
Guava之CaseFormat(駝峰命名法或其他命名轉換字元工具)
阿新 • • 發佈:2019-02-14
com.google.common.base.CaseFormat是一種實用工具類,以提供不同的ASCII字元格式之間的轉換。
其對應的列舉常量

從以上列舉中可以看出,java程式設計師最常用的轉換型別為:UPPER_CAMEL,即我們常說的“駝峰式”編寫方式;其次,我們常用的是:UPPER_UNDERSCORE,即我們常用的常量命名法,不同單詞見使用下劃線分割的書寫方式。
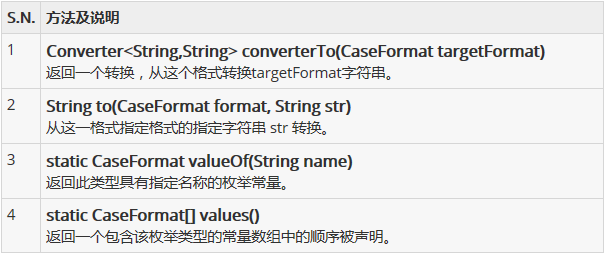
對應有的方法
CaseFormat 示例

public static void main(String args[]) { CaseFormatTest tester = newCaseFormatTest(); tester.testCaseFormat(); } private void testCaseFormat() { System.out.println(CaseFormat.LOWER_HYPHEN.to(CaseFormat.LOWER_CAMEL, "test-data")); System.out.println(CaseFormat.LOWER_UNDERSCORE.to(CaseFormat.LOWER_CAMEL, "test_data")); System.out.println(CaseFormat.UPPER_UNDERSCORE.to(CaseFormat.UPPER_CAMEL, "test_data")); System.out.println(CaseFormat.LOWER_CAMEL.to(CaseFormat.LOWER_UNDERSCORE, "testdata")); System.out.println(CaseFormat.LOWER_CAMEL.to(CaseFormat.LOWER_UNDERSCORE, "TestData")); System.out.println(CaseFormat.LOWER_CAMEL.to(CaseFormat.LOWER_HYPHEN, "testData")); }
執行結果如下:
?| 123 | testDatatestDataTestData<br><br>testdata<br>test_data<br>test-data |
從以上結果我們可以分析,倒數第3個結果沒有轉換成功,將原字串打印出來,推匯出guava不可能做到那麼智慧,能夠自動識別一個單詞之後將兩個單詞用下劃線分隔開(要想做也是可以的,需要將英文詞庫載入一遍,之後每次掃描給定的字串進行單詞分割,這樣做就太複雜了),它只能通過給定字串大小寫的方式或者上面3個例項有分隔符的方式才能拆分開,故倒數第二個就能正確識別出來。所以在使用guava轉換的時候一定要注意了。