
樸素貝葉斯分類器--一種簡單有效的常用分類演算法
一、病人分類的例子
讓我從一個例子開始講起,你會看到貝葉斯分類器很好懂,一點都不難。
某個醫院早上收了六個門診病人,如下表。
症狀 職業 疾病
打噴嚏 護士 感冒
打噴嚏 農夫 過敏
頭痛 建築工人 腦震盪
頭痛 建築工人 感冒
打噴嚏 教師 感冒
頭痛 教師 腦震盪 現在又來了第七個病人,是一個打噴嚏的建築工人。請問他患上感冒的概率有多大?
根據貝葉斯定理:
P(A|B) = P(B|A) P(A) / P(B)可得
P(感冒|打噴嚏x建築工人)
= P(打噴嚏x建築工人|感冒) x P(感冒)
/ P(打噴嚏x建築工人) 假定”打噴嚏”和”建築工人”這兩個特徵是獨立的,因此,上面的等式就變成了
P(感冒|打噴嚏x建築工人)
= P(打噴嚏|感冒) x P(建築工人|感冒) x P(感冒)
/ P(打噴嚏) x P(建築工人) 這是可以計算的:
P(感冒|打噴嚏x建築工人)
= 0.66 x 0.33 x 0.5 / 0.5 x 0.33
= 0.66 因此,這個打噴嚏的建築工人,有66%的概率是得了感冒。同理,可以計算這個病人患上過敏或腦震盪的概率。比較這幾個概率,就可以知道他最可能得什麼病。
這就是貝葉斯分類器的基本方法:在統計資料的基礎上,依據某些特徵,計算各個類別的概率,從而實現分類。
二、樸素貝葉斯分類器的公式
假設某個體有n項特徵(Feature),分別為F1、F2、…、Fn。現有m個類別(Category),分別為C1、C2、…、Cm。貝葉斯分類器就是計算出概率最大的那個分類,也就是求下面這個算式的最大值:
P(C|F1F2...Fn)
= P(F1F2...Fn|C)P(C) / P(F1F2...Fn)由於 P(F1F2…Fn) 對於所有的類別都是相同的,可以省略,問題就變成了求
P(F1F2...Fn|C)P(C) 的最大值。
樸素貝葉斯分類器則是更進一步,假設所有特徵都彼此獨立,因此
P(F1F2...Fn|C)P(C)
= P(F1|C)P(F2|C) ... 上式等號右邊的每一項,都可以從統計資料中得到,由此就可以計算出每個類別對應的概率,從而找出最大概率的那個類。
雖然”所有特徵彼此獨立”這個假設,在現實中不太可能成立,但是它可以大大簡化計算,而且有研究表明對分類結果的準確性影響不大。
下面再通過兩個例子,來看如何使用樸素貝葉斯分類器。
三、賬號分類的例子
根據某社群網站的抽樣統計,該站10000個賬號中有89%為真實賬號(設為C0),11%為虛假賬號(設為C1)
接下來,就要用統計資料判斷一個賬號的真實性。假定某一個賬號有以下三個特徵:
F1: 日誌數量/註冊天數
F2: 好友數量/註冊天數
F3: 是否使用真實頭像(真實頭像為1,非真實頭像為0)
F1 = 0.1
F2 = 0.2
F3 = 0請問該賬號是真實賬號還是虛假賬號?
方法是使用樸素貝葉斯分類器,計算下面這個計算式的值。
P(F1|C)P(F2|C)P(F3|C)P(C)
雖然上面這些值可以從統計資料得到,但是這裡有一個問題:F1和F2是連續變數,不適宜按照某個特定值計算概率。
一個技巧是將連續值變為離散值,計算區間的概率。比如將F1分解成[0, 0.05]、(0.05, 0.2)、[0.2, +∞]三個區間,然後計算每個區間的概率。在我們這個例子中,F1等於0.1,落在第二個區間,所以計算的時候,就使用第二個區間的發生概率。
根據統計資料,可得:
P(F1|C0) = 0.5, P(F1|C1) = 0.1
P(F2|C0) = 0.7, P(F2|C1) = 0.2
P(F3|C0) = 0.2, P(F3|C1) = 0.9因此,
P(F1|C0) P(F2|C0) P(F3|C0) P(C0)
= 0.5 x 0.7 x 0.2 x 0.89
= 0.0623
P(F1|C1) P(F2|C1) P(F3|C1) P(C1)
= 0.1 x 0.2 x 0.9 x 0.11
= 0.00198可以看到,雖然這個使用者沒有使用真實頭像,但是他是真實賬號的概率,比虛假賬號高出30多倍,因此判斷這個賬號為真。
四、性別分類的例子
本例摘自維基百科,關於處理連續變數的另一種方法。
下面是一組人類身體特徵的統計資料。
性別 身高(英尺) 體重(磅) 腳掌(英寸)
男 6 180 12
男 5.92 190 11
男 5.58 170 12
男 5.92 165 10
女 5 100 6
女 5.5 150 8
女 5.42 130 7
女 5.75 150 9 已知某人身高6英尺、體重130磅,腳掌8英寸,請問該人是男是女?
根據樸素貝葉斯分類器,計算下面這個式子的值
P(身高|性別) x P(體重|性別) x P(腳掌|性別) x P(性別)
這裡的困難在於,由於身高、體重、腳掌都是連續變數,不能採用離散變數的方法計算概率。而且由於樣本太少,所以也無法分成區間計算。怎麼辦?
這時,可以假設男性和女性的身高、體重、腳掌都是正態分佈,通過樣本計算出均值和方差,也就是得到正態分佈的密度函式。有了密度函式,就可以把值代入,算出某一點的密度函式的值。
比如,男性的身高是均值5.855、方差0.035的正態分佈。所以,男性的身高為6英尺的概率的相對值等於1.5789(大於1並沒有關係,因為這裡是密度函式的值,只用來反映各個值的相對可能性)。
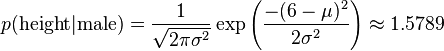
有了這些資料以後,就可以計算性別的分類了。
P(身高=6|男) x P(體重=130|男) x P(腳掌=8|男) x P(男)
= 6.1984 x e-9
P(身高=6|女) x P(體重=130|女) x P(腳掌=8|女) x P(女)
= 5.3778 x e-4
可以看到,女性的概率比男性要高出將近10000倍,所以判斷該人為女性。
(完)