
ECO: Efficient Convolution Operators for Tracking
轉載至 http://blog.csdn.net/zixiximm/article/details/54378397
Visual Tracking領域大牛(至少我認為是這個領域的大牛)Martin Danelljan又出新作。繼C-COT之後又一重新整理紀錄的作品。不管是從結果還是速度上都有提升,尤其是速度提升明顯。用傳統特徵HOG+CN的版本速度有60+FPS,用CNN+HOG+CN的速度有8FPS,從跟蹤效果來看,個人認為可以算一個出色的作品。
C-COT是2016年ECCV的文章,下次有空再講。
這篇文章的baseline是Martin Danelljan的另一篇文章,就是上面提到的C-COT。
1. Motivation
這篇文章的出發點其實就是提高時間效率和空間效率。近一兩年來,效果好的很多方法都是基於相關濾波來做的。最早用到相關濾波的是Bolme等人在2010年CVPR的MOSSE,速度非常快。在MOSSE之後,像KCF,DSST,CN,SRDCF,C-COT等等都是在相關濾波的基礎上做的。隨著特徵維度越來越高,演算法越來越複雜,跟蹤效果雖然是在逐步提升,但是都是以犧牲跟蹤速度為代價的。(Martin Danelljan在相關濾波這一系列方法上可謂是如魚得水啊,有非常多的成果,非常多!)
那麼Martin Danelljan(後面叫他DM好了)在相關濾波做跟蹤的演算法上積累了豐富的經驗之後,分析了速度降低的三個最重要的因素:
(1) Model Size(模型大小)
也可以理解為特徵的複雜度。比如說C-COT用了CNN+HOG+CN這樣非常全面的特徵組合,它每次更新模型的時候,需要更新的引數有800000個,速度當然很慢。實際上跟蹤問題中的訓練樣本非常少,這麼高的維度除了速度慢,還會引起過擬合(over-fitting)。
(2) Training Set Size(訓練集大小)
這裡所指的訓練集是指儲存了每一幀的跟蹤結果的訓練集,也就是說,每一次進行model update的時候,要用在這一幀之前所有跟蹤到的樣本。那麼隨著視訊越來越長,這個訓練集就會越來越大。那麼一般的解決方案是儲存比較新的樣本,丟棄老的樣本,具體策略每個方法都不一樣。這樣一來,模型還是容易過擬合。因為當目標被遮擋或者丟失的時候,比較新的這些樣本本身就是錯的,那麼模型很容易有model drift,就是被背景或者錯誤的目標汙染,導致跟蹤結果出錯。另外,樣本集的儲存也會使得空間效率低下,增加計算負擔。
(3) Model Update
這個很顯然,模型如果每幀都更新,速度肯定比間歇更新要慢。我發現16年下半年開始,做tracking的人開始非常關注這個問題。而在此之前,很多方法基本都是每幀都更新的。另外每幀都更新也會有model drift問題,這個顯而易見不再贅述。
2. ECO Algorithm
好,那麼針對以上三個問題,DM分別給出了應對策略,從三方面進行改進。
2.1 Factorized Convolution Operator(因式分解的卷積操作)
先簡單介紹一下C-COT:
C-COT將特徵feature map通過插值轉換到連續的空間域了:
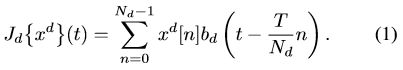
這裡就不具體介紹了,把(1) 式當成提取的特徵就行了,最後得到的特徵是J{x}。最後檢測目標的得分計算是:
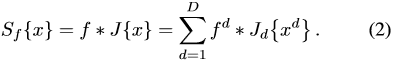
(2)中的f就是每個維度的特徵。 那麼學習相關濾波器的目標函式是:
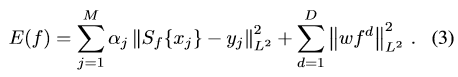
轉換到頻域是:
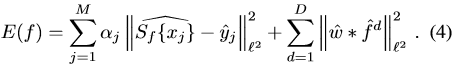
ECO在特徵提取上做了簡化。用了原來特徵的子集,從D維的特徵中選了其中的C維。C-COT是每個維度的特徵對應一個濾波器,D維的特徵就有D個濾波器,其實很多濾波器 的貢獻很小。如圖一所示,C-COT的大部分濾波器的能量很小。而ECO只選擇其中貢獻較多的C個濾波器,C<D,然後每一位特徵用這C個濾波器的線性組合來表示。這裡的C維如何選擇文中沒有具體說,我猜測是簡單的利用濾波器中大於某個閾值的元素個數來選擇。
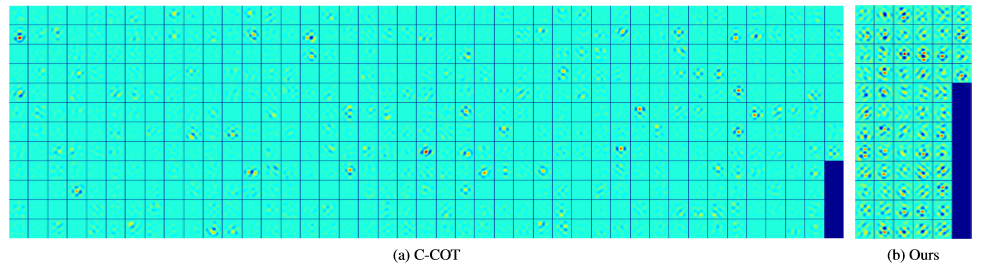
圖一:濾波器對比
那麼新的檢測函式是:
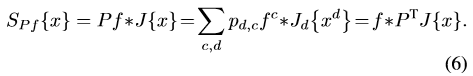
(6)式中P是一個DxC的矩陣,每一行代表對一個維度的特徵對應的濾波器用所有C個濾波器的線性組合係數,也是一個未知數,需要在第一幀中進行學習,之後的跟蹤中保持不變就行。這是學習濾波器的目標函式與(4)有了一些變化,現在是這樣的:
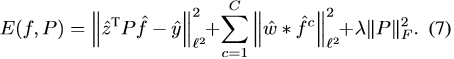
在這個新的目標函式中,z=J{x},又在最後加了一項整定項,為了約束P。(7)現在是一個非線性最小二乘問題,其中第一項的具有雙線性。因此DM把這個問題轉化為一個矩陣的因式分解問題。用了Gauss-Newton和Conjugate Gradient來求解。具體的過程就不細講了,與理解文章沒有太大關係。
到此,第一個問題Model Size的解決就是這樣了,從D降到了C。相當於將特徵J{x} 換成了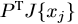
2.2 Generative Sample Space Model
ECO簡化了訓練集,如圖二所示。
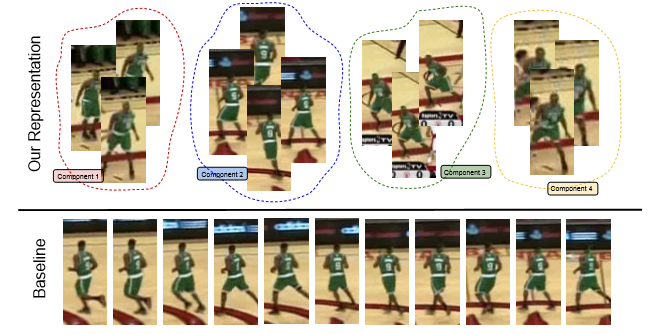
圖二:訓練集
圖二中下面一行是傳統的訓練集,每更新一幀就加一個進來,那麼連續的數幀後訓練集裡面的樣本都是高度相似的,即容易對最近的數幀樣本過擬合。上面一行是ECO的做法,ECO用了高斯混合模型(GMM)來生成不同的component,每一個component基本就對應一組比較相似的樣本,不同的component之間有較大的差異性。這樣就使得訓練集具有了多樣性。
通過樣本x和目標輸出y的聯合概率分佈p(x,y),將目標函式進一步完善為:
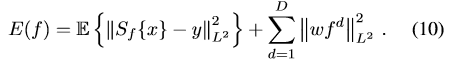
(10)式是將(3)式的第一項換成了基於樣本的聯合概率分佈。(3)是(10)的一個特例。另外,由於目標輸出的y其實形狀都是一致的,是一個峰值在目標中心的高斯函式,只是峰值 的位置不一樣。那麼ECO將y都設定成一樣的,把峰值位置的平移量體現到x上,在頻域中可以簡單處理。那麼p(x,y)就簡化了,只需要計算p(x)就行了。這裡用GMM來建模:
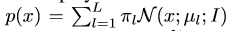
更新過程是這樣的:每次新來一個樣本,初始化一個component m,初始化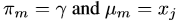
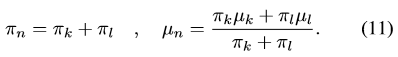
近似目標函式(10)為:
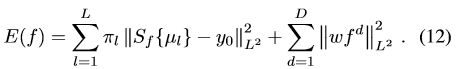
(12)是把原來的M個樣本減少為L個component的平均值。
在實際中,L設定為M/8,再一次減少了計算量,即1中提到的第二點,訓練集大小。同時由於增加了樣本的多樣性,使得效果也有提升。
2.3 Model Update Strategy
ECO這裡的做法很簡單,就是簡單地規定每隔Ns幀更新一次。注意這裡的Ns只是對模型的更新,樣本的更新是每一幀都要做的。最後的實驗中,Ns設定為6。
模型更新頻率降低,當然節約了時間,並且可以避免模型的漂移問題,一定程度上改進效果,但是也不可以把Ns取得太大,否則會使得模型跟不上目標的變化。
到此為止,ECO針對1中的三個問題都提出瞭解決方案,從速度和效果上都有了改進。
3. Experiment
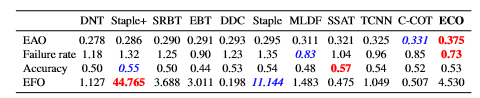
具體的引數設定就不介紹了,可以直接看文章。直接放效果了,做tracking的人應該都看得懂。不做tracking的人,反正一句話:都是第一名!
VOT2016
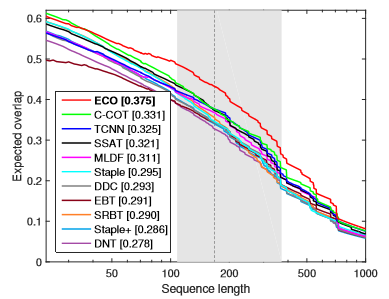
OTB100,Temple-color,UAV123
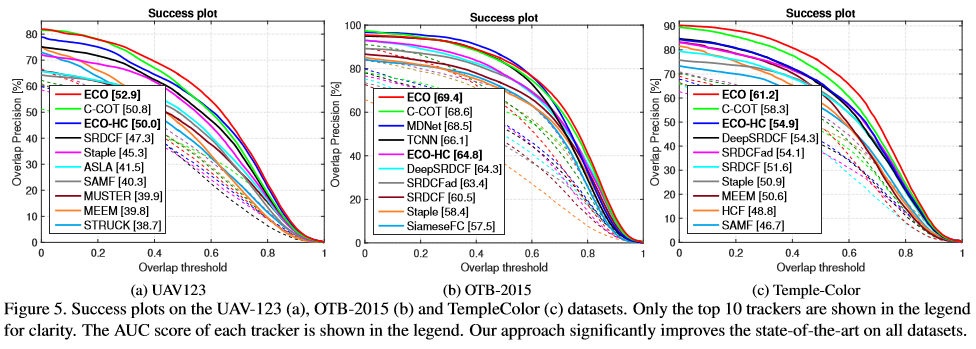
ECO通通第一,另外不用CNN的ECO-HC效果也很好,甚至比用CNN的DeepSRDCF還要好。用傳統特徵HOG+CN的版本速度有60+FPS,用CNN+HOG+CN的速度有8FPS。
總結一下ECO效果好的原因:
1. 特徵全面(CNN, HOG, CN),這個對結果的貢獻很高;
2. 相關濾波器經過篩選更具代表性(2.1做的),防止過擬合;
3. 訓練樣本具有多樣性(2.2做的),減少冗餘;
4. 非每幀更新模型,防止模型漂移;