
HashMap與TreeMap的區別
前言
首先介紹一下什麼是Map.在陣列中我們是通過陣列下標來對其內容索引的,而在Map中我們通過物件來對物件進行索引,用來索引的物件叫做key,其對應的物件叫做value.這就是我們平時說的鍵值對。
HashMap通過hashcode對其內容進行快速查詢,而 TreeMap中所有的元素都保持著某種固定的順序,如果你需要得到一個有序的結果你就應該使用TreeMap(HashMap中元素的排列順序是不固定的)。
HashMap 程式碼分析
HashMap 是基於雜湊表的 Map 介面的實現。此實現提供所有可選的對映操作,並允許使用 null 值和 null 鍵。(除了非同步和允許使用 null 之外,HashMap 類與 Hashtable 大致相同。)此類不保證對映的順序,特別是它不保證該順序恆久不變。
官方文件如下:
此實現假定雜湊函式將元素適當地分佈在各桶之間,可為基本操作(get 和 put)提供穩定的效能。迭代 collection 檢視所需的時間與 HashMap 例項的“容量”(桶的數量)及其大小(鍵-值對映關係數)成比例。所以,如果迭代效能很重要,則不要將初始容量設定得太高(或將載入因子設定得太低)。
HashMap 的例項有兩個引數影響其效能:初始容量 和載入因子。容量 是雜湊表中桶的數量,初始容量只是雜湊表在建立時的容量。載入因子 是雜湊表在其容量自動增加之前可以達到多滿的一種尺度。當雜湊表中的條目數超出了載入因子與當前容量的乘積時,則要對該雜湊表進行 rehash 操作(即重建內部資料結構),從而雜湊表將具有大約兩倍的桶數。
通常,預設載入因子 (.75) 在時間和空間成本上尋求一種折衷。載入因子過高雖然減少了空間開銷,但同時也增加了查詢成本(在大多數 HashMap 類的操作中,包括 get 和 put 操作,都反映了這一點)。在設定初始容量時應該考慮到對映中所需的條目數及其載入因子,以便最大限度地減少 rehash 操作次數。如果初始容量大於最大條目數除以載入因子,則不會發生 rehash 操作。
如果很多對映關係要儲存在 HashMap 例項中,則相對於按需執行自動的 rehash 操作以增大表的容量來說,使用足夠大的初始容量建立它將使得對映關係能更有效地儲存。
注意,此實現不是同步的。如果多個執行緒同時訪問一個雜湊對映,而其中至少一個執行緒從結構上修改了該對映,則它必須 保持外部同步。(結構上的修改是指新增或刪除一個或多個對映關係的任何操作;僅改變與例項已經包含的鍵關聯的值不是結構上的修改。)這一般通過對自然封裝該對映的物件進行同步操作來完成。如果不存在這樣的物件,則應該使用 Collections.synchronizedMap 方法來“包裝”該對映。最好在建立時完成這一操作,以防止對對映進行意外的非同步訪問,如下所示:
Map m = Collections.synchronizedMap(new HashMap(…));
由所有此類的“collection 檢視方法”所返回的迭代器都是快速失敗 的:在迭代器建立之後,如果從結構上對對映進行修改,除非通過迭代器本身的 remove 方法,其他任何時間任何方式的修改,迭代器都將丟擲 ConcurrentModificationException。因此,面對併發的修改,迭代器很快就會完全失敗,而不冒在將來不確定的時間發生任意不確定行為的風險。
Map.put()的時候,需要將key值對映為相應的hash值,key的值是以char陣列的形式存放的,value對應的值也是有char陣列存放的
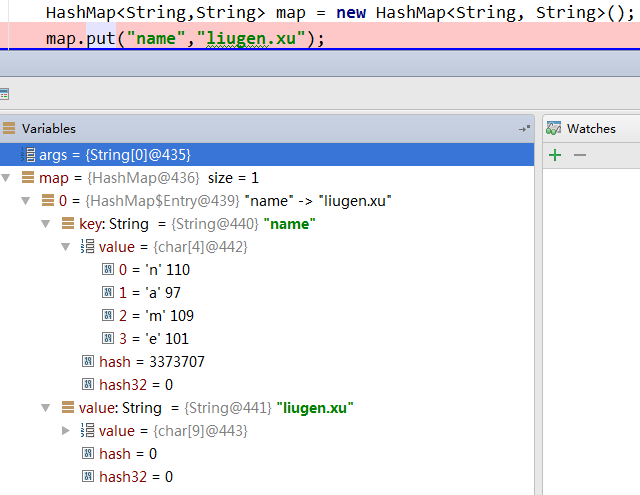
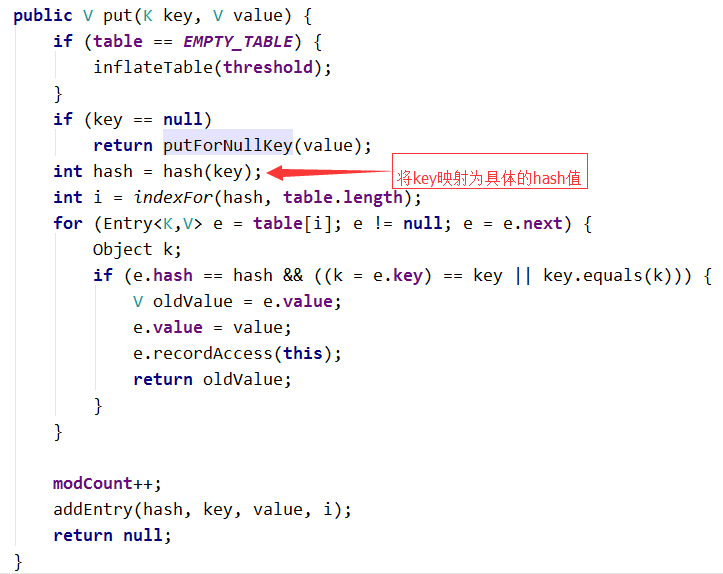
在進行存放的時候,首先檢查table是否為空,如果為空使用inflateTable方法進行初始化操作。
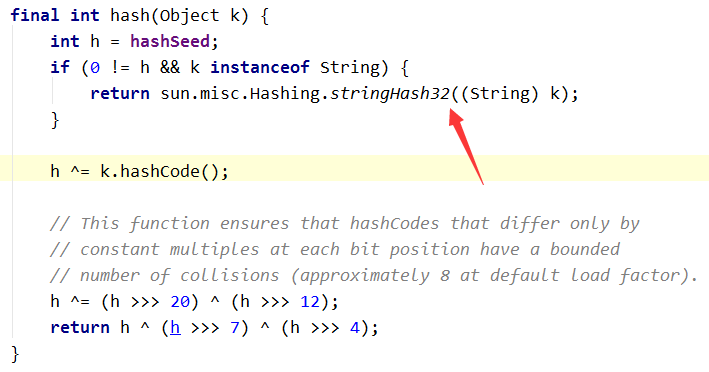
這裡用到的hash方法如下:
Map.get()的時候,是根據hash值進行查詢的:
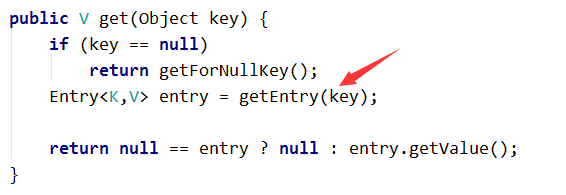
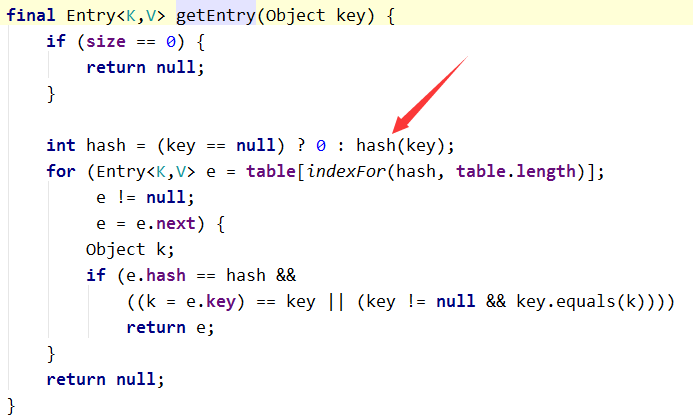
然後就是呼叫hash方法,找到具體的key所對應的hash,然後再到entry中去找value
TreeMap程式碼分析
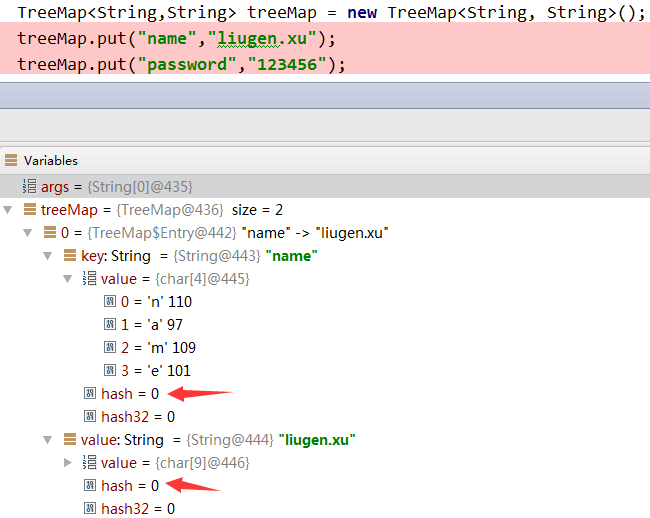
看到上邊,可知TreeMap並不是基於hash實現的,據說是紅黑樹,紅黑樹這塊幾乎空白,不敢多說:
TreeMap:基於紅黑樹實現。TreeMap沒有調優選項,因為該樹總處於平衡狀態。
(1)TreeMap():構建一個空的映像樹
(2)TreeMap(Map m): 構建一個映像樹,並且新增映像m中所有元素
(3)TreeMap(Comparator c): 構建一個映像樹,並且使用特定的比較器對關鍵字進行排序
(4)TreeMap(SortedMap s): 構建一個映像樹,新增映像樹s中所有對映,並且使用與有序映像s相同的比較器排序。
官方文件:
基於紅黑樹(Red-Black tree)的 NavigableMap 實現。該對映根據其鍵的自然順序進行排序,或者根據建立對映時提供的 Comparator 進行排序,具體取決於使用的構造方法。
此實現為 containsKey、get、put 和 remove 操作提供受保證的 log(n) 時間開銷。這些演算法是 Cormen、Leiserson 和 Rivest 的 Introduction to Algorithms 中的演算法的改編。
注意,如果要正確實現 Map 介面,則有序對映所保持的順序(無論是否明確提供了比較器)都必須與 equals 一致。(關於與 equals 一致 的精確定義,請參閱 Comparable 或 Comparator)。這是因為 Map 介面是按照 equals 操作定義的,但有序對映使用它的 compareTo(或 compare)方法對所有鍵進行比較,因此從有序對映的觀點來看,此方法認為相等的兩個鍵就是相等的。即使排序與 equals 不一致,有序對映的行為仍然是 定義良好的,只不過沒有遵守 Map 介面的常規協定。
注意,此實現不是同步的。如果多個執行緒同時訪問一個對映,並且其中至少一個執行緒從結構上修改了該對映,則其必須 外部同步。(結構上的修改是指新增或刪除一個或多個對映關係的操作;僅改變與現有鍵關聯的值不是結構上的修改。)這一般是通過對自然封裝該對映的物件執行同步操作來完成的。如果不存在這樣的物件,則應該使用 Collections.synchronizedSortedMap 方法來“包裝”該對映。最好在建立時完成這一操作,以防止對對映進行意外的不同步訪問,如下所示:
SortedMap m = Collections.synchronizedSortedMap(new TreeMap(…));
collection(由此類所有的“collection 檢視方法”返回)的 iterator 方法返回的迭代器都是快速失敗 的:在迭代器建立之後,如果從結構上對對映進行修改,除非通過迭代器自身的 remove 方法,否則在其他任何時間以任何方式進行修改都將導致迭代器丟擲 ConcurrentModificationException。因此,對於併發的修改,迭代器很快就完全失敗,而不會冒著在將來不確定的時間發生不確定行為的風險。
HashMap和TreeMap比較
(1)HashMap:適用於在Map中插入、刪除和定位元素。
(2)Treemap:適用於按自然順序或自定義順序遍歷鍵(key)。
(3)HashMap通常比TreeMap快一點(樹和雜湊表的資料結構使然),建議多使用HashMap,在需要排序的Map時候才用TreeMap.
(4)HashMap 非執行緒安全 TreeMap 非執行緒安全
(5)HashMap的結果是沒有排序的,而TreeMap輸出的結果是排好序的。
在HashMap中通過get()來獲取value,通過put()來插入value,ContainsKey()則用來檢驗物件是否已經存在。可以看出,和ArrayList的操作相比,HashMap除了通過key索引其內容之外,別的方面差異並不大。