
貸款使用者逾期情況分析
目錄
任務描述
給定金融資料,預測貸款使用者是否會逾期。(status是標籤:0表示未逾期,1表示逾期。)
Misson1 - 構建邏輯迴歸模型進行預測
Misson2 - 構建SVM和決策樹模型進行預測
Misson3 - 構建xgboost和lightgbm模型進行預測
Mission4 - 記錄五個模型關於precision,rescore,f1,auc,roc的評分表格,畫出auc和roc曲線圖
Mission5 - 關於資料型別轉換以及缺失值處理(嘗試不同的填充看效果)以及你能借鑑的資料探索
Mission6
Mission7 - 用你目前評分最高的模型作為基準模型,和其他模型進行stacking融合,得到最終模型及評分
實現過程
基本思路
主要分為以下若干步驟:
1)資料集預覽
2)資料預處理:切分X,y;刪除無用特徵;字元型特徵編碼;缺失值填充 等
3)特徵工程
4)模型選擇:lr,svm,dt,xgboost,lightgbm 等
5)模型調參
6)效能評估
7)最終結果
1. 資料集預覽
# 因為資料並非utf-8編碼,要使用gbk編碼讀入,否則出錯 data = pd.read_csv('./data/data.csv', index_col=0, encoding='gbk') # 觀察資料構成 # data.head() print(data.shape) # (4754, 89)
2. 資料預處理
X, y 劃分
# 劃分 X, y
y = data['status']
X = data.drop('status', axis=1)特徵處理
# 首先剔除一些明顯無用的特徵,如 id_name, custid, trade_no, bank_card_no, # 這些優點類似一個人的唯一資訊,如果加入模型訓練且對最終模型生效的話,很可能就是出現了過擬合 X.drop(['id_name', 'custid', 'trade_no', 'bank_card_no'], axis=1, inplace=True) # 數值型變數 X_num = X.select_dtypes('number').copy() # student_feature X_num.fillna({'student_feature': 0}, inplace=True) # 其他數值型變數使用均值代替 X_num.fillna(X_num.mean(), inplace=True) # 字元型變數 X_str = X.select_dtypes(exclude='number').copy() X_str_dummy = pd.get_dummies(X_str['reg_preference_for_trad']) # 合併 X_cl = pd.concat([X_num, X_str_dummy], axis=1, sort=False) X_cl.shape
3. 特徵工程
4. 模型選擇
4.1 資料及劃分及資料歸一化
# 資料劃分
from sklearn.model_selection import train_test_split
random_state = 1115
X_train, X_test, y_train, y_test = train_test_split(X_cl, y, test_size=0.3, random_state=random_state)
# 歸一化
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
X_train_std = ss.fit_transform(X_train)
X_test_std = ss.transform(X_test)4.2 LR
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(C=0.05, penalty='l1')
lr.fit(X_train_std, y_train)4.3 SVM
from sklearn.svm import SVC
# 線性 SVM
linear_svc = SVC(kernel='linear', probability=True)
linear_svc.fit(X_train_std, y_train)
# 多項式 SVM
poly_svc = SVC(kernel='poly', probability=True)
poly_svc.fit(X_train_std, y_train)4.4 決策樹
from sklearn.tree import DecisionTreeClassifier
# 決策樹
dt = DecisionTreeClassifier(max_depth=8)
dt.fit(X_train_std, y_train)4.5 Xgboost
from xgboost.sklearn import XGBClassifier
xgb_params = {
'learning_rate': 0.1,
'n_estimators': 42,
'max_depth': 5,
'min_child_weight': 1,
'gamma': 0,
'subsample': 0.8,
'colsample_bytree': 0.8,
'objective': 'binary:logistic',
'nthread': 4,
'scale_pos_weight': 1,
'seed': 112
}
xgb_model = XGBClassifier(**xgb_params)
# 訓練
xgb_model.fit(X_train_std, y_train)4.6 LightGBM
from lightgbm.sklearn import LGBMClassifier
lgb_params = {
'learning_rate': 0.1,
'n_estimators': 42,
'max_depth': 5,
'min_child_weight': 1,
'gamma': 0,
'subsample': 0.8,
'colsample_bytree': 0.8,
'objective': 'binary', # 這裡和 xgb 不一樣
'nthread': 4,
'scale_pos_weight': 1,
'seed': 112
}
lgb_model = LGBMClassifier(**lgb_params) # 迭代次數(n_estimators)已經是超參之一
# 訓練
lgb_model.fit(X_train_std, y_train)5. 模型調參
針對以上各個模型進行調參。使用 5折交叉驗證,評價標準使用 roc_auc。
# 設定評價標準
scoring = 'roc_auc' # 評價標準
n_fold = 5 # n折交叉驗證以下針對各個模型進行網格調參:
# LR
lr_param = {
'C': [0.05, 0.1, 0.5, 1],
'penalty': ['l1', 'l2'],
}
lr_grid = GridSearchCV(lr, lr_param, cv=n_fold, scoring=scoring, n_jobs=-1)
lr_grid.fit(X_train_std, y_train)
print(lr_grid.best_score_) # 最優分數
print(lr_grid.best_params_) # 最優引數
print(lr_grid.cv_results_) # 結果
# 把引數重新賦值給原模型
lr.set_params(**lr_grid.best_params_)
lr.fit(X_train_std, y_train)
# 線性SVC 如果一次性設定的引數太多,可能會跑很長時間,這個時候,建議使用貪心的方法,在某個引數調到最優的時候再調另一個引數
linear_svc_param = {
# 'kernel': ['linear', 'poly']
'C': [0.5, 1, 5],
# 'degree': [2, 3]
}
linear_svc_grid = GridSearchCV(linear_svc, linear_svc_param, cv=n_fold, scoring=scoring, n_jobs=-1)
linear_svc_grid.fit(X_train_std, y_train)
print(linear_svc_grid.best_score_) # 最優分數
print(linear_svc_grid.best_params_) # 最優引數
# 把引數重新賦值給原模型
linear_svc.set_params(**linear_svc_grid.best_params_)
linear_svc.fit(X_train_std, y_train)
# 多項式SVC
poly_svc_param = {
'C': [0.5, 1, 5],
'degree': [2, 3]
}
poly_svc_grid = GridSearchCV(poly_svc, poly_svc_param, cv=n_fold, scoring=scoring, n_jobs=-1)
poly_svc_grid.fit(X_train_std, y_train)
print(poly_svc_grid.best_score_) # 最優分數
print(poly_svc_grid.best_params_) # 最優引數
# 把引數重新賦值給原模型
poly_svc.set_params(**svc_grid.best_params_)
poly_svc.fit(X_train_std, y_train)
# 決策樹 關於決策樹引數較多,可參考:https://blog.csdn.net/qq_41577045/article/details/79844709
dt_param = {
'max_depth': [3, 4, 5, 6, 7,],
}
dt_grid = GridSearchCV(dt, dt_param, cv=n_fold, scoring=scoring, n_jobs=-1)
dt_grid.fit(X_train_std, y_train)
print(dt_grid.best_score_) # 最優分數
print(dt_grid.best_params_) # 最優引數
# 把引數重新賦值給原模型
dt.set_params(**dt_grid.best_params_)
dt.fit(X_train_std, y_train)PS:上面調整的均是比較常見的超參,其他引數請參考官方文件。決策樹中涉及引數較多,對不同資料集調節引數不一,詳細可參考 sklearn種決策樹的演算法引數。另外,XGBoost 與 LightGBM 模型比較複雜,調參過程中涉及的步驟較多,可參考另一篇博文:XGBoost 與 LightGBM 調參
6. 效能評估
評估函式程式碼:
from sklearn.metrics import accuracy_score, recall_score, f1_score, roc_auc_score, roc_curve
from matplotlib import pyplot as plt
# 定義評估函式
def model_metrics(clf, X_train, X_test, y_train, y_test):
# 預測
y_train_pred = clf.predict(X_train)
y_test_pred = clf.predict(X_test)
y_train_pred_proba = clf.predict_proba(X_train)[:, 1]
y_test_pred_proba = clf.predict_proba(X_test)[:, 1]
# 評估
# 準確性
print('準確性:')
print('Train:{:.4f}'.format(accuracy_score(y_train, y_train_pred)))
print('Test:{:.4f}'.format(accuracy_score(y_test, y_test_pred)))
# 召回率
print('召回率:')
print('Train:{:.4f}'.format(recall_score(y_train, y_train_pred)))
print('Test:{:.4f}'.format(recall_score(y_test, y_test_pred)))
# f1_score
print('f1_score:')
print('Train:{:.4f}'.format(f1_score(y_train, y_train_pred)))
print('Test:{:.4f}'.format(f1_score(y_test, y_test_pred)))
# roc_auc
print('roc_auc:')
print('Train:{:.4f}'.format(roc_auc_score(y_train, y_train_pred_proba)))
print('Test:{:.4f}'.format(roc_auc_score(y_test, y_test_pred_proba)))
# 描繪 ROC 曲線
fpr_tr, tpr_tr, _ = roc_curve(y_train, y_train_pred_proba)
fpr_te, tpr_te, _ = roc_curve(y_test, y_test_pred_proba)
# KS
print('KS:')
print('Train:{:.4f}'.format(max(abs((fpr_tr - tpr_tr)))))
print('Test:{:.4f}'.format(max(abs((fpr_te - tpr_te)))))
# 繪圖
plt.plot(fpr_tr, tpr_tr, 'r-',
7label="Train:AUC: {:.3f} KS:{:.3f}".format(roc_auc_score(y_train, y_train_pred_proba),
max(abs((fpr_tr - tpr_tr)))))
plt.plot(fpr_te, tpr_te, 'g-',
label="Test:AUC: {:.3f} KS:{:.3f}".format(roc_auc_score(y_test, y_test_pred_proba),
max(abs((fpr_tr - tpr_tr)))))
plt.plot([0, 1], [0, 1], 'd--')
plt.legend(loc='best')
plt.title("ROC curse")
plt.show()下面是各個模型的評估函式結果:
| accuracy | recall | f1_score | ROC_AUC | KS | ROC曲線 | |
|
邏輯迴歸 |
Train:0.7986 Test:0.8031 |
Train:0.3198 Test:0.3324 |
Train:0.4444 Test:0.4565 |
Train:0.4444 Test:0.4565 |
Train:0.4564 Test:0.4576 |
 |
| 線性SVM | Train:0.7944 Test:0.7975 |
Train:0.2542 Test:0.2676 |
Train:0.3838 Test:0.3967 |
Train:0.8082 Test:0.7894 |
Train:0.4796 Test:0.4575 |
 |
| 多項式SVM | Train:0.8245 Test:0.7687 |
Train:0.3079 Test:0.1577 |
Train:0.4691 Test:0.2534 |
Train:0.9511 Test:0.7172 |
Train:0.8093 Test:0.3552 |
 |
| 決策樹 | Train:0.8777 Test:0.7526 |
Train:0.6539 Test:0.4085 |
Train:0.7292 Test:0.4510 |
Train:0.9016 Test:0.6573 |
Train:0.6550 Test:0.3018 |
 |
| Xgboost | Train:0.8798 Test:0.7940 |
Train:0.5644 Test:0.3690 |
Train:0.7028 Test:0.4712 |
Train:0.9525 Test:0.7932 |
Train:0.7644 Test:0.4342 |
 |
| LightGBM | Train:0.8843 Test:0.7996 |
Train:0.5776 Test:0.3634 |
Train:0.7154 Test:0.4743 |
Train:0.9571 Test:0.7991 |
Train:0.7776 Test:0.4548 |
 |
7. 模型融合
關於 Stacking 的原理這裡就不細說了,具體參考 stacking 模型融合
為了貫徹調包俠的理念,這裡直接呼叫 mlxtend 庫裡面的 StackingCVClassifier 進行建模,這個庫可以很好地完成對 sklearn 的 stacking。
from mlxtend.classifier import StackingCVClassifier, StackingClassifier
# 構建 Stacking 模型,因為 dt 評分太低了,所以拋棄掉,使用 lr 作為最後的融合模型
s_clf = StackingClassifier(classifiers=[linear_svc, xgb_model, lgb_model],
meta_classifier=lr, use_probas=True, verbose=3)
s_clf.fit(X_train_std, y_train)下面我們呼叫上面定義好的函式,看一下模型融合之後的結果:
# 評估 Stacking 模型
model_metrics(s_clf, X_train_std, X_test_std, y_train, y_test)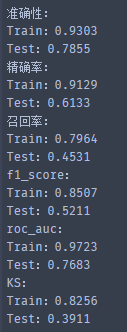

可以看到,進行模型融合之後,結果並不比原來的 xgb 和 lgb 好,也許模型融合對當前題目並不是一個很好的解決方案。
遇到的問題
1. SVM 使用 rbf 核時,分類結果只有一類
2. 進行模型融合後的結果並沒有比原來好