
通過numpy實現bp網路完成mnist任務
阿新 • • 發佈:2019-02-13
本網路採用含有一個隱含層的BP神經網路,隱含層後面接一個sigmoid函式,輸出層後面也接一個sigmoid函式。下面貼出程式碼進行分享。首先這個網路是最最傳統的BP網路,同時batch_size為1,這段程式碼後面會貼一段改進後的程式碼,可以設定batch_size。
#coding=utf-8 import numpy as np import os from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("data/mnist_data", one_hot=True) # 定義網路超引數 learning_rate = 0.001 training_iters = 1000000 calc_accurary_step = 20 # 定義網路引數 n_input = 784# 輸入的維度 n_output = 10 # 標籤的維度 n_hidden = 80 # 隱含層節點數 train_num = mnist.train.labels.shape[0] test_num = mnist.test.labels.shape[0] class BPNetwork(object): def __init__(self,input_nodes,hidden_nodes,output_nodes,learning_rate): self.input_nodes=input_nodes self.hidden_nodes=hidden_nodes self.output_nodes=output_nodes #initialize weights self.weights_input_to_hidden = np.random.normal(0.0, self.hidden_nodes**-0.5,( self.hidden_nodes, self.input_nodes)) self.weights_hidden_to_output = np.random.normal(0.0, self.output_nodes**-0.5,(self.output_nodes, self.hidden_nodes)) self.baises_input_to_hidden = np.random.normal(0.0, self.hidden_nodes**-0.5,( self.hidden_nodes, 1 )) self.baises_hidden_to_output = np.random.normal(0.0, self.output_nodes**-0.5,(self.output_nodes, 1 )) self.lr = learning_rate #Activation function is the sigmoid function self.activation_function = (lambda x: 1/(1 + np.exp(-x))) def train(self, inputs_list, targets_list): # Convert inputs list to 2d array inputs = np.array(inputs_list, ndmin=2).T # 輸入向量的shape為 [feature_diemension, 1] targets = np.array(targets_list, ndmin=2).T # 向前傳播,Forward pass # TODO: Hidden layer hidden_inputs = np.dot(self.weights_input_to_hidden, inputs) + self.baises_input_to_hidden # signals into hidden layer hidden_outputs = self.activation_function(hidden_inputs) # signals from hidden layer # 輸出層,輸出層的激勵函式就是 sigmoid final_inputs = np.dot(self.weights_hidden_to_output, hidden_outputs) + self.baises_hidden_to_output # signals into final output layer final_outputs = self.activation_function(final_inputs) # signals from final output layer ### 反向傳播 Backward pass,使用梯度下降對權重進行更新 ### # 輸出誤差 # Output layer error is the difference between desired target and actual output. output_errors = final_outputs*(1-final_outputs)*(targets-final_outputs) hidden_errors = hidden_outputs*(1-hidden_outputs)*np.dot(self.weights_hidden_to_output.T , output_errors) # 更新權重/偏置 Update the weights # 更新隱藏層與輸出層之間的權重/偏置 update hidden-to-output weights with gradient descent step self.weights_hidden_to_output += np.dot(output_errors , hidden_outputs.T) * self.lr self.baises_hidden_to_output += output_errors * self.lr #更新輸入層與隱藏層之間的權重/偏置 self.weights_input_to_hidden += np.dot(hidden_errors , inputs.T) * self.lr self.baises_input_to_hidden += hidden_errors * self.lr loss = ((targets-final_outputs)*(targets-final_outputs)).sum() return loss def inference(self, inputs_list,targets_list): right = 0 for total in range(test_num): hidden_inputs = np.dot(self.weights_input_to_hidden, inputs_list[total]) + self.baises_input_to_hidden # signals into hidden layer hidden_outputs = self.activation_function(hidden_inputs) # signals from hidden layer # 輸出層,輸出層的激勵函式就是 sigmoid final_inputs = np.dot(self.weights_hidden_to_output, hidden_outputs) + self.baises_hidden_to_output # signals into final output layer final_outputs = self.activation_function(final_inputs) predict = final_outputs.tolist() label = targets_list[total].tolist() if predict.index(max(predict))==label.index(max(label)): right+=1 accurary = right/test_num return accurary if __name__ == '__main__': network = BPNetwork(n_input,n_hidden,n_output,learning_rate) for epoch in range(training_iters): for i in range (train_num): loss = network.train(mnist.train.images[i],mnist.train.labels[i]) print ("epoch ",epoch,", Loss= ",loss) if(epoch%calc_accurary_step == 0): accurary = network.inference(mnist.test.images,mnist.test.labels) print("Testing Accuracy:",accurary)
更新權重和閾值部分,分享如下推導,此處摘錄西瓜書部分推導,並結合程式碼進行反向傳播部分程式碼的解析。

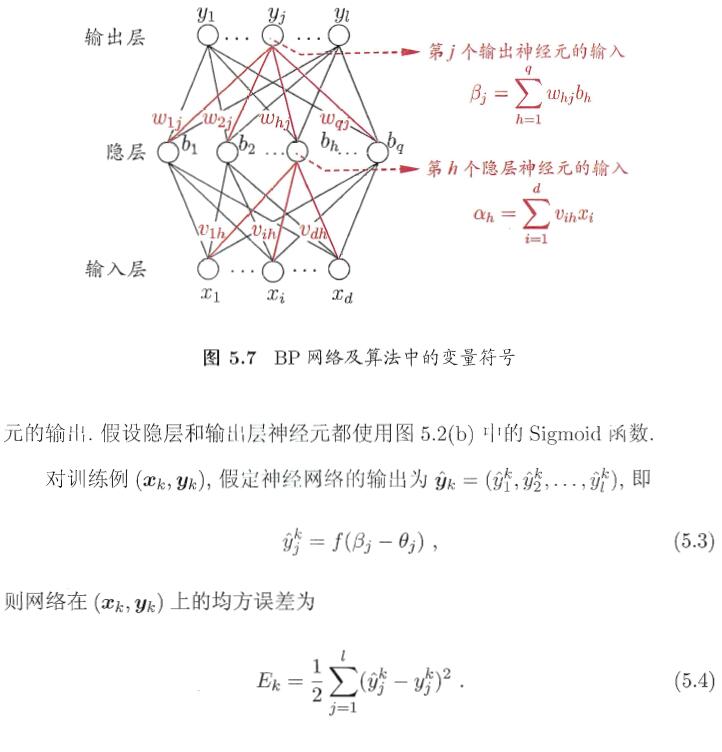




本程式碼中反向傳播部分程式碼中從隱含層到輸出層使用了5.10,5.11,5.12部分的公式,輸入層到隱含層部分使用了5.15, 5.13,5.12部分的公式
### 反向傳播 Backward pass,使用梯度下降對權重進行更新 ### # 輸出誤差 # Output layer error is the difference between desired target and actual output. output_errors = final_outputs*(1-final_outputs)*(targets-final_outputs) hidden_errors = hidden_outputs*(1-hidden_outputs)*np.dot(self.weights_hidden_to_output.T , output_errors) # 更新權重/偏置 Update the weights # 更新隱藏層與輸出層之間的權重/偏置 update hidden-to-output weights with gradient descent step self.weights_hidden_to_output += np.dot(output_errors , hidden_outputs.T) * self.lr self.baises_hidden_to_output += output_errors * self.lr #更新輸入層與隱藏層之間的權重/偏置 self.weights_input_to_hidden += np.dot(hidden_errors , inputs.T) * self.lr self.baises_input_to_hidden += hidden_errors * self.lr
output_errors和hidden_errors分別對應了式5.10和5.15,後面四句顯而易見分別對應了剩下的4條公式。
運算結果如下:
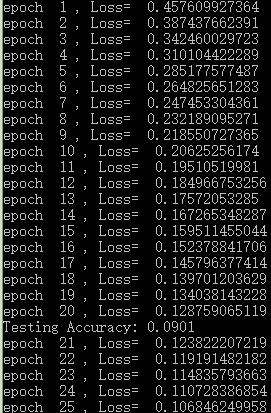
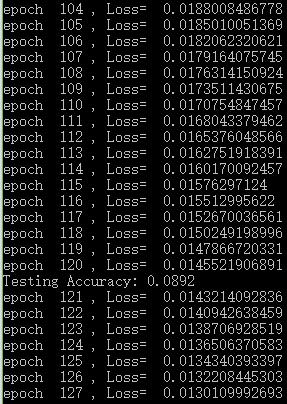
從結果來看,訓練確實收斂了,但是尷尬的是準確率越來越低……不過至少收斂代表了成功(騙自己……)
上述程式碼的batch_size只能為1,還不支援批量訓練,通過這個網站中介紹的增加batch_size的方法:
http://deeplearning.stanford.edu/wiki/index.php/%E5%8F%8D%E5%90%91%E4%BC%A0%E5%AF%BC%E7%AE%97%E6%B3%95

顯然在一個iter中,通過分別對batch_size中的所有資料分別進行反向傳播,得到的所有loss加到一起然後除以batch_size,最後以這個平均值進行引數更新,如下面v2版程式碼,同時增加了學習率根據epoch的增加而遞減的部分程式碼,完成了三層bp網路對mnist任務的實現。
#coding=utf-8
import numpy as np
import os
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("data/mnist_data", one_hot=True)
# 定義網路超引數
learning_rate = 0.0001
training_iters = 1000000
batch_size = 64
display_step = 20
# 定義網路引數
n_input = 784# 輸入的維度
n_output = 10 # 標籤的維度
n_hidden = 80 # 隱含層節點數
dropout = 0.8 # Dropout 的概率
calc_accurary_step = 10
train_num = mnist.train.labels.shape[0]
test_num = mnist.test.labels.shape[0]
class BPNetwork(object):
def __init__(self,input_nodes,hidden_nodes,output_nodes,learning_rate,batch_size):
self.input_nodes=input_nodes
self.hidden_nodes=hidden_nodes
self.output_nodes=output_nodes
self.batch_size=batch_size
#initialize weights
self.weights_input_to_hidden = np.random.normal(0.0, self.hidden_nodes**-0.5,( self.hidden_nodes, self.input_nodes))
self.weights_hidden_to_output = np.random.normal(0.0, self.output_nodes**-0.5,(self.output_nodes, self.hidden_nodes))
self.baises_input_to_hidden = np.random.normal(0.0, self.hidden_nodes**-0.5,( self.hidden_nodes, 1 ))
self.baises_hidden_to_output = np.random.normal(0.0, self.output_nodes**-0.5,(self.output_nodes, 1 ))
self.lr = learning_rate
#Activation function is the sigmoid function
self.activation_function = (lambda x: 1/(1 + np.exp(-x)))
def train(self, inputs_list, targets_list):
# Convert inputs list to 2d array
output_errors = np.zeros([self.output_nodes,1])
hidden_errors = np.zeros([self.hidden_nodes,1])
temp_weights_hidden_to_output = np.zeros([self.output_nodes, self.hidden_nodes])
temp_weights_input_to_hidden = np.zeros([self.hidden_nodes, self.input_nodes])
for i in range(self.batch_size):
inputs = np.array(inputs_list[i], ndmin=2).T # 輸入向量的shape為 [feature_diemension, 1]
targets = np.array(targets_list[i], ndmin=2).T
# 向前傳播,Forward pass
# TODO: Hidden layer
hidden_inputs = np.dot(self.weights_input_to_hidden, inputs) + self.baises_input_to_hidden # signals into hidden layer
hidden_outputs = self.activation_function(hidden_inputs) # signals from hidden layer
# 輸出層,輸出層的激勵函式就是 sigmoid
final_inputs = np.dot(self.weights_hidden_to_output, hidden_outputs) + self.baises_hidden_to_output # signals into final output layer
final_outputs = self.activation_function(final_inputs) # signals from final output layer
### 反向傳播 Backward pass,使用梯度下降對權重進行更新 ###
# 輸出誤差
# Output layer error is the difference between desired target and actual output.
output_errors += final_outputs*(1-final_outputs)*(targets-final_outputs)
hidden_errors += hidden_outputs*(1-hidden_outputs)*np.dot(self.weights_hidden_to_output.T , output_errors)
temp_weights_hidden_to_output += np.dot(output_errors , hidden_outputs.T)
temp_weights_input_to_hidden += np.dot(hidden_errors , inputs.T)
# 更新權重/偏置 Update the weights
# 更新隱藏層與輸出層之間的權重/偏置 update hidden-to-output weights with gradient descent step
self.weights_hidden_to_output += temp_weights_hidden_to_output * self.lr/self.batch_size
self.baises_hidden_to_output += output_errors * self.lr /self.batch_size
#更新輸入層與隱藏層之間的權重/偏置
self.weights_input_to_hidden += temp_weights_input_to_hidden * self.lr/self.batch_size
self.baises_input_to_hidden += hidden_errors * self.lr /self.batch_size
loss = ((targets-final_outputs)*(targets-final_outputs)).sum()
return loss
def inference(self, inputs_list,targets_list):
right = 0
for total in range(test_num):
hidden_inputs = np.dot(self.weights_input_to_hidden, inputs_list[total]) + self.baises_input_to_hidden # signals into hidden layer
hidden_outputs = self.activation_function(hidden_inputs) # signals from hidden layer
# 輸出層,輸出層的激勵函式就是 sigmoid
final_inputs = np.dot(self.weights_hidden_to_output, hidden_outputs) + self.baises_hidden_to_output # signals into final output layer
final_outputs = self.activation_function(final_inputs)
predict = final_outputs.tolist()
label = targets_list[total].tolist()
#print(predict.index(max(predict)),label.index(max(label)))
if predict.index(max(predict))==label.index(max(label)):
right+=1
accurary = right/test_num
return accurary
if __name__ == '__main__':
network = BPNetwork(n_input,n_hidden,n_output,learning_rate,batch_size)
for epoch in range(training_iters):
for i in range (1,int(train_num/batch_size)):
loss = network.train(mnist.train.images[batch_size*(i-1):batch_size*i],mnist.train.labels[batch_size*(i-1):batch_size*i])
print("epoch:",epoch,", Loss = ",loss)
if(epoch%calc_accurary_step == 0):
accurary = network.inference(mnist.test.images,mnist.test.labels)
print("Testing Accuracy:",accurary)
learning_rate*=0.99