Python爬蟲入門——2. 5 爬取鬥破蒼穹並儲存到本地TXT
話不多說,上程式碼:
#匯入requests庫 import requests #匯入 re 庫 #匯入時間模組 import time import re #定義請求頭,請求頭可以使爬蟲偽裝成瀏覽器 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'} #定義連線網路的列表 url_list = ['http://www.doupoxs.com/doupocangqiong/{}.html'.format(str(i)) for i in range(2,1665) ] #函式主體 with open('F:/exercise/鬥破蒼穹.txt', 'w') as f: for url in url_list: html = requests.get(url, headers = headers) #如果status_code = 200, 說明網頁相應成功 if html.status_code == 200: #利用正則表示式獲取內容 contents = re.findall('<p>(.*?)</p>', html.content.decode('utf-8'), re.S) #將內容寫入到本地txt文件 f.write('\n\n') for content in contents: f.write(content+'\n') else: pass time.sleep(0.5)
現在來分析程式碼:
1.匯入requests庫、time模組、re 模組、定義請求頭
2.構造ur連線列表http://www.doupoxs.com/doupocangqiong/ { }.html 區間為[2,1665) 左閉右開,其中3,4網頁為404
3.在本地建立一個TXT檔案,命名為 ”鬥破蒼穹.txt“ 。利用with 語句來進行檔案的 寫 操作。
3.1利用 with 語句 開啟 open 路徑為 “F:/exercise/鬥破蒼穹.txt”的檔案,“w”為寫操作。
3.2利用 for 迴圈讀入 URL ,利用requests讀取網頁內容
3.3.判斷是否成功連線網頁,如果成功連線網頁則:
3.3.1利用正則表示式獲取文章內容。注意,我們獲得的是非utf-8編碼,因此在這裡我們多了一個步驟,就是將獲取到的內容轉換為utf-8編碼。你可以將 html.content.decode('utf-8) 更換為 html.text 列印一小部分內容觀察一下。
3.3.2在文字寫入兩行空格,用來區分章節。
3.3.3迴圈讀入獲取到的內容,將其寫入文字中
3.4如果連線失敗,那麼就pass吊此次迴圈,進入下一個迴圈。
3.5讓程式休息0.5秒,防止一直在執行,頻率過高從而導致爬蟲失敗。
檔案操作:
開啟檔案進行操作之後需要將開啟的檔案關閉。否則會一直佔用資源。但有時程式出現問題,導致開啟的檔案不能正常關閉,所以我們會用 try... finally來進行檔案的操作。但是這樣未免顯得繁瑣。所以 Python引入了 with 語句來自動關閉 close 檔案。用法是 with open(“path”,‘identifier’)as f 其中path指的是檔案的路徑,包括檔名;‘identifier’ 是識別符號,表示的是對檔案進行何種操作: ‘r' 表示讀檔案: ’w' 表示寫檔案: ‘rb’ 表示讀取二進位制檔案(比如圖片,視訊等)。
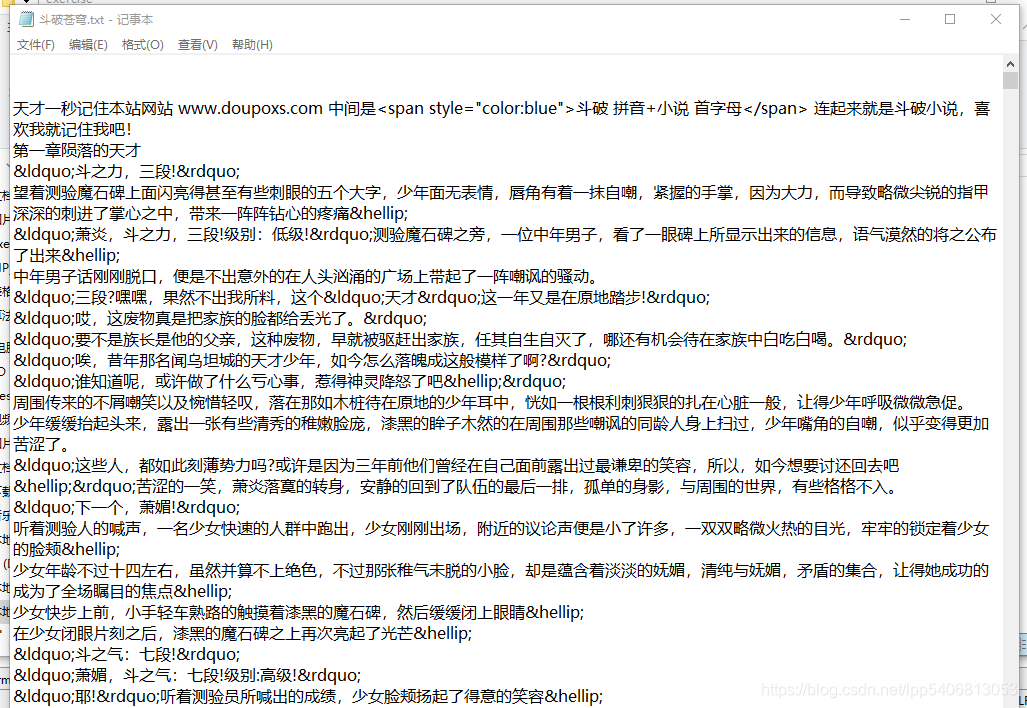
下圖為成功讀取儲存的《鬥破蒼穹》文字文件: