
XGBoost演算法解析和基於Scikit-learn的GBM演算法實現
1. 概要
Gradient Tree Boosting (別名 GBM, GBRT, GBDT, MART)是一類很常用的整合學習演算法,在KDD Cup, Kaggle組織的很多資料探勘競賽中多次表現出在分類和迴歸任務上面最好的performance。同時在2010年Yahoo Learning to Rank Challenge中, 奪得冠軍的LambdaMART演算法也屬於這一類演算法。因此Tree Boosting演算法和深度學習演算法DNN/CNN/RNN等等一樣在工業界和學術界中得到了非常廣泛的應用。
最近研讀了UW Tianqi Chen博士寫的關於Gradient Tree Boosting 的Slide和Notes, 牛人就是牛人,可以把演算法和模型講的如此清楚,深入淺出,感覺對Tree Boosting演算法的理解進一步加深了一些。本來打算寫一篇比較詳細的演算法解析的文章,後來一想不如記錄一些閱讀心得和關鍵點,感興趣的讀者可以直接看英文原版資料如下:
A. Introduction to Boosted Tree. https://xgboost.readthedocs.io/en/latest/model.html
B. Introduction to Boosted Trees. By Tianqi Chen. http://homes.cs.washington.edu/~tqchen/data/pdf/BoostedTree.pdf
C. Tianqi Chen and Carlos Guestrin. XGBoost: A Scalable Tree Boosting System. in KDD ‘16. http://www.kdd.org/kdd2016/papers/files/rfp0697-chenAemb.pdf
感覺資料B這個slide反倒比資料A Document講的更細緻一些,這個Document跳過了一些slide裡面提到的細節。這篇KDD paper的Section 2基本和這個Slide和Dcoument裡面提到的公式一樣。
2. 閱讀筆記 (註釋: 這部分摘錄的圖片出自Tianqi的slide,感謝原作者的精彩分享,我主要加上了一些個人理解性筆記,具體細節可以參考原版slide)
Tianqi的Slide首先給出了監督學習中一些常用基本概念的介紹,然後給出了Tree Ensemble 模型的目標函式定義

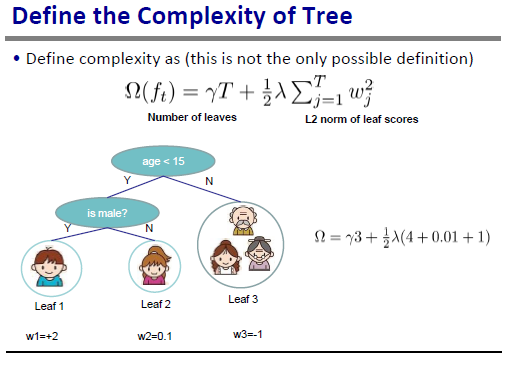
監督學習演算法的目標函式通常包括Loss和Regularization兩部分,這裡給出的是一般形式,具體Loss的定義可以是Square Loss, Hinge Loss, Logistic Loss等等,關於Regularization可以是模型引數的L2或者 L1 norm等等。 這裡針對Tree Ensemble演算法,可以用樹的節點數量,深度,葉子節點weights的L2 norm,葉子節點的數目等等來定義模型的複雜度。總體目標是學習出既有足夠預測能力又不過於複雜/過擬合訓練資料的模型。
給定模型目標函式,如何進行優化最小化cost得到最優模型引數? 這裡SGD就不適用了,因為模型引數是一些Tree Structure的集合而不是數值向量。我們可以用Additive Training (Boosting)演算法來進行訓練

因此模型的訓練分多輪進行,每一輪我們在已經學到的tree的基礎上嘗試新新增一顆新樹,這裡顯示了每一輪後預測值的變化關係。每一輪我們嘗試去尋找最可能最小化目標函式的tree f_t(x_i)加入模型。那麼如何尋找這樣的tree呢?先來分析一下目標函式:

如果是square loss,還是很容易展開成如上簡潔的形式。對於logistic loss等比較複雜的loss function的一般情形,我們可以使用泰勒展開式:

這張slide給出泰勒展開式後定義了g_i和h_i,分別是前一輪prediction loss對於前一輪的預測值的一階導數和二階導數。square loss下的目標函式形式可以視為這種泰勒展開形式下的特殊情形。我們可以把g_i,h_i帶入計算一下很快就可以發現。下面還有另一個問題,如何定義regularization term 呢?
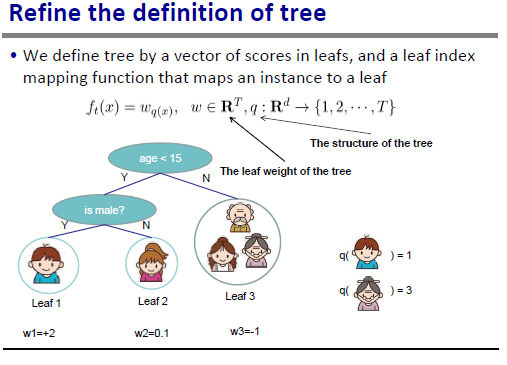
slide裡面解釋很清楚,還給出了具體例子。注意這裡q是一個把訓練example隱射到葉子節點index的函式。

於是可以帶入regularization term的定義,然後按照每個葉子節點上面的score重新group目標函式的計算,這個I_j是所有被對映到葉子節點j的example的集合。這樣重新group後我們更容易看出最值點和最優值:

這裡只用到了二次函式的最值點(-b/2a)和對應的最小值。當q(x)即樹的結構不變時,上面的slide給出了最優的葉子節點的weight和對應的目標函式值,這個目標函式值可以被視為給定q(x)可以達到的最小cost值,因此可以被用來evaluate一個樹的結構好不好。下面的slide給出了一個計算例項:

於是可以用如下演算法來搜尋最優的待新增樹

為了避免窮舉所有可能的樹結構,我們可以採用如下的貪心搜尋的策略:

對於某個feature,如何確定最佳split的點?可以先對examples按照feature值進行排序,然後對每一個可能的切分點計算Gain,選擇可以最大化Gain的切分點,然後對所有 d 個feature,所有K個level重複此過程。和決策樹的建樹演算法有點相通之處。


注意Gain的計算公式裡面的gamma是因為split後增加1個葉子節點導致的。公式裡面也可以看出最小化loss和最簡化模型中間的trade-off:

最後,總結以上所有目標函式定義,分析及其優化訓練過程就得到了Boosted Tree 演算法:

為了進一步加深對演算法的理解,徹底搞懂演算法所有細節,最好的方法還是效仿Tianqi那樣自己動手實現一下這個演算法,看最後一張slide這個演算法也沒有那麼複雜,但是估計實現過程還是有很多坑要踩的。
3. 基於XGBoost/Scikit-learn的實現
如果不想自己造輪子,有很多可用的開源實現,例如Scikit-learn就給出了包括Tree Boosting在內的各種supervise learning演算法的實現,下面給出一份例項code,總的來說Scikit-learn還是很全很好用的,因此也廣受歡迎。注意這只是一份示例code,我省去了從訓練資料測試資料中讀取對應X/y的code,有python基礎的讀者應該很容易加上。
- import numpy as np
- import sys
- # !skip code to read train/test data from files
- print‘read data…’
- X_train = np.nan_to_num(X_train)
- X_test = np.nan_to_num(X_test)
- print‘train data size: ’, len(X_train)
- print‘test data size: ’, len(X_test)
- # Data normalization
- #===================================================
- from sklearn import preprocessing
- # scale the data attributes
- scaler = preprocessing.MinMaxScaler().fit(X_train)
- X_train = scaler.transform(X_train)
- X_test = scaler.transform(X_test)
- print‘normalized_X: ’, X_train
- # Feature selection
- #===================================================
- from sklearn import metrics
- # from sklearn.ensemble import ExtraTreesClassifier
- # model = ExtraTreesClassifier()
- # model.fit(X_train, y_train)
- # # display the relative importance of each attribute
- # print(‘feature_importance’, model.feature_importances_)
- # Classification
- #===================================================
- # Build Model
- print‘build model…’
- #AdaBoost, LR, NeuralNet, SVM, RandomForest, Bagging, ExtraTrees
- if model_name == ‘LR’:
- from sklearn.linear_model import LogisticRegression
- model = LogisticRegression()
- elif model_name == ‘NeuralNet’:
- from sklearn.neural_network import MLPClassifier
- model = MLPClassifier(solver=’adam’, alpha=1e-5, activation=‘relu’,
- hidden_layer_sizes=(100, 100), random_state=1)
- elif model_name == ‘SVM’:
- from sklearn.svm import LinearSVC
- model = LinearSVC()
- elif model_name == ‘RandomForest’:
- from sklearn.ensemble import RandomForestClassifier
- model = RandomForestClassifier()
- elif model_name == ‘AdaBoost’:
- from sklearn.ensemble import AdaBoostClassifier
- model = AdaBoostClassifier()
- elif model_name == ‘GBRT’:
- from sklearn.ensemble import GradientBoostingRegressor
- model = GradientBoostingRegressor(n_estimators=1000, learning_rate=0.1, loss=‘ls’)
- elif model_name == ‘Bagging’:
- from sklearn.ensemble import BaggingClassifier
- model = BaggingClassifier()
- elif model_name == ‘ExtraTrees’:
- from sklearn.ensemble import ExtraTreesClassifier
- model = ExtraTreesClassifier()
- else:
- raise NameError(“wrong model name!”)
- from sklearn import metrics
- model.fit(X_train, y_train)
- print(model)
- # make predictions
- expected = y_test
- predicted = model.predict(X_test)
- # summarize the fit of the model
- print‘classification_report\n’, metrics.classification_report(expected, predicted, digits=6)
- print‘confusion_matrix\n’, metrics.confusion_matrix(expected, predicted)
- print‘accuracy\t’, metrics.accuracy_score(expected, predicted)
- print‘dump the predicted proba and predicted label to files in the folder ’, model_res_path
- predicted_score = model.predict_proba(X_test)
- predicted_label = predicted
- output_file_pred_score = model_res_path + data_name + ’_’ + model_name + ‘_’ + feature_set + ‘.pred_score’
- output_file_pred_label = model_res_path + data_name + ’_’ + model_name + ‘_’ + feature_set + ‘.pred_label’
- np.savetxt(output_file_pred_score, predicted_score, delimiter=’\t’)
- np.savetxt(output_file_pred_label, predicted_label, delimiter=’\t’)
- if model_name == ‘RandomForest’or model_name == ‘AdaBoost’or model_name == ‘GBRT’:
- print(‘feature importance score\n’)
- print(model.feature_importances_)
- feat_import_score_file = model_res_path + model_name + ’_’ + feature_set + ‘.featimportance’
- print(‘save feature importance file to the model_res_path: ’, feat_import_score_file)
- np.savetxt(feat_import_score_file, model.feature_importances_, delimiter=’\t’)
4 Reference
[1]. Introduction to Boosted Tree. https://xgboost.readthedocs.io/en/latest/model.html