可以得出兩個漢字在字形上的相似程度。
利用四角編碼計算漢字相似度,可以在一定程度上解決形近字的問題。
然而四角編碼也有其自身的問題,由於只取漢字的四角筆形,有些外形截然不同的漢字,因為四角結構相同,也擁有同樣的四角編碼。
舉例說明:
量 - 6010
日 - 6010
即使是從未學過中文的人,也能一眼看出這兩個字形上的差異,如果我們僅僅使用四角編碼,則會得出這兩個漢字相似度為100%的可笑結論。
綜合以上關於漢字相似度的三種問題,我們發現,每種解決方案都旨在解決整個問題集的的一個子集。這種分不同場景的做法,常常會造成使用者的困擾,因此,我們在想,是否存在一種方法,能夠將這三種解決方案合而為一,取其優點而去其缺點,一次性徹底解決中文的相似度問題?
這個問題引發了我的思考。
音形碼(SoundShape Code,SSC)
為了解決文章上面描述的問題,我在工作中積累相關經驗,並開發出了音形碼這一漢字編碼方式,來解決中文的相似度演算法問題。
首先,什麼是音形碼?音形碼是一種漢字的編碼方式,該編碼將一個漢字轉化成一個十位字母數字序列,並在一定程度上保留了該漢字的發音及字形的特徵。
下圖闡述了音形碼的序列中每一位的含義:
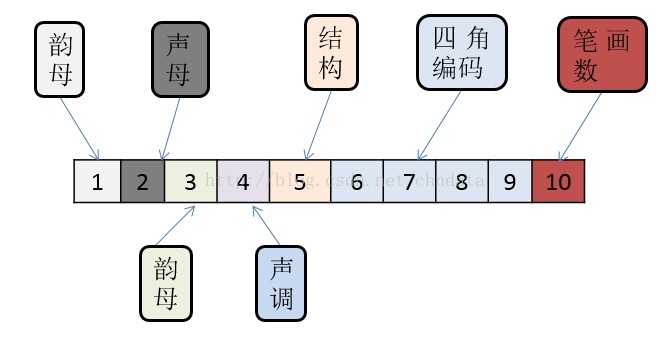
整個音形碼共分兩部分,第一部分是音碼部分,主要覆蓋了韻母,聲母,補碼以及聲調的內容。
第一位,是韻母位,通過簡單的替代規則,將漢字的韻母部分對映到一個字元位。漢字的拼音中一共有24種韻母,其中部分為了後期計算目的,採用相同的字元來替代,以下是一張完整的匹配表:

你會發現我們對於an和ang,所使用的是同一種轉化,目的便是為了再後期計算相似度的時候,將這種差異弱化。對於沒有這種需求的應用來說,完全可以自行生成對映表。
第二位是聲母位,同樣的,也是利用一張替換表來將聲母轉換成字元:

可以看到,z和zh用的也是相同的轉化。
第三位則是補碼,通常用於當聲母和韻母之間還有一個子音的時候,採用的是韻母表相同的替代規則。
第四位是聲調位,分別用1,2,3,4來替代漢字中的四聲。
第二部分是字形碼。
第一位被稱為結構位,根據漢字的不同結構,用一個字元來表示該漢字的結構。
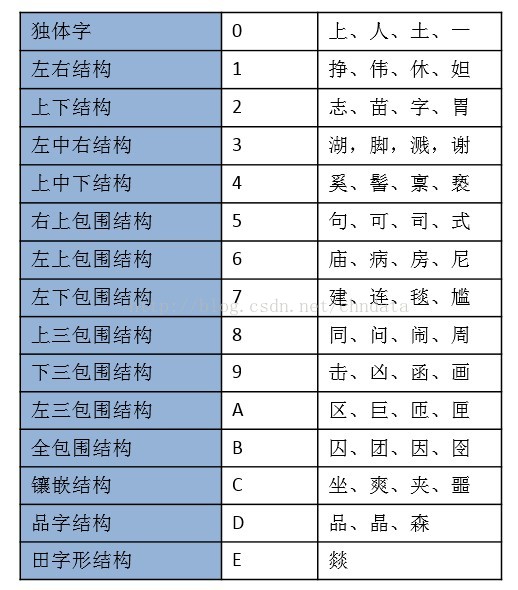
接下來的四位,則依然是借用了四角編碼,來描述該漢字的形態。由於四角編碼表過長,在這裡就不一一列舉了。
最後一位,是漢字的筆畫數位, 從一到九,分別代表該漢字的筆畫為一到九,接下來是A代表10位,B代表11位,並依次類推。 Z代表35位,以及任何超過35位的都用z。
舉例說明:漢字 “琅”,它的音形碼編碼是:

通過這樣的方式,將漢字首先轉換成了一系列的字元序列,這樣我們就可以採用一定的辦法,來計算他們的相似度。
單字相似度計算
對於單字的相似度匹配,我們採用了比較複雜的計算公式,以期獲得一個比較好的計算結果。

P代表音碼的相似度,S代表形碼的相似度,兩者各佔整個單字相似度的50%。
單獨拆解音碼相似度和形碼相似度:


這裡我重新定義了 和 的含義已適應該演算法,用於代表字元比較操作, 表示,若兩字元相同,則返回1,不同,則返回0. 表示,若倆字元相同,則返回1, 兩字元不同,則返回-1.
將兩個公式進行合併,便得到最終的計算單字相似度的演算法:

先看P部分,聲母部分佔據了整個音碼相似度的60%,補碼為30%, 而聲調部分為10%。於此同時,韻母部分對最終的相似度起到 的調整作用。
形碼部分的演算法很類似,四位四角編碼在形碼部分演算法中佔據相同的比重,而整個四角編碼在形碼部分中則佔據70%的比重,而筆畫數則佔據了30%的比重。最終,字形結構部分與韻母部分一致,起到了 的調整作用。
我們以“琅”,“狼”和“娘”三字舉例。
“琅”字的音形碼為:F70211313B
“狼”字的音型碼為:F70214323A
“娘”字的音型碼為:F74214343A
根據我們剛才所描述的演算法,可以得出,“琅”和“狼”的相似度為88.75%。 而“琅”和“娘”的相似度為83.75%
應用場景
單字相似度的計算並非十分有用,畢竟當兩個非常大的字串進行比較時,兩個字之間差異程度的細微差別,整體的相似度結果影響不是很大。
然而在某些場景下,諸如較短字串的比較,或者是中文糾錯的時候,單字相似度的演算法則可以起到非常大的作用。
舉例來說,使用者通過搜尋引擎來檢索一個短語:“紫娘路”, 而在搜尋引擎的詞庫中,並沒有能夠發現任何匹配的字串,相應的,找出了兩個與其類似的字串:
“紫琅路”
“紫薇路”
此時,目前的搜尋引擎系統無法區別出這兩個字串與使用者輸入哪個更加接近,因而無法向用戶做出更好的推薦。 相應的,使用本文描述的中文相似度演算法,便可以算出,“琅”和“狼”的相似度為88.75%(前文已得出)。 “娘”和“薇”(音形碼: 8K0114424G)的相似度為14.3%。由此可以得出,“紫琅路”與輸入資料較為接近。
另一種常見應用場景為,服務提供者擁有巨大的詞庫,使用者輸入一個錯誤資料之後,如何儘快的找出所有與其十分接近的詞。
在絕對匹配的情況下,做法通常為,為詞庫中的每一個詞,計算出一個hash值,再將hash-字串對插入到一張hash表中。當用戶輸入一個字串時,現將該字串的hash值計算出,再去表中進行匹配。
這種做法對於絕對匹配而言,效率很高,然而對於模糊查詢來說,則毫無用武之地。使用者只能一個字串一個字串的做相似度比較演算法,來選出最佳的結果。該演算法的時間複雜度則達到了O(n)。
為了解決這個問題,我們可以設計一種hash值的計算方法,使得相似的字串擁有相同的hash值,這樣當用戶的字串輸入時,就可以輕易的找到一群與之十分相似的字串,再對此進行一一比較,可以將效能提升到最大。只要演算法選取合適,效能甚至可以達到O(1)。
而這樣的方法就隱藏在音形碼的編碼當中。
對任意字串,取每一位字元的音形碼的第一位(韻母)和第五位(結構),拼成一個字串,作為該字串的hash值,通過這樣的方式,我們可以以下字串進行轉化:
“紫琅路”: 41GE5E
“紫娘路”: 41GE5E
“紫薇路”: 41815E
當用戶輸入“紫狼路”時,將會被轉化成:41GE5E,從而與“紫琅路”以及“紫娘路”的hash值一致。再通過更細節的比較,可以得出“紫琅路”為最優結果。
當然,不同的應用可以選取不同的音形碼的位數,來得到對應用最合適的hash值。這完全可以根據需求來定製化。
字串相似度計算
字串相似度的計算可以通過直接將字串中的每個漢字轉化為音形碼,再將所有音形碼合併起來進行EditDistance演算法比較,即可獲得。
因為中文的大字串的比較演算法,即使是EditDistance也可以得到較好的結果,在這裡就不詳細描述了,有興趣的讀者可以自行研究。
後續
整個演算法源於我在開發公司的某個實體解析的產品中總結的經驗,當時因為遇到這樣的問題,卻沒有很好的解決辦法。後來,在公司組織的程式設計馬拉松競賽中,我便選擇了這樣的課題來研究,並獲得了很好的結果。
該演算法還有著這樣那樣的缺陷,比如音形碼過長問題,字串錯位如何計算相似度等。但是我想,不能總等一切問題都解決再來做這些工作,而是一步解決一個問題的來不斷前進。因此也希望借用這篇文章,給大家一個啟發,為中文的相似度演算法做出自己的貢獻,那它的目的也就達到了。