
集合系列--HashMap實現詳解
1、HashMap特點
HashMap是基於雜湊表的map介面的非同步實現,key不可重複,但value可以,其中key和value都可以為空,且此類不保證對映的順序,特別是它不保證該順序恆久不變。
2、HashMap的資料結構
hashmap 是一個連結串列雜湊的資料結構,即陣列和連結串列的結合體,對於是怎樣結合,我們首先看一下hashmap 的原始碼:
/** * The table, resized as necessary. Length MUST Always be a power of two. */ transient Entry[] table; static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; final int hash; …… }
當建立一個HashMap是,系統會自動的建立一個table陣列來儲存HashMap中的鍵值對,並持有指向下一個元素的引用,這樣就構成了連結串列,我們看一下HashMap的儲存實現:當系統呼叫HashMap的put方法儲存元素 eg:
hashMap.put("語文",80.0);
當程式執行這句話時,系統將呼叫“語文“的hashCode()方法得到其hashCode值,然後根據hashCode的值來決定該元素的儲存位置,我們來看一下HashMap的put實現:
public V put(K key, V value) { // HashMap允許存放null鍵和null值。 // 當key為null時,呼叫putForNullKey方法,將value放置在陣列第一個位置。 if (key == null) return putForNullKey(value); // 根據key的keyCode重新計算hash值。 int hash = hash(key.hashCode()); // 搜尋指定hash值在對應table中的索引。 int i = indexFor(hash, table.length); // 如果 i 索引處的 Entry 不為 null,通過迴圈不斷遍歷 e 元素的下一個元素。 for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } // 如果i索引處的Entry為null,表明此處還沒有Entry。 modCount++; // 將key、value新增到i索引處。 addEntry(hash, key, value, i); return null; }
從put原始碼可以看出,將一個key-value存入HashMap中時,會先根據key的hashCode()的返回值決定entry的儲存位置,如果兩個entry的hashCode()相同,那麼他們的儲存位置相同,然後比較兩個entry是否equals,如果equals的結果返回true,則新新增的entry的value值將會覆蓋原entry的value值,但key將不變,如果返回false,新新增的entry將會指向原entry形成連結串列,新新增的entry將會位於entry鏈的頭部,其中addEntry方法根據計算出的hash值將entry儲存在table的i索引出,我們來看一下addEntry(hash,key,value,i)的原始碼:
void addEntry(int hash, K key, V value, int bucketIndex) {
// 獲取指定 bucketIndex 索引處的 Entry
Entry<K,V> e = table[bucketIndex];
// 將新建立的 Entry 放入 bucketIndex 索引處,並讓新的 Entry 指向原來的 Entry
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
// 如果 Map 中的 key-value 對的數量超過了極限
if (size++ >= threshold)
// 把 table 物件的長度擴充到原來的2倍。
resize(2 * table.length);
}
從原始碼可以看出,系統總是將新加入的Entry物件放在table陣列的bucketIndex索引處,如果該索引出沒有物件,則新放入的Entry物件將指向該索引,如果該索引出已經有其他Entry物件,則新新增的Entry將指向原來的Entry形成Entry鏈如圖:
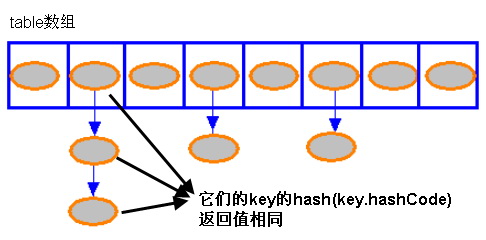
3、HashMap的效能
首先看一下HashMap的構造方法:
HashMap();構造一個廚師容量為16,負載因子為0.75的HashMap
HashMap(int initialCapacity);構建一個初始容量為initialCapacity,負載因子為0.75的HashMap
HashMap(int initialCapacity,float loadFactor);構建一個初始容量為initialCapacity,負載因子為loadFactor的HashMap
我們來看一下第三個建構函式的原始碼:
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}
由
while (capacity < initialCapacity) capacity <<= 1;可以看出,HashMap的實際容量並不一定是指定的initialcapacity,他們只有當所指定的大小為2的n次冪的時候才相等,如果所指定的大小不為2的n次冪時,實際容量為大於所指定容量的最小的2的n次冪值。比如所指定的容量大小為5,那麼實際容量為大於5的最小的2的n次冪值為8,所以HashMap的實際容量為8,。
對於預設的負載因子為0.75,這是時間和空間成本上的一種折中,增大負載因子可以減少hash表(Entry陣列)所佔用的記憶體空間,但會增加查詢資料的時間開銷,減少負載因子會提高資料查詢效能,但會增加hash表所佔用的記憶體空間。
在HashMap中通過threshold欄位來判斷HashMap的最大容量
threshold = (int)(capacity * loadFactor);
threshold就是在此loadFactor和capacity對應下允許的最大元素數目,超過這個數目就重新resize,將陣列擴充為原來的一倍:
if (size++ >= threshold)
resize(2 * table.length); 比如說:原容量為16,負載因子為0.75,那麼
threshold = 16*0.75 = 12,也就是說,當HashMap中元素個數超過12時,就把陣列擴充為16*2 = 32,這樣是比較耗效能的,他得重新計算各個元素在陣列中的位置。
4、HashMap的讀取實現
當 HashMap 的每個 bucket 裡儲存的 Entry 只是單個 Entry ——也就是沒有通過指標產生 Entry 鏈時,此時的 HashMap 具有最好的效能:當程式通過 key 取出對應 value 時,系統只要先計算出該 key 的 hashCode() 返回值,在根據該 hashCode 返回值找出該 key 在 table 陣列中的索引,然後取出該索引處的 Entry,最後返回該 key 對應的 value 即可。看 HashMap 類的 get(K key) 方法程式碼:
public V get(Object key)
{
// 如果 key 是 null,呼叫 getForNullKey 取出對應的 value
if (key == null)
return getForNullKey();
// 根據該 key 的 hashCode 值計算它的 hash 碼
int hash = hash(key.hashCode());
// 直接取出 table 陣列中指定索引處的值,
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
// 搜尋該 Entry 鏈的下一個 Entr
e = e.next) // ①
{
Object k;
// 如果該 Entry 的 key 與被搜尋 key 相同
if (e.hash == hash && ((k = e.key) == key
|| key.equals(k)))
return e.value;
}
return null;
}
從上面程式碼中可以看出,如果 HashMap 的每個 bucket 裡只有一個 Entry 時,HashMap 可以根據索引、快速地取出該 bucket 裡的 Entry;在發生“Hash 衝突”的情況下,單個 bucket 裡儲存的不是一個 Entry,而是一個 Entry 鏈,系統只能必須按順序遍歷每個 Entry,直到找到想搜尋的 Entry 為止——如果恰好要搜尋的 Entry 位於該 Entry 鏈的最末端(該 Entry 是最早放入該 bucket 中),那系統必須迴圈到最後才能找到該元素。