
強化學習 6 ——價值函式逼近
阿新 • • 發佈:2020-09-06
上篇文章[強化學習——時序差分 (TD) 控制演算法 Sarsa 和 Q-Learning](https://blog.csdn.net/november_chopin/article/details/107897225)我們主要介紹了 Sarsa 和 Q-Learning 兩種時序差分控制演算法,在這兩種演算法內部都要維護一張 Q 表格,對於小型的強化學習問題是非常靈活高效的。但是在狀態和可選動作非常多的問題中,這張Q表格就變得異常巨大,甚至超出記憶體,而且查詢效率極其低下,從而限制了時序差分的應用場景。近些年來,隨著神經網路的興起,基於深度學習的強化學習稱為了主流,也就是深度強化學習(DRL)。
## 一、函式逼近介紹
我們知道限制 Sarsa 和 Q-Learning 的應用場景原因是需要維護一張巨大的 Q 表格,那麼我們能不能用其他的方式來代替 Q表格呢?很自然的,就想到了函式。
$$
\hat{v}(s, w) \approx v_\pi(s) \\
\hat{q}(s,a, w) \approx q_\pi(s, a) \\
\hat{\pi}{a,s,w} \approx \pi(a|s)
$$
也就是說我們可以用一個函式來代替 Q 表格,不斷更新 $q(s,a)$ 的過程就可以轉化為用引數來擬合逼近真實 q 值的過程。這樣學習的過程不是更新 Q 表格,而是更新 引數 w 的過程。
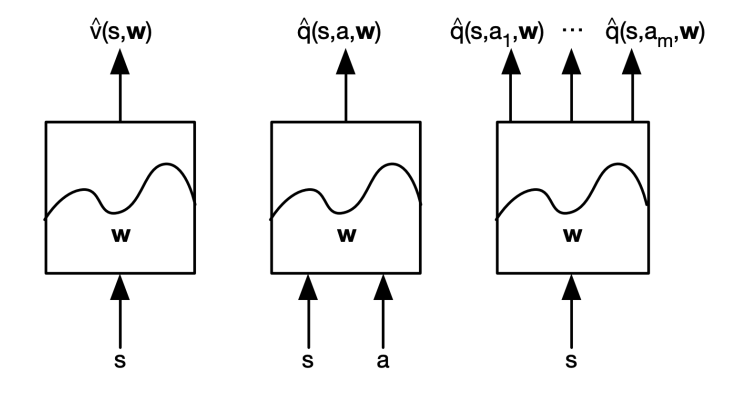 下面是幾種不同的擬合方式:
第一種函式接受當前的 狀態 S 作為輸入,輸出擬合後的價值函式
第二種函式同時接受 狀態 S 和 動作 a 作為輸入,輸出擬合後的動作價值函式
第三種函式接受狀態 S,輸出每個動作對應的動作價值函式 q
常見逼近函式有線性特徵組合方式、神經網路、決策樹、最近鄰等,在這裡我們只討論可微分的擬合函式:線性特徵組合和神經網路兩種方式。
### 1、知道真實 V 的函式逼近
對於給定的一個狀態 S 我們假定我們知道真實的 $v_\pi(s)$ ,然後我們經過擬合得到 $\hat{v}(s, w)$ ,於是我們就可以使用均方差來計算損失
$$
J(w) = E_\pi[(v_\pi(s) - \hat{v}(s, w))^2]
$$
利用梯度下降去找到區域性最小值:
$$
\Delta w = -\frac{1}{2}\alpha \nabla_wJ(w) \\
w_{t+1} = w_t + \Delta w
$$
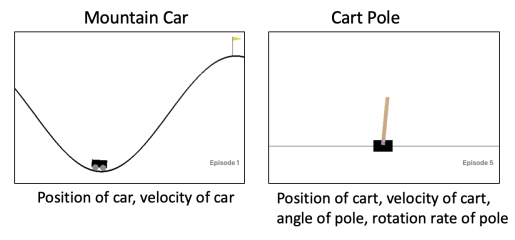
我們可以提取一些特徵向量來表示當前的 狀態 S,比如對於 gym 的 CartPole 環境,我們可提取的特徵有推車的位置、推車的速度、木杆的角度、木杆的角速度等
下面是幾種不同的擬合方式:
第一種函式接受當前的 狀態 S 作為輸入,輸出擬合後的價值函式
第二種函式同時接受 狀態 S 和 動作 a 作為輸入,輸出擬合後的動作價值函式
第三種函式接受狀態 S,輸出每個動作對應的動作價值函式 q
常見逼近函式有線性特徵組合方式、神經網路、決策樹、最近鄰等,在這裡我們只討論可微分的擬合函式:線性特徵組合和神經網路兩種方式。
### 1、知道真實 V 的函式逼近
對於給定的一個狀態 S 我們假定我們知道真實的 $v_\pi(s)$ ,然後我們經過擬合得到 $\hat{v}(s, w)$ ,於是我們就可以使用均方差來計算損失
$$
J(w) = E_\pi[(v_\pi(s) - \hat{v}(s, w))^2]
$$
利用梯度下降去找到區域性最小值:
$$
\Delta w = -\frac{1}{2}\alpha \nabla_wJ(w) \\
w_{t+1} = w_t + \Delta w
$$
我們可以提取一些特徵向量來表示當前的 狀態 S,比如對於 gym 的 CartPole 環境,我們可提取的特徵有推車的位置、推車的速度、木杆的角度、木杆的角速度等
下面是幾種不同的擬合方式:
第一種函式接受當前的 狀態 S 作為輸入,輸出擬合後的價值函式
第二種函式同時接受 狀態 S 和 動作 a 作為輸入,輸出擬合後的動作價值函式
第三種函式接受狀態 S,輸出每個動作對應的動作價值函式 q
常見逼近函式有線性特徵組合方式、神經網路、決策樹、最近鄰等,在這裡我們只討論可微分的擬合函式:線性特徵組合和神經網路兩種方式。
### 1、知道真實 V 的函式逼近
對於給定的一個狀態 S 我們假定我們知道真實的 $v_\pi(s)$ ,然後我們經過擬合得到 $\hat{v}(s, w)$ ,於是我們就可以使用均方差來計算損失
$$
J(w) = E_\pi[(v_\pi(s) - \hat{v}(s, w))^2]
$$
利用梯度下降去找到區域性最小值:
$$
\Delta w = -\frac{1}{2}\alpha \nabla_wJ(w) \\
w_{t+1} = w_t + \Delta w
$$
我們可以提取一些特徵向量來表示當前的 狀態 S,比如對於 gym 的 CartPole 環境,我們可提取的特徵有推車的位置、推車的速度、木杆的角度、木杆的角速度等