[強化學習-5] 值函式近似
值函式近似
前幾篇部落格講了如何進行值函式估計,估計完之後這些結果怎麼保持呢,狀態動作空間很小的就存在表中,用的時候查表獲取v(s)和Q(s, a),但當狀態空間是高維連續時,需要儲存的東西就太多了,這個表就不行了,這時我們會採用函式近似(function approximation)的方式對值函式進行引數化近似:
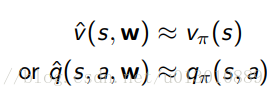
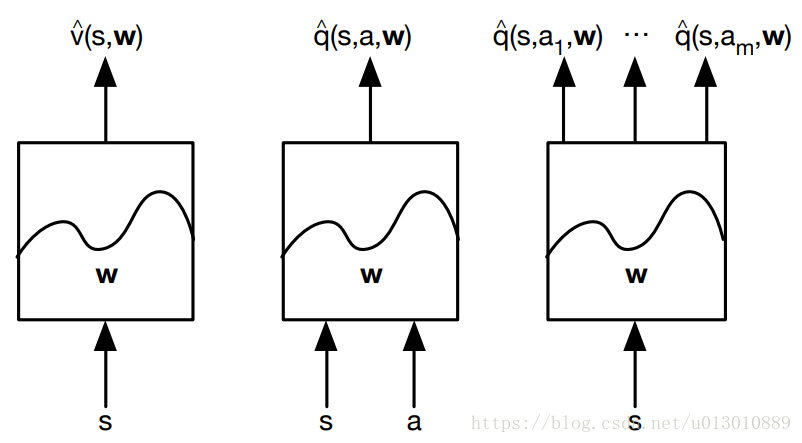
一般的函式近似有
- Linear combinations of features(可微,引數是特徵的權重)
- Neural network(可微,引數是每層的連線權重)
- Decision tree(引數是葉子節點的取值,和樹節點分裂的閾值)
- Nearest neighbour
- Fourier / wavelet bases
一般要求:引數個數要小於狀態(或狀態-行為)的個數
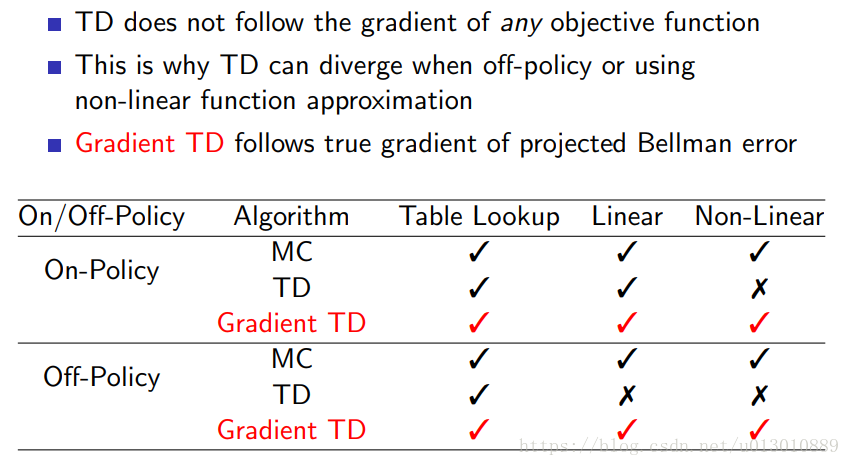
表格型強化學習和函式逼近方法的強化學習值函式更新時的異同點:
1. 表格型強化學習進行值函式更新時,只有當前狀態處的值函式在改變,其他地方的值函式不發生改變。
2. 值函式逼近方法進行值函式更新時,因此更新的是引數,而估計的值函式為,所以當引數發生改變時,任意狀態處的值函式都會發生改變。
引數化近似方法的引數學習
我們用特徵向量來表示一個狀態s,讓它作為輸入。 “查表”方法是一個特殊的線性價值函式近似方法:每一個狀態看成一個特徵,個體具體處在某一個狀態時,該狀態特徵取1,其餘取0。類似於one-hot向量一樣。所以我們可以用線性組合來近似價值函式。


事實上,上面的公式都是無法直接在強化學習中使用的。因為在這裡我們都是假設已經知道了真實值vπ(S)。然而在強化學習中,我們是不知道真實值的。也就是強化學習沒有監督資料。
因此,我們的做法其實是用估計值代替真實值vπ(S): 注意MC是無偏的趨近於區域性最優,而TD是有偏的趨近於全域性最優

收斂性