
如何訓練非平衡資料的分類器
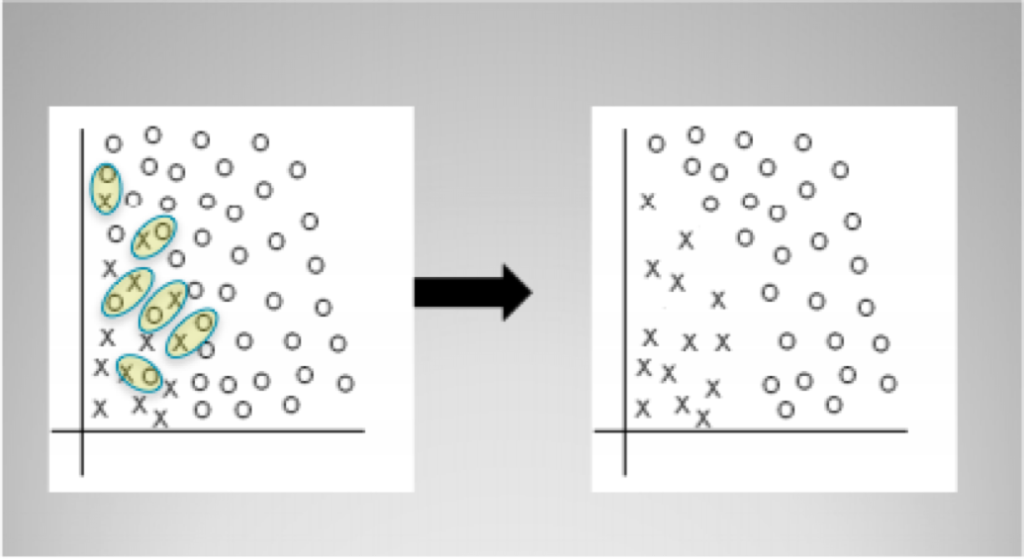
訓練一個分類器,第一步就是為每個類別準備大量資料。這一個看似簡單,在實際中往往卻最難達到理想情況。因為:實際中很多分類任務的資料不是平衡的,即類與類之間的數量懸殊,例如對磁碟進行故障預測分類,然而磁碟故障率每年小於1%,於是理想和現實如同如下左、右圖那樣。
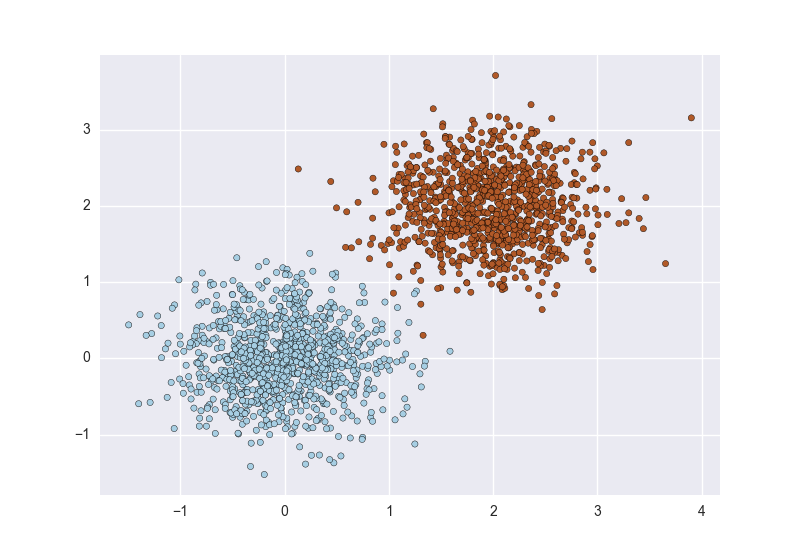
有很多學者對這種非平衡資料的分類問題進行了研究,總的來說,以下是解決這個問題的主要方法:
1. 不做任何事情,在這樣自然分佈的資料下坐等訓練結果;
2. 對少數量的類進行上取樣,對大數量的類進行下采樣,或給少數量的類加入一些新的合成數據;
3. 不考慮少數量的型別,把問題轉化為“異常檢測”解法;
4. 做些演算法上的優化,如給損失函式加權重控制、調整決策閾值、或是對演算法做些修改使得對少量資料的類更敏感。
5. 設計一個新的演算法。
在闡述具體方法前,我們來談談如何評價分類的效能,要注意以下幾點:
1. 通過ROC來評價,不要就在某個閾值下討論演算法的效果,應該根據實際應用上的條件來尋找ROC曲線上最佳的值。
2. 要在“自然”分佈的資料集上對演算法進行測試驗證 (sklearn.cross_validation.StratifiedKFold)。
3. 可以用The Area Under the ROC curve (AUC) 、F1-score、Cohen’s Kappa 進行單指標評價。
下面,具體來看以上談到的幾個方法:
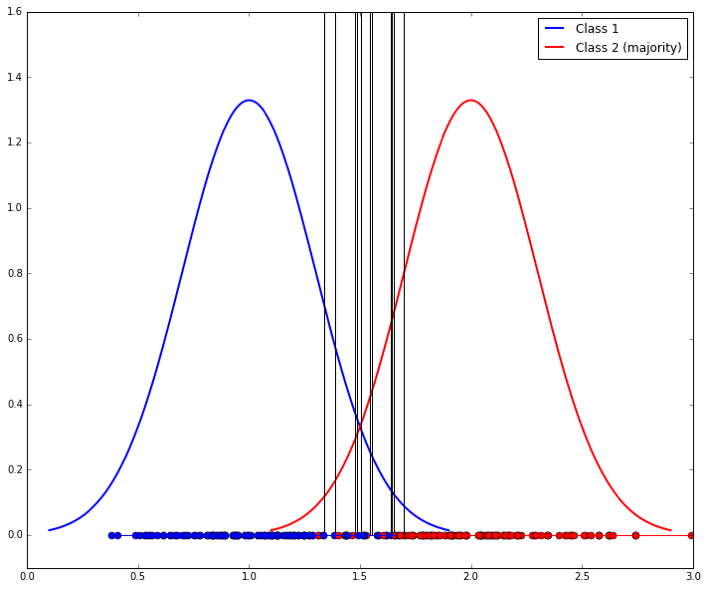
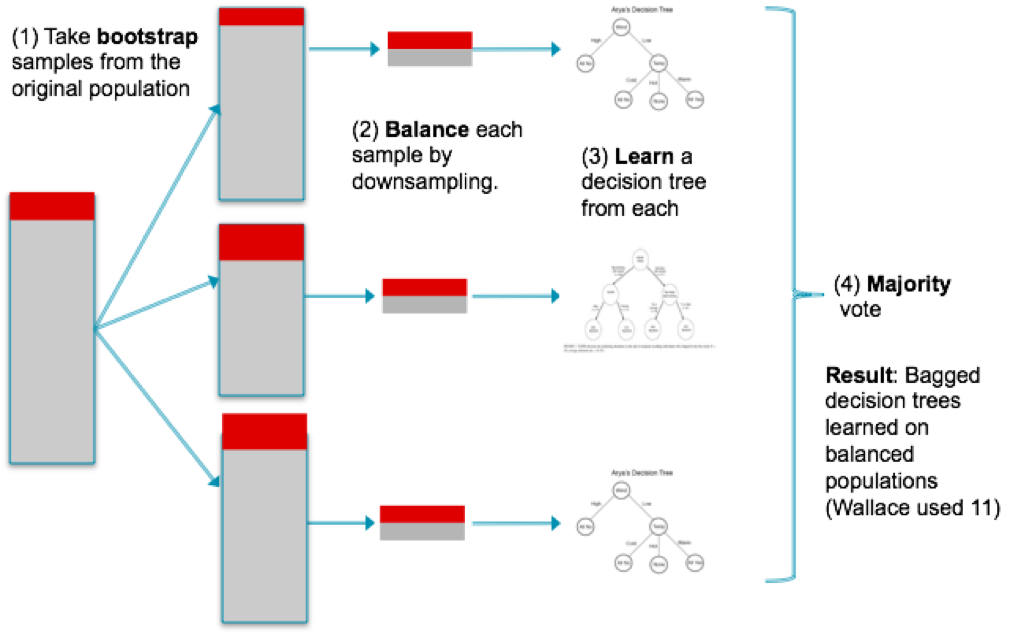
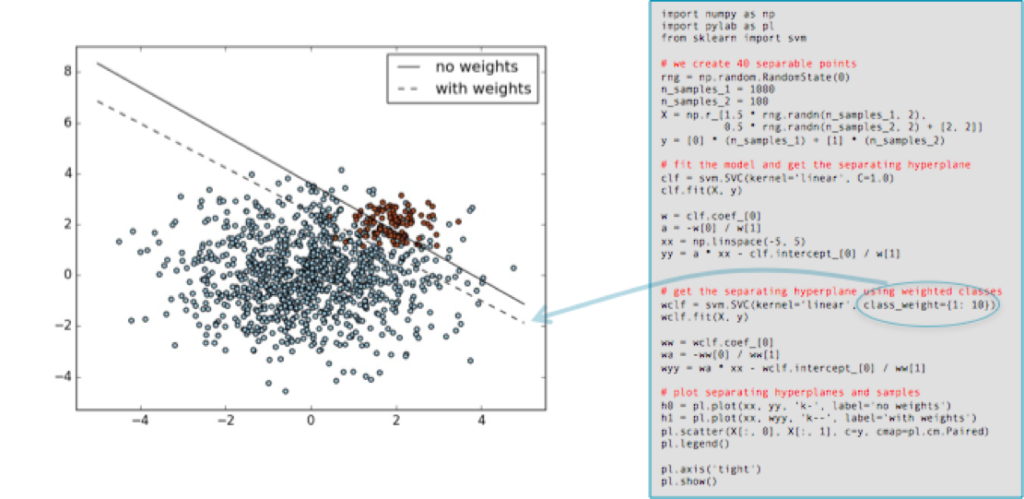
1. 關於上、下采樣。上取樣可以放大錯誤,但也有副作用,它會讓變數的方差過小;而下采樣會讓獨立變數有更大的方差,如下圖,由於樣本少,使得分類變得方差較大(10個不同的取樣導致10個不同的分類器),如下圖左。於是,可以用bagging的方法來避免,如下圖右。
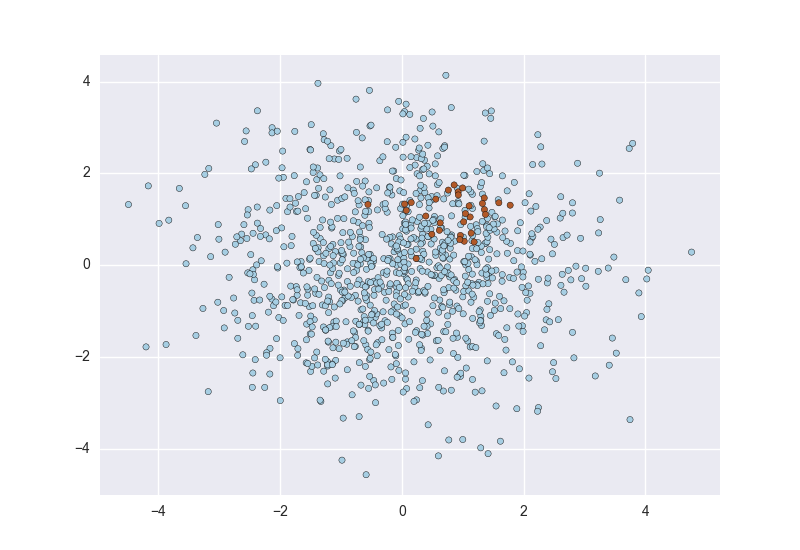
2. 用鄰域連結的方法來進行下采樣: TomekLink。 如下圖,該演算法通過將少量資料類的樣本附近的一個大量資料類的樣本進行刪除來實現。
5. 還有一些不錯的演算法。比如Box Drawings for Learning with Imbalanced Data 方法解決了資料傾斜下的訓練問題。 該演算法在少量樣本聚類中心周圍構建box,基於此獲得了少量資料類的一種簡潔智慧的表達。在訓練時,box的數量作為一種懲罰,同時也作為正則項。Exact Boxes和Fast Boxes是兩種訓練方法。
6. 將問題看作“異常檢測”,效果比較不錯的是:Isolation-Based Anomaly Detection, 它通過學習一個隨機森林並獲得分割每個點的決策面的個數,這個個數可以衡量對應點的異常分數。
7. 最後,通過社會化眾包發現數據也是很多公司採用的方法。
8. 模型級聯。 EasyEnsemble and BalanceCascade (Exploratory Under Sampling for Class Imbalance Learning). 這是個迭代清洗資料獲得多個模型的演算法。首先從整體訓練集中取樣獲得大類的子集M1,使得數量和小類S相當,然後用M1+S訓練獲得分類器H(1)。 獲得H(1)分類結果中分類正確的M1的子集M11, 認為M11是M1的冗餘,並從整體訓練集中刪去。接著重複同樣的步驟,取樣->訓練->刪冗餘,迭代直至無法獲得更好的結果。然後把所有模型級聯起來進行分類。
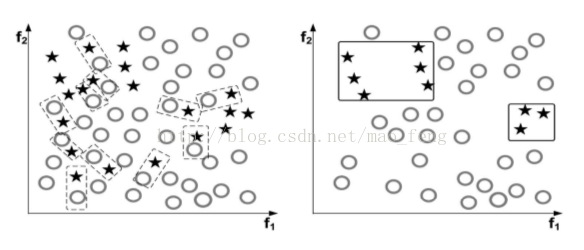
9. one-sided selection (OSS). 這個是清洗資料使得更有利於訓練的方法。它也是迭代進行的。每次獲得Tomek links,即當不存在例項使得其到大類Xm和小類Xs的距離小於Xm和Xs之間的距離,則認為(Xm,Xs)是一個Tomek link. 屬於Tomek link的兩個例項,要麼是噪聲點,要麼是類間的邊界。如下圖,左邊虛線矩形框出了Tomek links, 右邊是清理後的資料集。
原文連線: http://www.svds.com/learning-imbalanced-classes/#fn6