
kmeans聚類演算法及matlab實現
一、kmeans聚類演算法介紹:
kmeans演算法是一種經典的無監督機器學習演算法,名列資料探勘十大演算法之一。作為一個非常好用的聚類演算法,kmeans的思想和實現都比較簡單。kmeans的主要思想:把資料劃分到各個區域(簇),使得資料與區域中心的距離之和最小。換個角度來說,kmeans演算法把資料量化為聚類中心,其目標函式就是使量化過程中損失的“資訊”最少。kmeans演算法求解目標函式的過程也可以看做是EM(Expectation maximization)迭代優化。
二、kmeans目標函式及優化:
定義:資料集
其中
迭代優化:未知變數是兩個矩陣–聚類中心
1、固定聚類中心
2、固定指示矩陣
從EM角度來看:把指示矩陣
三、判停標準:
kmeans演算法的迭代優化過程一直持續直到滿足某個判停標準,如果在這一輪迭代中:
1、訓練樣本所屬類別不再發生改變或者只有很少幾個訓練樣本改變;
2、目標函式變化很小或者聚類中心向量變化很小;
3、達到最大迭代次數。
滿足其中一個條件,即可停止訓練。如果滿足條件1或2,說明演算法已經收斂。
四、K值的選取:
隨著聚類數K的增大,目標函式呈減小趨勢。但是另一方面K值的增大會導致儲存空間和計算量的增加。那麼如何選擇合適的K值呢?
1.經驗法:根據問題的性質和先驗知識,人為指定聚類的數目。
2.爬山法:但當聚類數目到達一定值以後,聚類數目的增加目標函式的變化很小,這個拐點可以認為是最優聚類數目。
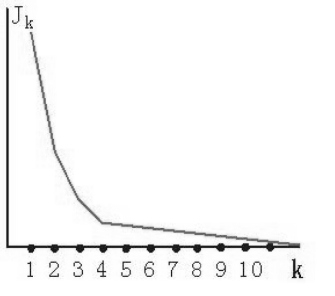
五、matlab計算資料與聚類中心之間的距離
matlab誕生的初衷就是為了矩陣運算的方便,所以如果用for迴圈來計算資料與聚類中心的距離從而得到指示矩陣
相關推薦
kmeans聚類演算法及matlab實現
一、kmeans聚類演算法介紹: kmeans演算法是一種經典的無監督機器學習演算法,名列資料探勘十大演算法之一。作為一個非常好用的聚類演算法,kmeans的思想和實現都比較簡單。kmeans的主要思想:把資料劃分到各個區域(簇),使得資料與區域中心的距
KMeans聚類演算法分析以及實現
KMeans KMeans是一種無監督學習聚類方法, 目的是發現數據中資料物件之間的關係,將資料進行分組,組內的相似性越大,組間的差別越大,則聚類效果越好。 無監督學習,也就是沒有對應的標籤,只有資料記錄.通過KMeans聚類,可以將資料劃分成一個簇,進而發現數據之間的關係.
機器學習-*-MeanShift聚類演算法及程式碼實現
MeanShift 該演算法也叫做均值漂移,在目標追蹤中應用廣泛。本身其實是一種基於密度的聚類演算法。 主要思路是:計算某一點A與其周圍半徑R內的向量距離的平均值M,計算出該點下一步漂移(移動)的方向(A=M+A)。當該點不再移動時,其與周圍點形成一個類簇,計算這個類簇與歷史類簇的距
kmeans聚類演算法及複雜度
kmeans是最簡單的聚類演算法之一,kmeans一般在資料分析前期使用,選取適當的k,將資料分類後,然後分類研究不同聚類下資料的特點。 演算法原理 隨機選取k箇中心點; 遍歷所有資料,將每個資料劃分到最近的中心點中; 計算每個聚類的平均值,並作為新的中心點; 重複
Kmeans聚類演算法及其matlab原始碼
本文介紹了K-means聚類演算法,並註釋了部分matlab實現的原始碼。K-means演算法K-means演算法是一種硬聚類演算法,根據資料到聚類中心的某種距離來作為判別該資料所屬類別。K-means演算法以距離作為相似度測度。假設將物件資料集分為個不同的類,k均值聚類演算
K均值聚類演算法的MATLAB實現
單來說,K-均值聚類就是在給定了一組樣本(x1, x2, ...xn) (xi, i = 1, 2, ... n均是向量) 之後,假設要將其聚為 m(<n) 類,可以按照如下的步驟實現: Step 1: 從 (x1, x2, ...xn) 中隨機選擇
K-means聚類演算法及其MATLAB實現
clear all;close all;clc; % 第一組資料 mu1=[0 0 ]; %均值 S1=[.1 0 ;0 .1]; %協方差 data1=mvnrnd(mu1,S1,100); %產生高斯分佈資料 %第二組資料 mu2=[1.25 1.25 ]; S2=[.1 0 ;0 .1]; da
Hadoop/MapReduce 及 Spark KMeans聚類演算法實現
package kmeans; import java.io.BufferedReader; import java.io.DataInput; import java.io.DataOutput; import java.io.File; import java.io.
模糊C均值聚類演算法及實現
模糊C均值聚類演算法的實現 研究背景 https://blog.csdn.net/liu_xiao_cheng/article/details/50471981 聚類分析是多元統計分析的一種,也是無監督模式識別的一個重要分支,在模式分類 影象處理和模糊
從零開始實現Kmeans聚類演算法
本系列文章的所有原始碼都將會開源,需要原始碼的小夥伴可以去我的 Github fork! 1. Kmeans聚類演算法簡介 由於具有出色的速度和良好的可擴充套件性,Kmeans聚類演算法算得上是最著名的聚類方法。Kmeans演算法是一個重複移動類中心
Scala語言實現Kmeans聚類演算法
/** * @author weixu_000 */ import java.util.Random import scala.io.Source import java.io._ object Kmeans { val k = 5 val dim = 41
NLP——Kmeans聚類演算法簡單實現
本例中主要是對二維點進行距離計算,開始得時候選取兩個心,最終聚為兩簇。 結束條件的判斷有很多種,這裡採用的是最簡單的:當兩個心不再變化了,則停止聚類。 內部距離和可以不需要計算,這裡輸出來做結果評估用。 public class Km_w2 { //初始
Kmeans聚類演算法在python下的實現--附測試資料
Kmeans演算法 1:隨機初始化一個聚類中心 2:根據距離將資料點劃分到不同的類中 3:計算代價函式 4:重新計算各類資料的中心作為聚類中心 5:重複2-4步直到代價函式不發生變化 測試資料: XY -1.260.46 -1.150.49 -1.190.36 -1.330
python實現簡單的kmeans聚類演算法
問題描述:一堆二維資料,用kmeans演算法對其進行聚類,下面例子以分k=3為例。 原資料: 1.5,3.1 2.2,2.9 3,4 2,1 15,25 43,13 32,42 0,0 8,9 12,5 9,12 11,8 22,33 24,25 實現程式碼: #codin
目錄:空間聚類演算法及時空聚類演算法
1.在本例項中,如果想將程式碼直接執行需注意以下幾點: Python版本3.X(本人使用的是Python 3.6) numpy版本 1.13.3(其他版本未實驗) scipy版本 0.19.1(其他版本未實驗) matplotlib版本 2.1.0(其他版本
影象基本變換---KMeans聚類演算法
本文將詳細介紹K-Means均值聚類的演算法及實現。 聚類是一個將資料集中在某些方面相似的資料成員進行分類組織的過程。K均值聚類是最著名的劃分聚類演算法,由於簡潔和效率使得他成為所有聚類演算法中最廣泛使用的。給定一個數據點集合和需要的聚類數目k,k由使用者指定,k均值
基礎演算法(二):Kmeans聚類演算法的基本原理與應用
Kmeans聚類演算法的基本原理與應用 內容說明:主要介紹Kmeans聚類演算法的數學原理,並使用matlab程式設計實現Kmeans的簡單應用,不對之處還望指正。 一、Km
數字影象去噪典型演算法及MATLAB實現
影象去噪是數字影象處理中的重要環節和步驟。去噪效果的好壞直接影響到後續的影象處理工作如影象分割、邊緣檢測等。影象訊號在產生、傳輸過程中都可能受到噪聲的汙染,一般數字影象系統中的常見噪聲主要有:高斯噪聲(主要由阻性元器件內部產生)、椒鹽噪聲(只要是影象切割引起的黑影象上的白點噪
KMeans聚類演算法
1、什麼是聚類 所謂聚類就是將一組物件按照特徵劃分不為的小組,使得組內的差異性儘可能的小,組間的差異儘可能的大。例如,粗粒度的分類,按照學校實力,分為985、211高校,普通一本高校,二本高校,三本高校。如果再更加細的分類,一個學校裡面會按照所修的課程差異性分為不同
聚類——譜聚類演算法以及Python實現
譜聚類(spectral cluster)可以視為一種改進的Kmeans的聚類演算法。常用來進行影象分割。缺點是需要指定簇的個數,難以構建合適的相似度矩陣。優點是簡單易實現。相比Kmeans而言,處理高維資料更合適。 核心思想 構建樣本點的相似度矩陣(圖