
Spark學習之11:Shuffle Read
阿新 • • 發佈:2019-02-11
本文描述ShuffleMapTask執行完成後,後續Stage執行時讀取Shuffle Write結果的過程。涉及Shuffle Read的RDD有ShuffledRDD、CoGroupedRDD等。
發起Shuffle Read的方法是這些RDD的compute方法。下面以ShuffledRDD為例,描述Shuffle Read過程。

一個Reduce依賴所有的Map,每個Map都會輸出一份資料到每一個Ruduce。可以理解為,有多少個Map,一個Reduce就對應多少個Block。 首先,需要通過呼叫MapOutputTracker.getServerStatuses獲取reduce對應的Blocks所在的節點以及每個Block的大小。
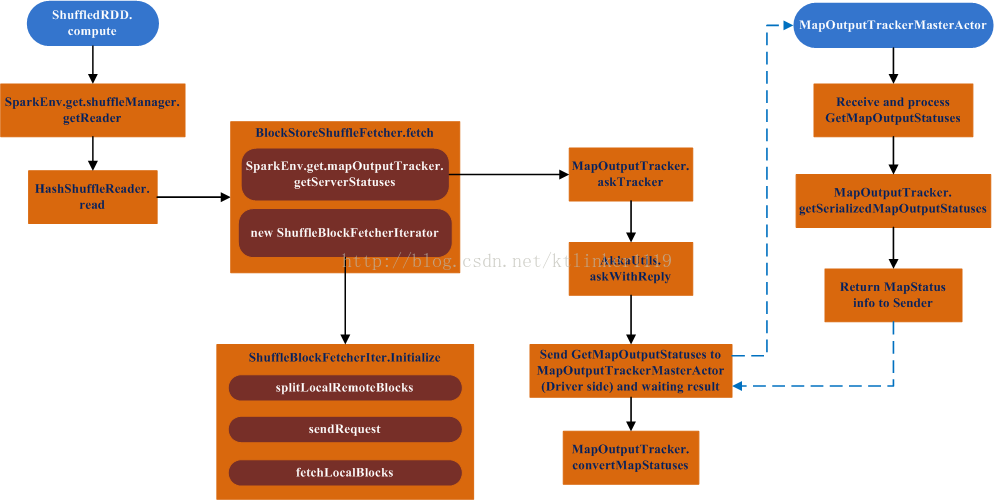
0. 流程圖
1. 入口函式
Shuffle Read操作的入口是ShuffledRDD.compute方法。(1)通過SparkEnv獲取ShuffleManager物件,它兩個實現HashShuffleManager和SortShuffleManager,這個兩個實現的getReader方法都返回HashShuffleReader物件; (2)呼叫HashShuffleReader的read方法。 (3)compute方法返回的是一個迭代器,只有在涉及action或固化操作時才會具體執行使用者提供的操作。override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = { val dep = dependencies.head.asInstanceOf[ShuffleDependency[K, V, C]] SparkEnv.get.shuffleManager.getReader(dep.shuffleHandle, split.index, split.index + 1, context) .read() .asInstanceOf[Iterator[(K, C)]] }
1.1. HashShuffleReader.read
(1)BlockStoreShuffleFetcher是一個object,只有一個方法fetch,根據shuffleId和partition來獲取對應的shuffle內容;fetch方法返回一個迭代器,遍歷次迭代器就可以獲取對應的資料記錄; (2)後面是依據不同的條件,構造不同的迭代器,比如是否要合併,排序等。 注:這裡mapSideCombine的操作和Shuffle Write時呼叫的方法是不同的。 write時呼叫:combineValuesByKey; read時呼叫:combineCombinersByKey。override def read(): Iterator[Product2[K, C]] = { val ser = Serializer.getSerializer(dep.serializer) val iter = BlockStoreShuffleFetcher.fetch(handle.shuffleId, startPartition, context, ser) val aggregatedIter: Iterator[Product2[K, C]] = if (dep.aggregator.isDefined) { if (dep.mapSideCombine) { new InterruptibleIterator(context, dep.aggregator.get.combineCombinersByKey(iter, context)) } else { new InterruptibleIterator(context, dep.aggregator.get.combineValuesByKey(iter, context)) } } else { require(!dep.mapSideCombine, "Map-side combine without Aggregator specified!") // Convert the Product2s to pairs since this is what downstream RDDs currently expect iter.asInstanceOf[Iterator[Product2[K, C]]].map(pair => (pair._1, pair._2)) } // Sort the output if there is a sort ordering defined. dep.keyOrdering match { case Some(keyOrd: Ordering[K]) => // Create an ExternalSorter to sort the data. Note that if spark.shuffle.spill is disabled, // the ExternalSorter won't spill to disk. val sorter = new ExternalSorter[K, C, C](ordering = Some(keyOrd), serializer = Some(ser)) sorter.insertAll(aggregatedIter) context.taskMetrics.incMemoryBytesSpilled(sorter.memoryBytesSpilled) context.taskMetrics.incDiskBytesSpilled(sorter.diskBytesSpilled) sorter.iterator case None => aggregatedIter } }
2. BlockStoreShuffleFetcher
一個Shuffle Map Stage會將輸出寫到多個節點。由於多個ShuffleMapTask在同一節點執行,每個Task建立各自獨立的Blocks,Blocks的數量取決於Reduce的數量(shuffle輸出分割槽個數),因此一個reduce(一個分割槽)在一個節點上可能對應多個Block。 Map和Reduce關係示意圖:一個Reduce依賴所有的Map,每個Map都會輸出一份資料到每一個Ruduce。可以理解為,有多少個Map,一個Reduce就對應多少個Block。 首先,需要通過呼叫MapOutputTracker.getServerStatuses獲取reduce對應的Blocks所在的節點以及每個Block的大小。
def fetch[T](
shuffleId: Int,
reduceId: Int,
context: TaskContext,
serializer: Serializer)
: Iterator[T] =
{
logDebug("Fetching outputs for shuffle %d, reduce %d".format(shuffleId, reduceId))
val blockManager = SparkEnv.get.blockManager
val startTime = System.currentTimeMillis
val statuses = SparkEnv.get.mapOutputTracker.getServerStatuses(shuffleId, reduceId)
......
}2.1. MapOutputTracker. getServerStatuses
MapOutputTracker類定義了一個數據結構: protected val mapStatuses: Map[Int, Array[MapStatus]] def getServerStatuses(shuffleId: Int, reduceId: Int): Array[(BlockManagerId, Long)] = {
val statuses = mapStatuses.get(shuffleId).orNull
if (statuses == null) {
logInfo("Don't have map outputs for shuffle " + shuffleId + ", fetching them")
var fetchedStatuses: Array[MapStatus] = null
fetching.synchronized {
// Someone else is fetching it; wait for them to be done
while (fetching.contains(shuffleId)) {
try {
fetching.wait()
} catch {
case e: InterruptedException =>
}
}
// Either while we waited the fetch happened successfully, or
// someone fetched it in between the get and the fetching.synchronized.
fetchedStatuses = mapStatuses.get(shuffleId).orNull
if (fetchedStatuses == null) {
// We have to do the fetch, get others to wait for us.
fetching += shuffleId
}
}
if (fetchedStatuses == null) {
// We won the race to fetch the output locs; do so
logInfo("Doing the fetch; tracker actor = " + trackerActor)
// This try-finally prevents hangs due to timeouts:
try {
val fetchedBytes =
askTracker(GetMapOutputStatuses(shuffleId)).asInstanceOf[Array[Byte]]
fetchedStatuses = MapOutputTracker.deserializeMapStatuses(fetchedBytes)
logInfo("Got the output locations")
mapStatuses.put(shuffleId, fetchedStatuses)
} finally {
fetching.synchronized {
fetching -= shuffleId
fetching.notifyAll()
}
}
}
if (fetchedStatuses != null) {
fetchedStatuses.synchronized {
return MapOutputTracker.convertMapStatuses(shuffleId, reduceId, fetchedStatuses)
}
} else {
logError("Missing all output locations for shuffle " + shuffleId)
throw new MetadataFetchFailedException(
shuffleId, reduceId, "Missing all output locations for shuffle " + shuffleId)
}
} else {
statuses.synchronized {
return MapOutputTracker.convertMapStatuses(shuffleId, reduceId, statuses)
}
}
}2.1.1. MapOutputTrackerMasterActor處理GetMapOutputStatuses訊息
case GetMapOutputStatuses(shuffleId: Int) =>
val hostPort = sender.path.address.hostPort
logInfo("Asked to send map output locations for shuffle " + shuffleId + " to " + hostPort)
val mapOutputStatuses = tracker.getSerializedMapOutputStatuses(shuffleId)
val serializedSize = mapOutputStatuses.size
if (serializedSize > maxAkkaFrameSize) {
val msg = s"Map output statuses were $serializedSize bytes which " +
s"exceeds spark.akka.frameSize ($maxAkkaFrameSize bytes)."
/* For SPARK-1244 we'll opt for just logging an error and then throwing an exception.
* Note that on exception the actor will just restart. A bigger refactoring (SPARK-1239)
* will ultimately remove this entire code path. */
val exception = new SparkException(msg)
logError(msg, exception)
throw exception
}
sender ! mapOutputStatuses2.1.2 MapOutputTrackerMaster.getSerializedMapOutputStatuses
def getSerializedMapOutputStatuses(shuffleId: Int): Array[Byte] = {
var statuses: Array[MapStatus] = null
var epochGotten: Long = -1
epochLock.synchronized {
if (epoch > cacheEpoch) {
cachedSerializedStatuses.clear()
cacheEpoch = epoch
}
cachedSerializedStatuses.get(shuffleId) match {
case Some(bytes) =>
return bytes
case None =>
statuses = mapStatuses.getOrElse(shuffleId, Array[MapStatus]())
epochGotten = epoch
}
}
// If we got here, we failed to find the serialized locations in the cache, so we pulled
// out a snapshot of the locations as "statuses"; let's serialize and return that
val bytes = MapOutputTracker.serializeMapStatuses(statuses)
logInfo("Size of output statuses for shuffle %d is %d bytes".format(shuffleId, bytes.length))
// Add them into the table only if the epoch hasn't changed while we were working
epochLock.synchronized {
if (epoch == epochGotten) {
cachedSerializedStatuses(shuffleId) = bytes
}
}
bytes
}2.1.3. MapOutputTracker.convertMapStatuses
private def convertMapStatuses(
shuffleId: Int,
reduceId: Int,
statuses: Array[MapStatus]): Array[(BlockManagerId, Long)] = {
assert (statuses != null)
statuses.map {
status =>
if (status == null) {
logError("Missing an output location for shuffle " + shuffleId)
throw new MetadataFetchFailedException(
shuffleId, reduceId, "Missing an output location for shuffle " + shuffleId)
} else {
(status.location, status.getSizeForBlock(reduceId))
}
}
}2.2. 構建ShuffleBlockId對映
獲取到Reudce對應的所有Block的位置及大小資訊後,BlockStoreShuffleFetcher.fetch方法開始構建ShuffleBlockId對映。 val statuses = SparkEnv.get.mapOutputTracker.getServerStatuses(shuffleId, reduceId)
logDebug("Fetching map output location for shuffle %d, reduce %d took %d ms".format(
shuffleId, reduceId, System.currentTimeMillis - startTime))
val splitsByAddress = new HashMap[BlockManagerId, ArrayBuffer[(Int, Long)]]
for (((address, size), index) <- statuses.zipWithIndex) {
splitsByAddress.getOrElseUpdate(address, ArrayBuffer()) += ((index, size))
}
val blocksByAddress: Seq[(BlockManagerId, Seq[(BlockId, Long)])] = splitsByAddress.toSeq.map {
case (address, splits) =>
(address, splits.map(s => (ShuffleBlockId(shuffleId, s._1, reduceId), s._2)))
}2.3. 建立ShuffleBlockFetcherIterator物件
構建完ShuffleBlockId對映後,BlockStoreShuffleFetcher.fetch方法開始建立ShuffleBlockFetcherIterator物件。 val blockFetcherItr = new ShuffleBlockFetcherIterator(
context,
SparkEnv.get.blockManager.shuffleClient,
blockManager,
blocksByAddress,
serializer,
SparkEnv.get.conf.getLong("spark.reducer.maxMbInFlight", 48) * 1024 * 1024)2.3.1. ShuffleBlockFetcherIterator.initialize
private[this] def initialize(): Unit = {
// Add a task completion callback (called in both success case and failure case) to cleanup.
context.addTaskCompletionListener(_ => cleanup())
// Split local and remote blocks.
val remoteRequests = splitLocalRemoteBlocks()
// Add the remote requests into our queue in a random order
fetchRequests ++= Utils.randomize(remoteRequests)
// Send out initial requests for blocks, up to our maxBytesInFlight
while (fetchRequests.nonEmpty &&
(bytesInFlight == 0 || bytesInFlight + fetchRequests.front.size <= maxBytesInFlight)) {
sendRequest(fetchRequests.dequeue())
}
val numFetches = remoteRequests.size - fetchRequests.size
logInfo("Started " + numFetches + " remote fetches in" + Utils.getUsedTimeMs(startTime))
// Get Local Blocks
fetchLocalBlocks()
logDebug("Got local blocks in " + Utils.getUsedTimeMs(startTime))
}2.3.2. ShuffleBlockFetcherIterator.sendRequest
private[this] def sendRequest(req: FetchRequest) {
logDebug("Sending request for %d blocks (%s) from %s".format(
req.blocks.size, Utils.bytesToString(req.size), req.address.hostPort))
bytesInFlight += req.size
// so we can look up the size of each blockID
val sizeMap = req.blocks.map { case (blockId, size) => (blockId.toString, size) }.toMap
val blockIds = req.blocks.map(_._1.toString)
val address = req.address
shuffleClient.fetchBlocks(address.host, address.port, address.executorId, blockIds.toArray,
new BlockFetchingListener {
override def onBlockFetchSuccess(blockId: String, buf: ManagedBuffer): Unit = {
// Only add the buffer to results queue if the iterator is not zombie,
// i.e. cleanup() has not been called yet.
if (!isZombie) {
// Increment the ref count because we need to pass this to a different thread.
// This needs to be released after use.
buf.retain()
results.put(new SuccessFetchResult(BlockId(blockId), sizeMap(blockId), buf))
shuffleMetrics.incRemoteBytesRead(buf.size)
shuffleMetrics.incRemoteBlocksFetched(1)
}
logTrace("Got remote block " + blockId + " after " + Utils.getUsedTimeMs(startTime))
}
override def onBlockFetchFailure(blockId: String, e: Throwable): Unit = {
logError(s"Failed to get block(s) from ${req.address.host}:${req.address.port}", e)
results.put(new FailureFetchResult(BlockId(blockId), e))
}
}
)
}2.3.3. ShuffleBlockFetcherIterator.fetchLocalBlocks
private[this] def fetchLocalBlocks() {
val iter = localBlocks.iterator
while (iter.hasNext) {
val blockId = iter.next()
try {
val buf = blockManager.getBlockData(blockId)
shuffleMetrics.incLocalBlocksFetched(1)
shuffleMetrics.incLocalBytesRead(buf.size)
buf.retain()
results.put(new SuccessFetchResult(blockId, 0, buf))
} catch {
case e: Exception =>
// If we see an exception, stop immediately.
logError(s"Error occurred while fetching local blocks", e)
results.put(new FailureFetchResult(blockId, e))
return
}
}
}2.4. 返回迭代器
當ShuffleBlockFetcherIterator構造完成後,會對該物件進行處理並封裝進InterruptibleIterator物件返回。 val itr = blockFetcherItr.flatMap(unpackBlock)
val completionIter = CompletionIterator[T, Iterator[T]](itr, {
context.taskMetrics.updateShuffleReadMetrics()
})
new InterruptibleIterator[T](context, completionIter) {
val readMetrics = context.taskMetrics.createShuffleReadMetricsForDependency()
override def next(): T = {
readMetrics.incRecordsRead(1)
delegate.next()
}
}