
機器學習------批歸一化(Batch Normalization, BN)
阿新 • • 發佈:2019-02-11
取自孫明的"數字影象處理與分析基礎"
從字面意思上理解Batch Normalization就是對每一批資料進行歸一化,確實如此,對於訓練中某一個batch的資料{, , ……, },注意這個資料可以是輸入也可以是中間某一層的輸出,BN的前3步如下:
到這步為止就是一個標準的資料減均值除方差的歸一化流程。這樣的歸一化有什麼用呢?來看圖1定性瞭解一下。
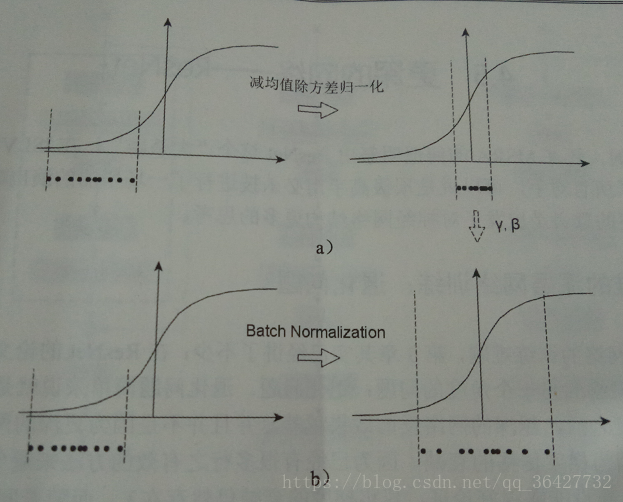
圖1中左邊是沒有任何處理的輸入資料,曲線是啟用函式的曲線,比入Sigmoid。如果資料在如圖1所示梯度很小的區域,那麼學習率就會很慢甚至陷入長時間的停滯。減去均值再除以方差之後,資料被移到中心區域,就是圖1中右邊的情況。對於大多數啟用函式而言,這個區域的梯度都是最大的或是有梯度的(比如ReLU),這可以看做是一種對抗梯度消失的手段。對於一層是如此,如果對於每一層資料都這麼操作,那麼資料的分佈就總是在隨輸入變化敏感的區域,相當於不用考慮資料分佈變來變去了,這樣訓練起來效率就高多了。不過到這裡問題並沒有結束,因為減均值除方差未必是最好的分佈。比如資料本身就不對稱,或者啟用函式未必是對方差為1的資料有最好的效果,比如Sigmoid啟用函式,在-1~1之間的梯度變化不大,那麼這樣非線性變換的作用有可能就不能很好體現。所以,在前面三步之後加入最後一步完成真正的Batch Normalization。
其中和是兩個需要學習的引數,所以其實BN的本質就是利用優化變一下方差大小和均值的位置,示意圖如圖1b所示。因為需要統計方差和均值,而這兩個值是在每個batch的資料上計算的,所以叫做Batch Normalization。當然訓練模型時,資料分佈的均值和方差應該儘量貼近所有資料的分佈,所以在訓練過程中記錄大量資料的均值和方差,得到整體;樣本的均值和方差的期望值,訓練結束後作為最後使用的均值和方差。
注意前面寫的都是對於一般情況,對於卷積神經網路有些許不同。因為卷積神經網路的特徵是對應到一整張特徵相應圖的,所以做BN的時候也是以響應圖為單位,而不是按照各個維度。比如在某一層,batch大小為