
MySQL執行計劃理解與實踐
SQL執行過程和優化器
首先看一下MySQL中,一條sql的執行過程,這裡主要是引用了《高效能MySQL》中的內容:
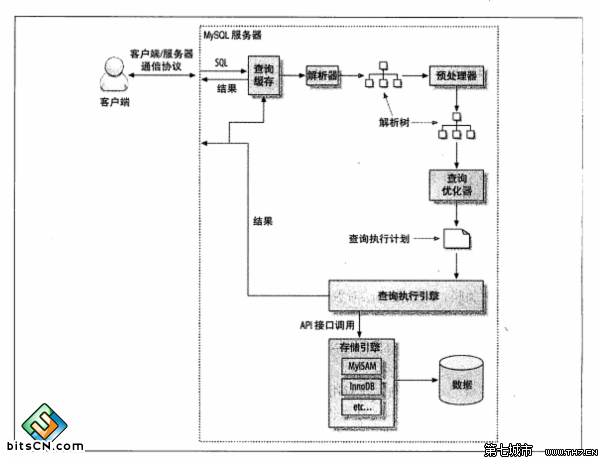
1、客戶端傳送一條查詢給伺服器
2、伺服器先檢查查詢快取,如果命中快取則立刻返回儲存在快取中的結果,否則進入下一階段。
3、伺服器端進行SQL解析、預處理,再由優化器生成對應的執行計劃。
4、MYSQL根據優化器生成的執行計劃呼叫儲存引擎的API來執行查詢
5、將結果返回給客戶端
對於mysql來說,底層的儲存引擎主要的工作就是對資料的磁碟檔案進行操作,上層的sql解析等操作主要放在伺服器層,伺服器層根據sql進行優化和解析生成執行計劃,最後儲存引擎根據執行計劃來呼叫資料,有機會一定要讀一下這個原始碼,體會一下這個過程。
tips:一個sql查詢往往有很多種方式,可以弄成子查詢,也可以用表連線,這個地方的選擇主要就是由優化器來負責。在oracle中,優化器主要有:
rbo:基於規則的優化器
cbo:基於代價的優化器
rbo已經被拋棄不使用了,目前主流使用基於代價的cbo。
基於代價就要計算代價,初始情況下,計算代價的最小單位就是隨機讀取一個4k頁面的成本,並選擇其中成本最小的執行計劃,後來引入了一些複雜的計算因子來計算某些操作的代價。機器畢竟是機器,很多情況下,cbo優化器也會發生優化不準確的情況,所以這也是為什麼需要了解執行過程的原因。
很多情況下都會導致優化器選擇了錯誤的執行計劃,並不能獲得最好的效能:
- 統計資訊不準確,mysql依賴儲存引擎提供的統計資訊來評估成本,但是有的儲存引擎提供的資訊是準確的,有的不準確
- 執行計劃中的成本估算不等同於實際執行的成本,因為MYSQL層面並不知道那些頁面在記憶體和磁碟上所以到底需要多少次物理IO未知。
- MySQL的最優化和你的最優化並不一樣(目標不同,可能你希望最少時間,MySQL優化目標是最大吞吐量)
- MYSQL不考慮併發查詢
- MYSQL並不是任何時候都基於成本優化
- MYSQL不會考慮不受其控制的操作的成本
檢視執行計劃
explain select xxx from xxx; 
上面這是最簡單的執行計劃例項,來分析一下上面的這幾個欄位。
- id :id主要是用來標識sql執行順序,如果沒有子查詢,一般來說id只有1個,執行順序也是從上到下。
- select_type:每個select子句的型別,主要分成下面幾種:
a:SIMPLE:查詢中不包含任何子查詢或者union
b:PRIMARY:查詢中包含了任何複雜的子部分,最外層的就會變成PRIMARY
c:SUBQUERY:在SELECT或者WHERE列表中包含了子查詢
d:DERIVED:在FROM中包含了子查詢
e:UNION:如果第二個SELECT出現在UNION之後,則被標記為UNION,如果UNION包含在FROM子句的子查詢中,外層SELECT會被標記為:DERIVED
f:UNION RESULT從UNION表獲取結果的select
type:是指MySQL在表中找到所需行的方式,也就是訪問行的”型別”,從a開始,效率逐漸上升:
a:all:全表掃描,效率最低
b:index:index會根據索引樹遍歷
c:range:索引範圍掃描,返回匹配值域的行。
d:ref:非唯一性索引掃描,返回匹配某個單獨值的所有行。一般是指多列的唯一索引中的某一列。
e:eq_ref:唯一性索引掃描,表中只有一條記錄與之匹配。
f:const、system:主要針對查詢中有常量的情況,如果結果只有一行會變成system
g:NULL:顯而易見,既不走表,也不走索引
possible_keys
possible_keys列預估了mysql能夠為當前查詢選擇的索引,這個欄位是完全獨立於執行計劃中輸出的表的順序,意味著在實際查詢中可能用不到這些索引。
如果該欄位為空則意味著沒有可使用的索引,這個時候你可以考慮為where後面的欄位建立索引
key
這個欄位表示了mysql真實使用的索引。如果mysql優化過程中沒有加索引,可以強制加hint使用索引
key_len
索引長度欄位顧名思義,表示了mysql使用的索引的長度.
ref
這個欄位一般是指一些常量用於選擇過濾
rows
預估結果集的條數,可能不一定完全準確
實踐測試
這裡取資料庫中最經典的employees庫作為例子,兩張表,一張employees僱員表,一張salaries薪水錶:
`explain select e.birth_date,s.salary from employees e right join salaries s on e.emp_no = s.emp_no;`
這是一個兩個表連線的查詢。
執行計劃如下:

一個一個來,首先在id相同的情況下,從上往下執行。這是一個右連線查詢,以右邊為基準,右邊的每一行去匹配左邊的表,所以首先右邊進行s表全表掃描,type為ALL,沒有走索引。同時兩次查詢都是簡單查詢,沒有子查詢,所以select_type都是simple。
接著是對e表進行查詢,type為eq_ref,因為emp_no是主鍵,唯一性掃描,possible_keys和key都是primary,每次都針對前面的記錄掃出對應的一行。