
ECO: Efficient Convolution Operators for Tracking視訊目標跟蹤論文筆記(PPT版)
- 論文標題:ECO: Efficient Convolution Operators for Tracking
- 作者:Martin Danelljan 等
- 發表會議:CVPR 2017(目前的狀態為已錄用)
- 關鍵概念:
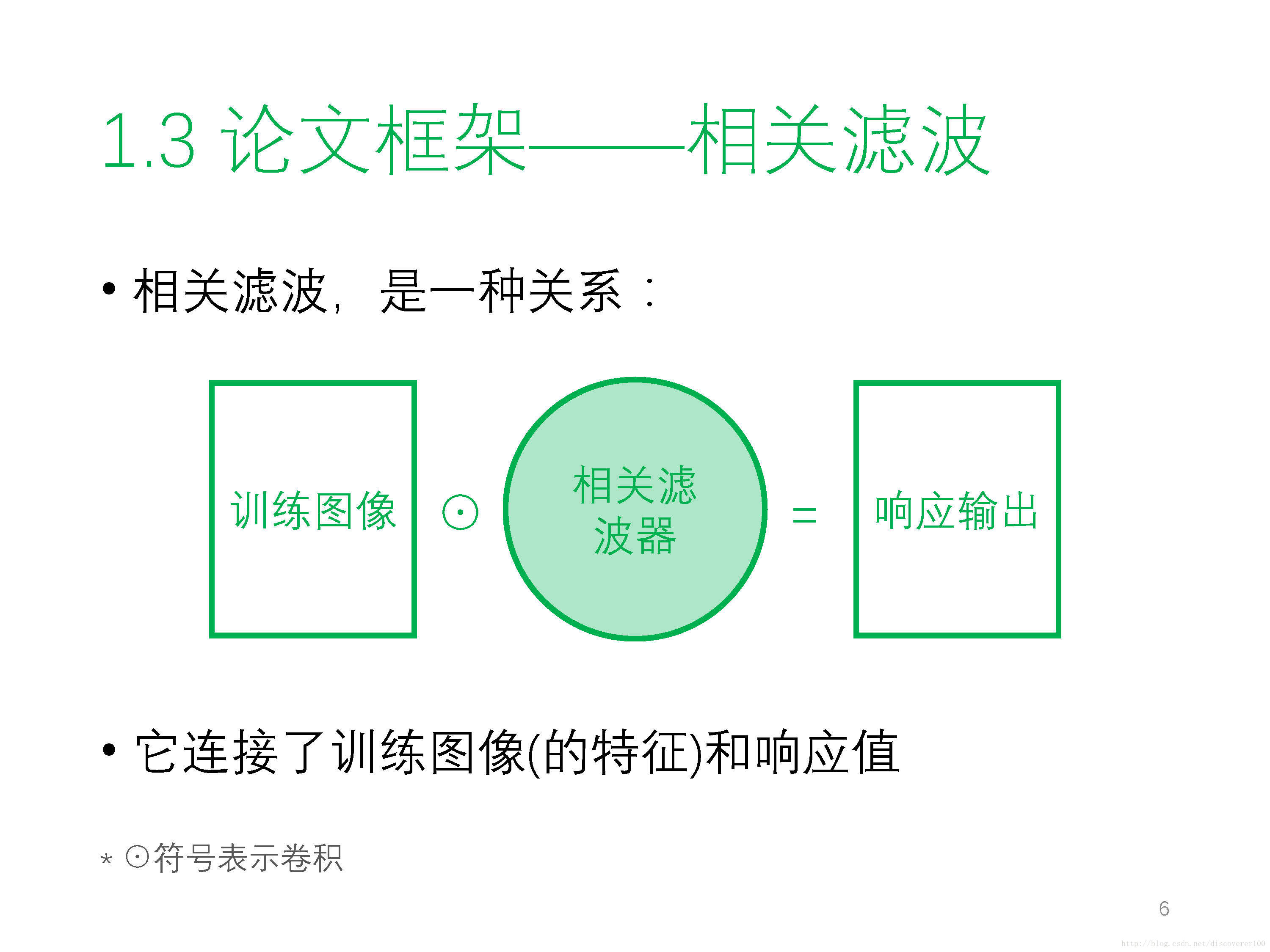
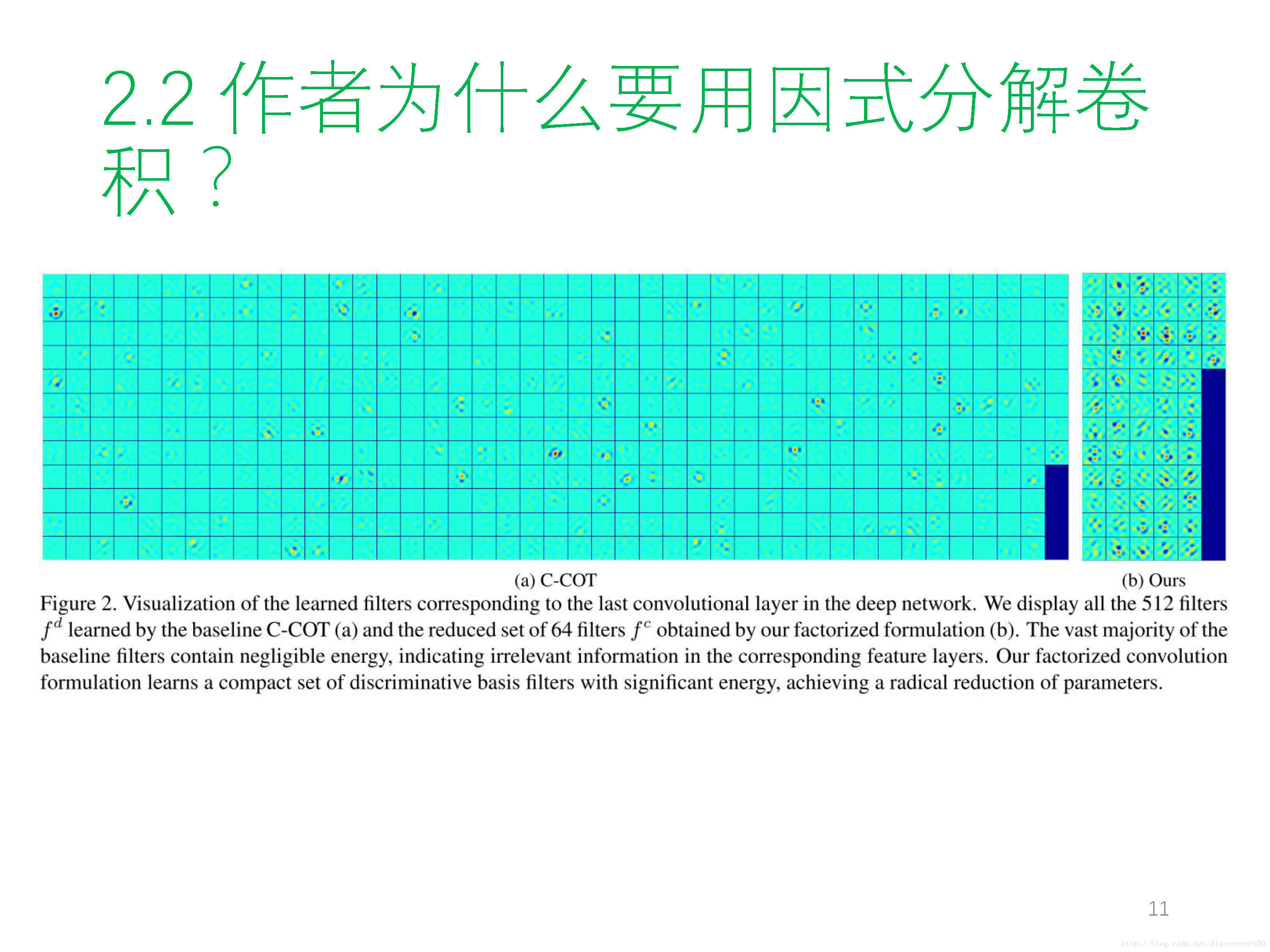
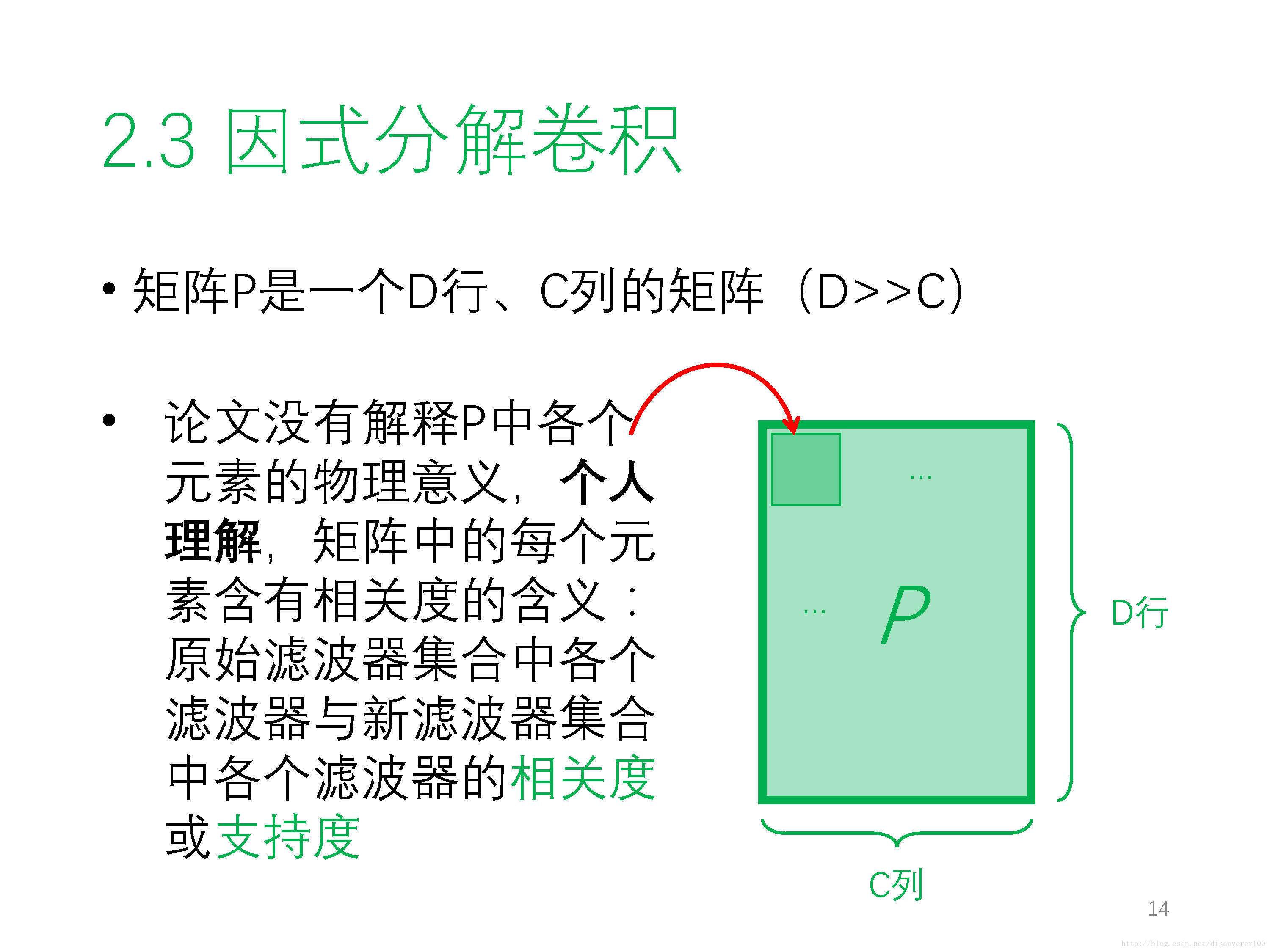
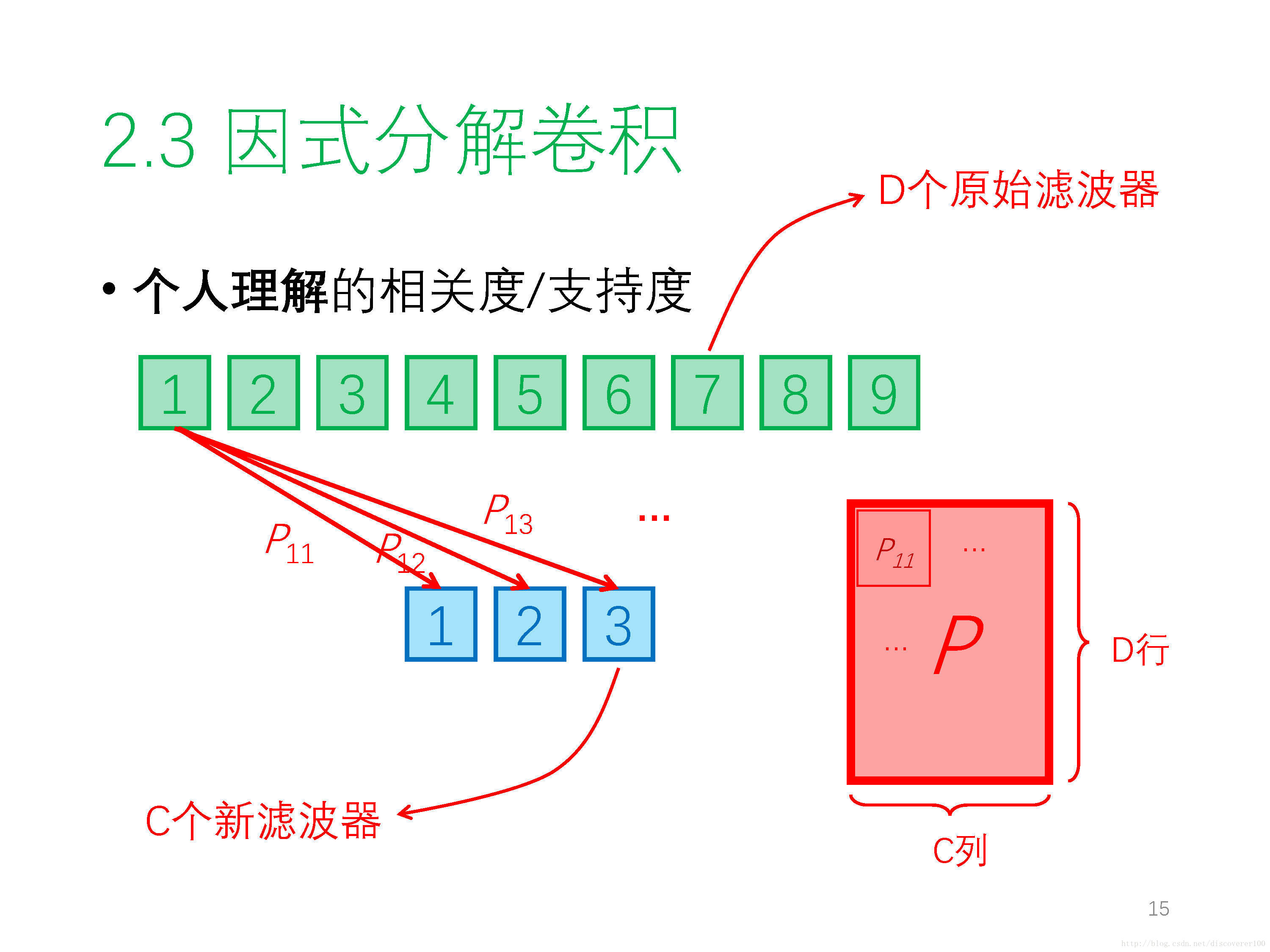
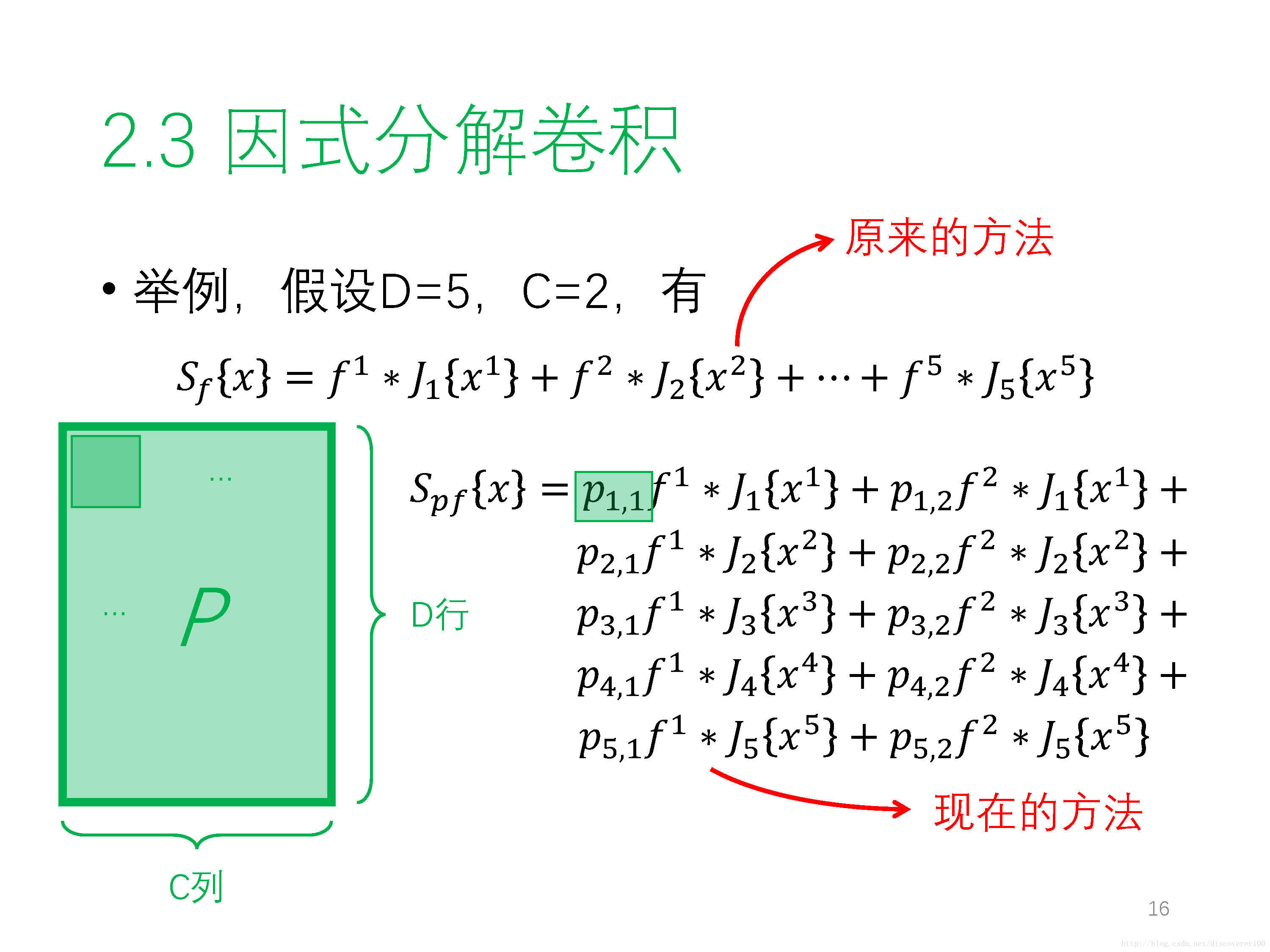
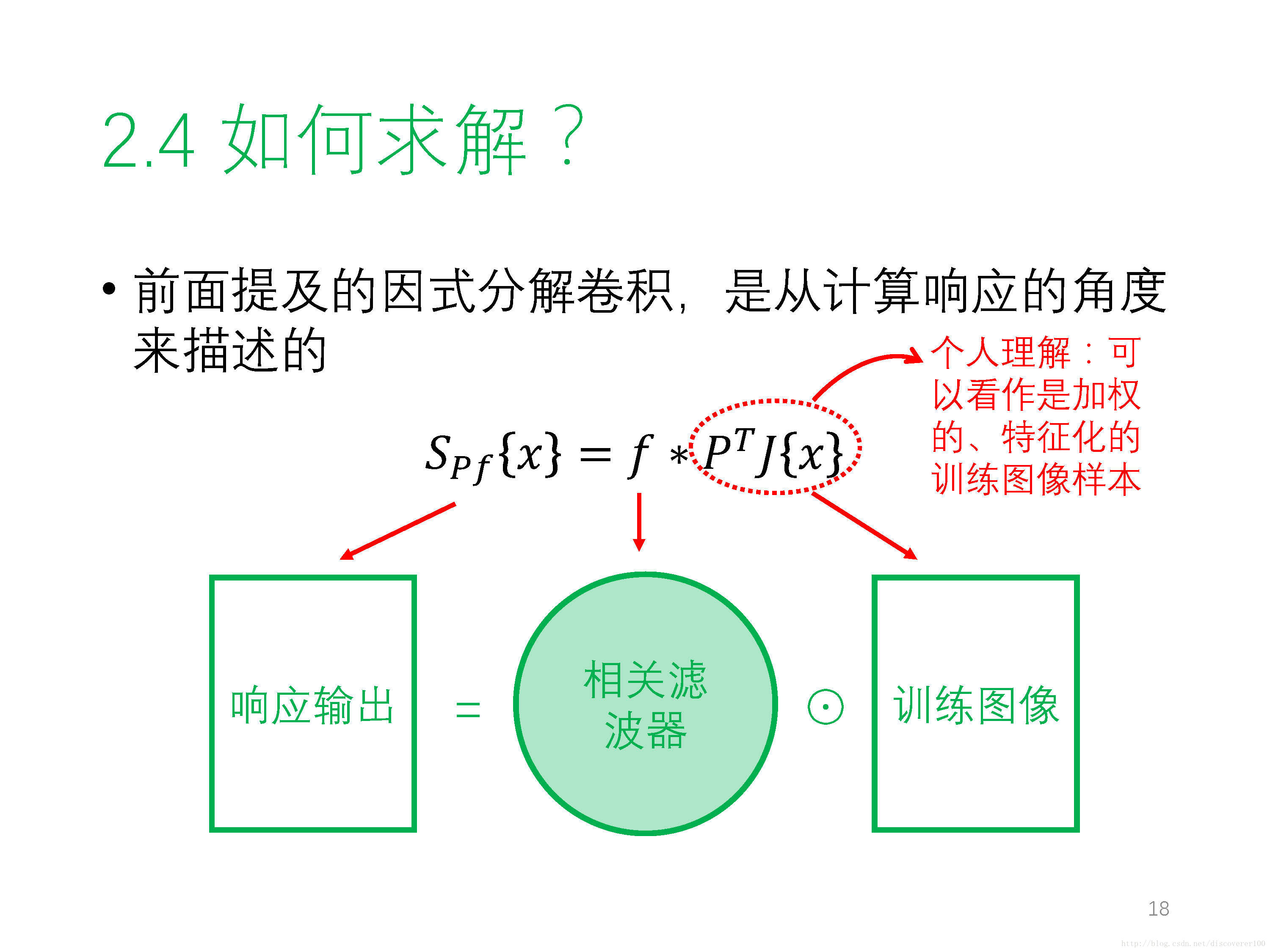
① 因式分解卷積 Factorized Convolution Operator
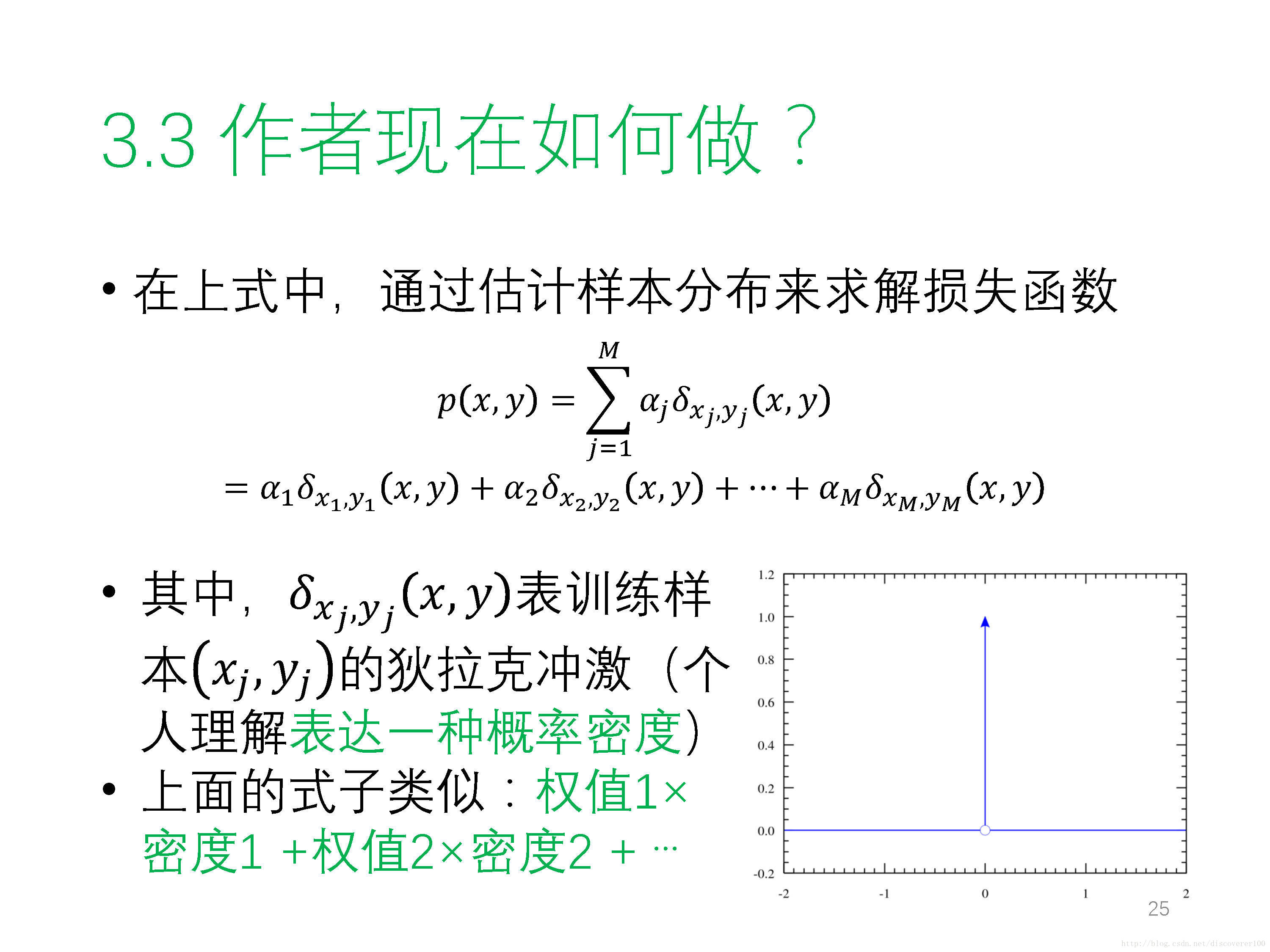
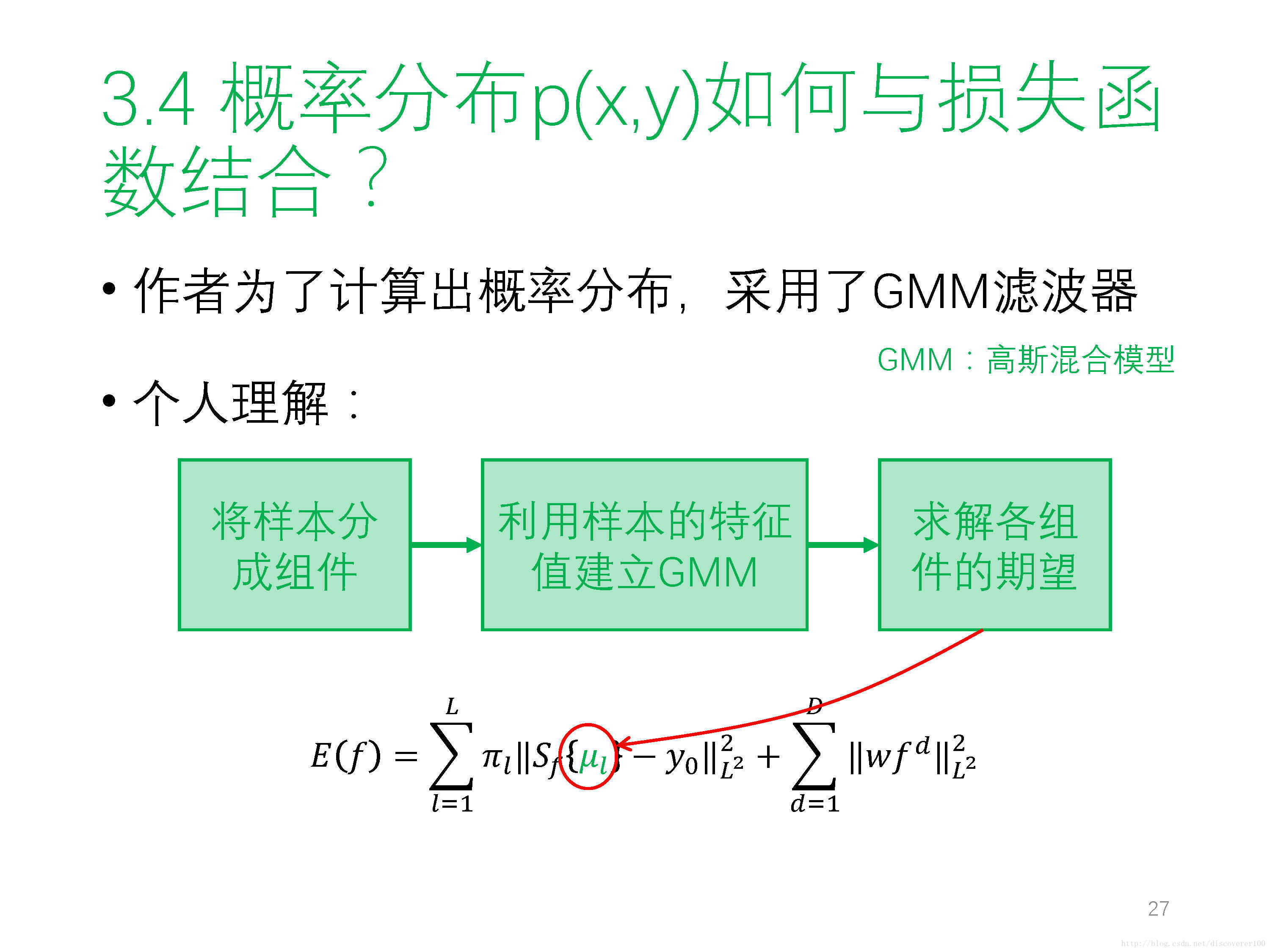
② 高斯混合模型 GMM(Gaussian Mixture Mode) - 原始碼:暫無,預計會公開
ECO論文由目標跟蹤領域的資深研究者Martin所寫,以下筆記部分內容屬於本部落格自己的理解(已在PPT中有關地方做出了標記),若覺得有不當之處或有疑問,歡迎留言探討。
另外需要注意:這篇論文是作者基於其上一篇論文C-COT進行完善而成,如果希望更深刻地理解ECO論文,需要將C-COT結合研讀。

























更多內容,請掃碼關注“視覺邊疆”微信訂閱號

相關推薦
ECO: Efficient Convolution Operators for Tracking視訊目標跟蹤論文筆記(PPT版)
論文標題:ECO: Efficient Convolution Operators for Tracking 作者:Martin Danelljan 等 發表會議:CVPR 2017(目前的狀態為已
ECO: Efficient Convolution Operators for Tracking
轉載至 http://blog.csdn.net/zixiximm/article/details/54378397Visual Tracking領域大牛(至少我認為是這個領域的大牛)Martin Danelljan又出新作。繼C-COT之後又一重新整理紀錄的作品。不管是從結
粒子濾波初探(二)利用粒子濾波實現視訊目標跟蹤-程式碼部分(C++&&opencv2.49)
利用粒子濾波實現視訊目標跟蹤工程實戰 放在最前:致謝taotao1233、yangyangcv、yang_xian521 以及先驅 Rob Hess 所開源的程式碼和思路。 本篇:基本為工程翻譯,以及對上面版本的一些修正,使用的是opencv2.49,以Ma
CFNet視訊目標跟蹤推導筆記
1. 論文資訊 論文題目:End-to-end representation learning for Correlation Filter based tracking 論文出處:CVPR 2017 論文作者:Jack Valmadre,Luca B
JS中對於for迴圈中點選事件的理解(通俗版)
在學習JS時遇到了一個問題,就是如果有多個按鈕時,我們可以通過document.getElementByTagName(“button”)的方式來獲取事件陣列,在獲取後我們需要監聽每一個按鈕是否被點選。最簡單的方式就是分開寫,一個按鈕對應一個點選事件函式,這樣雖然通俗易懂,但是這樣的程式碼量是十分大
ajax視訊拖拽上傳(完善版)
在前輩的基礎上,進行了一些完善 功能:可實現拖拽上傳視訊,有進度條顯示,MP4格式的視訊還可實現線上播放, 進行了視訊上傳格式限制,格式不符合有提示不能上傳,大小可按情況自行新增限制 最重要的是實現了大檔案斷點續傳的功能,更詳細功能可下載後體驗,就不一 一贅述了 首先,建
分析 PPTV 視訊真實播放地址全過程(Java版)
原文地址:https://www.52pojie.cn/thread-840710-1-1.html 分析視訊地址有什麼用?有些朋友經常會問到這個問題,其實這也是思維肌肉訓練的問題。我舉一個宋老師講過的例子(天氣預報和投資機會之間的關係)。說加勒比海出現熱帶颶風,普通小白看到這
基於稀疏表示的多目標跟蹤基本流程(文獻分析)
大家好,最近教研室的朋友們紛紛開博,作為定時上交週報以及月報的我,獨樂樂不如眾樂樂。以此不定時上傳跟大家分享一下。由於本人教研室工作較忙,除了文獻方法研究還要做工程專案,學習應用其他程式語言,你懂的。。請原諒我經常採用截圖的方式上傳自己的檔案,作為成電的一名研究
多個視訊檔案合成畫中畫效果(Python版)
Step 1 從視訊中分離出音訊(MP4->mp3) def separateMp4ToMp3(tmp): mp4 = tmp.replace('.tmp', '.mp4') print('---> Separate the vid
C-COT:Learning Continuous Convolution Operators for Visual Tracking程式問題
Martin Danelljan在ECCV2016發表的論文。 在之後的ECO中也有涉及。 這是瑞典Linkoping University(林雪平大學)的一個計算機視覺實驗室網站,裡面有Beyond Correlation Filters: Learning Cont
ECO: Efficient Convolutional Network for Online Video Understanding
目前視訊理解最新技術存在兩個問題:(1)推理的最大問題在於它只是在視訊中區域性進行,因此對於幾秒的動作,它丟失了動作行為之間的關係 (2)雖然存在快速處理的方法,但是整個視訊的處理效率不高並且妨礙了長期活動的快速視訊檢索或線上分類。
CFNet視訊目標跟蹤原始碼執行筆記(1)——only tracking
論文資訊 論文題目:End-to-end representation learning for Correlation Filter based tracking 論文出處:CVPR 2017 論文作者:Jack Valmadre,Luca Bertinet
視訊目標跟蹤:ECO程式碼除錯
本文只調試了ECO的MATLAB版本當中的CPU和GPU版!重點是講解如何除錯GPU版!重點是講解如何除錯GPU版!重點是講解如何除錯GPU版!我的配置環境是:matlab2018a+cuda9.0+cudnn9.0+VS2015 按照這個部落格步驟走一遍之後CPU版本
OpenCV視訊目標跟蹤及背景分割器
目標跟蹤 本文主要介紹cv2中的視訊分析Camshift和Meanshift。 目標: 學習Meanshift演算法和Camshift演算法來尋找和追蹤視訊中的目標物體 Meanshift演算法: meanshift演算法的原理很簡單。假設你有一堆點集,例如直方圖反向
SSD目標檢測(1):圖片+視訊內的物體定位(附原始碼)
一、SSD用於圖片物體的定位與檢測 SSD原理介紹這一篇部落格對我的幫助比較大,很詳細的介紹了SSD原理,送給大家做了解 1、下載SSD框架原始碼 1.1
視訊目標跟蹤綜述【一】
目標跟蹤作為計算機視覺中的經典問題,一直到現在都有很多學者在研究,目標跟蹤可以被應用於許多方面: 基於動作的識別,即基於步態的人類識別,自動物體檢測等; 自動監控,即監控場景檢測可疑活動或不太可能的事件; 自動監控,即監控場景檢測可疑活動或不太可能的事件; 視
CFNet視訊目標跟蹤核心原始碼分析——網路結構設計及實現
1. 論文資訊 2. 網路結構設計及實現 根據官方實際程式碼,更加詳細一點的網路結構如下圖所示,可以看出,與SiamFC的網路結構類似,CFNet也包含兩個分支——z和x,其中z分支對應目標物體模板,可以理解為目標在第 幀之內所有幀的模板資料加權融合(利用學習率
ArcGIS API for JavaScript3.x 學習筆記[3] 加載底圖(一)【天地圖(經緯度版)】
矢量地圖 說明 tiled spa 過程 相同 服務器列表 text 服務 1 <!DOCTYPE html> 2 <html> 3 <head> 4 <meta charset="utf-8"> 5
Person Re-identification 系列論文筆記(二):A Discriminatively Learned CNN Embedding for Person Re-identification
triplet put ali com multi 深度學習 native alt 出現 A Discriminatively Learned CNN Embedding for Person Re-identification Zheng Z, Zheng L, Ya
《A Discriminative Feature Learning Approach for Deep Face Recognition》論文筆記
1. 論文思想 在這篇文章中尉人臉識別提出了一種損失函式,叫做center loss,在網路中加入該損失函式之後可以使得網路學習每類特徵的中心,懲罰每類的特徵與中心之間的距離。並且該損失函式是可訓練的,並且在CNN中容易優化。那麼,將center loss與softmax相結合會增加