
淺談pandas,pyspark 的大資料ETL實踐經驗
作者:王雅寧
轉載自:
0.序言
本文主要以基於AWS 搭建的EMR spark 託管叢集,使用pandas pyspark 對合作單位的業務資料進行ETL ---- EXTRACT(抽取)、TRANSFORM(轉換)、LOAD(載入) 等工作為例介紹大資料資料預處理的實踐經驗,很多初學的朋友對大資料探勘,資料分析第一直觀的印象,都只是業務模型,以及組成模型背後的各種演算法原理。往往忽視了整個業務場景建模過程中,看似最普通,卻又最精髓的資料預處理或者叫資料清洗過程。
1. 資料接入
我們經常提到的ETL是將業務系統的資料經過抽取、清洗轉換之後載入到資料倉庫的過程,首先第一步就是根據不同來源的資料進行資料接入,主要接入方式有三:
- 1.批量資料
可以考慮採用使用備份資料庫匯出dmp,通過ftp等多種方式傳送,首先接入樣本資料,進行分析 - 2.增量資料
考慮使用ftp,http等服務配合指令碼完成 - 2.實時資料
訊息佇列接入,kafka,rabbitMQ 等
資料接入對應ETL 中的E----EXTRACT(抽取),接入過程中面臨多種資料來源,不同格式,不同平臺,資料吞吐量,網路頻寬等多種挑戰。
python 這種膠水語言天然可以對應這類多樣性的任務,當然如果不想程式設計,還有:Talend,Kettle,Informatica,Inaplex Inaport等工具可以使用.
e.g. 一個kettle 的作業流
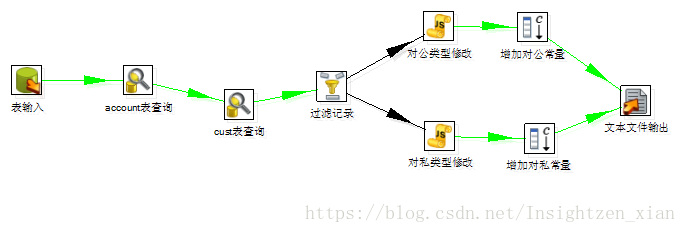
以上不是本文重點,不同資料來源的匯入匯出可以參考:
我們從資料接入以後的內容開始談起。
2. 髒資料的清洗
比如在使用Oracle等資料庫匯出csv file時,欄位間的分隔符為英文逗號,欄位用英文雙引號引起來,我們通常使用大資料工具將這些資料載入成表格的形式,pandas ,spark中都叫做dataframe
對與欄位中含有逗號,回車等情況,pandas 是完全可以handle 的,spark也可以但是2.2之前和gbk解碼共同作用會有bug
資料樣例
1,2,3
"a","b,
c","d"
"4","6,7","8"
pandas
# -*- coding:utf-8 -*-
"""@author: 
pyspark
sdf = spark.read.option("header","true") \
.option("charset","gbk") \
.option("multiLine", "true") \
.csv("s3a://your_file*.csv")
pdf = sdf.limit(1000).toPandas()
linux 命令
強大的sed命令,去除兩個雙引號中的換行
**處理結果放入新檔案**
sed ':x;N;s/\nPO/ PO/;b x' INPUTFILE > OUTPUTFILE
**處理結果覆蓋原始檔**
sed -i ':x;N;s/\nPO/ PO/;b x' INPUTFILE
2.1 檔案轉碼
當然,有些情況還有由於檔案編碼造成的亂碼情況,這時候就輪到linux命令大顯神威了。
比如 使用enconv 將檔案由漢字編碼轉換成utf-8
enconv -L zh_CN -x UTF-8 filename
或者要把當前目錄下的所有檔案都轉成utf-8
enca -L zh_CN -x utf-8 *
在Linux中專門提供了一種工具convmv進行檔名編碼的轉換,可以將檔名從GBK轉換成UTF-8編碼,或者從UTF-8轉換到GBK。
下面看一下convmv的具體用法:
convmv -f 源編碼 -t 新編碼 [選項] 檔名
#將目錄下所有檔名由gbk轉換為utf-8
convmv -f GBK -t UTF-8 -r --nosmart --notest /your_directory
2.2 指定列名
在spark 中
如何把別的dataframe已有的schame加到現有的dataframe 上呢?
from pyspark.sql.types import *
diagnosis_sdf_new = diagnosis_sdf.rdd.toDF(diagnosis_sdf_tmp.schema)
3. 缺失值的處理
pandas
pandas使用浮點值NaN(Not a Number)表示浮點數和非浮點陣列中的缺失值,同時python內建None值也會被當作是缺失值。
如果其中有值為None,Series會輸出None,而DataFrame會輸出NaN,但是對空值判斷沒有影響。DataFrame使用isnull方法在輸出空值的時候全為NaN
例如對於樣本資料中的年齡欄位,替換缺失值,並進行離群值清洗
pdf["AGE"] = pd.to_numeric(pdf["AGE"],"coerce").fillna(500.0).astype("int")
pdf[(pdf["AGE"] > 0) & (pdf["AGE"] < 150)]
自定義過濾器過濾
#Fix gender
def fix_gender(x):
if x is None:
return None
if "男" in x:
return "M"
if "女" in x:
return "F"
pdf["PI_SEX"] = pdf["PI_SEX"].map(fix_gender)
or
pdf["PI_SEX"] = pdf["PI_SEX"].apply(fix_gender)
或者直接刪除有缺失值的行
data.dropna()
pyspark
spark 同樣提供了,.dropna(…) ,.fillna(…) 等方法,是丟棄還是使用均值,方差等值進行填充就需要針對具體業務具體分析了
#檢視application_sdf每一列缺失值百分比
import pyspark.sql.functions as fn
queshi_sdf = application_sdf.agg(*[(1-(fn.count(c) /fn.count('*'))).alias(c+'_missing') for c in application_sdf.columns])
queshi_pdf = queshi_sdf.toPandas()
queshi_pdf
4. 資料質量核查與基本的資料統計
對於多來源場景下的資料,需要敏銳的發現數據的各類特徵,為後續機器學習等業務提供充分的理解,以上這些是離不開資料的統計和質量核查工作,也就是業界常說的讓資料自己說話。
##4.1 統一單位
多來源資料 ,突出存在的一個問題是單位不統一,比如度量衡,國際標準是米,然而很多北美國際習慣使用英尺等單位,這就需要我們使用自定義函式,進行單位的統一換算。
4.2 去重操作
pandas
去重操作可以幫助我們統計業務的核心資料,從而迅速抓住主要矛盾。例如,對於網際網路公司來說,每天有很多的業務資料,然而發現其中的獨立個體的獨立行為才是資料分析人員應該注意的點。
data.drop_duplicates(['column'])
pyspark
使用dataframe api 進行去除操作和pandas 比較類似
sdf.select("column1","column2").dropDuplicates()
當然如果資料量大的話,可以在spark環境中算好再轉化到pandas的dataframe中,利用pandas豐富的統計api 進行進一步的分析。
pdf = sdf.select("column1","column2").dropDuplicates().toPandas()
使用spark sql,其實我覺的這個spark sql 對於傳統的資料庫dba 等分析師來說簡直是革命性產品, 例如:如下程式碼統計1到100測試中每一個測試次數的人員分佈情況
count_sdf.createOrReplaceTempView("testnumber")
count_sdf_testnumber = spark.sql("\
SELECT tests_count,count(1) FROM \
testnumber where tests_count < 100 and lab_tests_count > 0 \
group by tests_count \
order by count(1) desc")
count_sdf_testnumber.show()
4.3 聚合操作與統計
pyspark 和pandas 都提供了類似sql 中的groupby 以及distinct 等操作的api,使用起來也大同小異,下面是對一些樣本資料按照姓名,性別進行聚合操作的程式碼例項
sdf.groupBy("SEX").agg(F.count("NAME")).show()
labtest_count_sdf = sdf.groupBy("NAME","SEX","PI_AGE").agg(F.countDistinct("CODE").alias("tests_count"))
順帶一句,pyspark 跑出的sql 結果集合,使用toPandas() 轉換為pandas 的dataframe 之後只要通過引入matplotlib, 就能完成一個簡單的視覺化demo 了。

d2 = pd.DataFrame({
'label': [1,2,3],
'count': [10,2,3],})
d2.plot(kind='bar')
plt.show()
d2.plot.pie(labels=['1', '2', '3'],subplots=True, figsize=(8, 4))
plt.show()
直方圖,餅圖


相關推薦
淺談pandas,pyspark 的大資料ETL實踐經驗
作者:王雅寧 轉載自: 0.序言 本文主要以基於AWS 搭建的EMR spark 託管叢集,使用pandas pyspark 對合作單位的業務資料進行ETL ---- EXTRACT(抽取)、TRANSFORM(轉換)、LOAD(載入) 等工作為例介紹大
大資料ETL實踐探索(3)---- pyspark 之大資料ETL利器
5.spark dataframe 資料匯入Elasticsearch 5.1 dataframe 及環境初始化 初始化, spark 第三方網站下載包:elasticsearch-spark-20_2.11-6.1.1.jar http://spark.apache.org/t
大資料ETL實踐探索(4)---- 之 搜尋神器elastic search
3.本地檔案匯入aws elastic search 修改訪問策略,設定本地電腦的公網ip,這個經常會變化,每次使用時候需要設定一下 安裝anancota https://www.anaconda.com/download/ 初始化環境,win10下開啟Anaco
大資料ETL實踐探索(1)---- python 與oracle資料庫匯入匯出
文章大綱 ETL 簡介 工具的選擇 1. oracle資料泵 匯入匯出實戰 1.1 資料庫建立 1.2. installs Oracle 1.3 export / import data from oracle
大資料ETL實踐探索(2)---- python 與aws 互動
文章大綱 本文主要使用python基於oracle和aws 相關元件進行一些基本的資料匯入匯出實戰,oracle使用資料泵impdp進行匯入操作,aws使用awscli進行上傳下載操作。本地檔案上傳至aws es,spark dataframe錄
專訪唐宇迪博士:我是如何邁入同濟大學校園的?淺談人工智慧,未來資料探勘和計算機視覺是風口
1.網上很多同學對老師您的簡歷非常好奇,在百度搜索上發現大家都很關心“唐宇迪是哪個學校畢業的”?關於您的學習經歷能簡單說下嗎? 唐宇迪:幾年前第一次邁進同濟大學校園,攻讀博士學位,並加入了資料探勘專案組,以此真正開始了機器學習之旅。學習的過程有些枯燥在所難免,但是想著可以將演算法應用於實驗當中,
避免超時方法二 :優化資料輸入,淺談getchar,cin,scanf,fread
做ACM的題目時候,輸入輸出是很重要的,特別輸入的數字很多的時候,很容易影響整個程式的執行時間,下面淺淡C語言c++的輸入。1.最基礎的當然是scanf,這裡跟getchar一起講。我一開始很疑惑,使用scanf ("%s",&s)將一個字串讀入s和用getchar一
淺談cookie,sessionStorage和localStorage區別
一次 flash htm ddb coo 清除 rem 限制 web服務器 在客戶端存儲數據可以使用的技術有如下四種: Cookie技術:瀏覽器兼容性好,但操作比較復雜,需要程序員自己封裝,源生的Cookie接口不友好 H5 WebStorage:不能超過8
淺談演算法,一些感悟(1)
最近看到好幾個同學在學演算法,看了一些書,另外跟一個演算法較好的同學討論了一下,若有所悟,作此文,以求各位大神指教; 現在看到好多同學學演算法,可是,事實上看起來,真正明白理解了演算法是一種什麼東西的極少,很多都是為了參加ACM而去學演算法,並沒有對演算法有真正意義上的研究,甚至說,他們拿到了ACM的入場
大資料揭祕: 原來單身女生有這些特點...,掌握大資料,你遠遠不止會這些
據媒體報道,中國目前的單身成年女性的數量已經超過一個多億,也就是說14.3%的成年女性處於單身狀態,與日本全國人口總數基本相當。 知己知彼,百戰不殆。如果你是一個單身女性,你可以看到自己的某些影子;如果是單身男生,你需要了解目標人群的特點;如果是已婚男士,要相信“天下鳳凰一般美!!!” 說 明 開始本文
建立大資料業務的全域性觀,瞭解大資料專案上下游
很多大資料的從業者,都清楚的知道,在大資料公司裡,或者是大資料的專案裡,都設有獨立的資料部門,而且如果部門內的的人員規模足夠大的話,還會進一步考慮劃分成幾個小組,比如BI、大資料、資料產品和UED,甚至還可能會有資料探勘組、爬蟲組。大家各盡其責,在自己的崗位上相互獨立的去工作,雖然經常會遇到「資料專
對自己最大的殘忍就是放縱,學習大資料你需要“堅持”
現在的生活有著高標準,你卻自己卻超級放縱,一面抱怨著自己不堪重負,一面卻賴在床上、紮在手機裡不肯行動,所以,你會迷茫,你會困惑,你會感到這個世界對你的殘忍。其實,這些殘忍都是你自己放縱所致。古人云:“修身齊家治國平天下”,你修身了嗎?你堅持了嗎? 終身學
js使用百度地圖僅顯示中國區域,實現大資料熱點圖
需求:領導需要在年會上展示我們的使用者ip實時資料,做一個網頁版的地圖,僅僅顯示中國區域。 技術分析:echart,hchart等網站都有地圖版的,百度地圖有熱點例項,經過對比,我選用了百度地圖,但是百度地圖無法只顯示中國區域,這個時候就需要我來動動手解決掉最後一關。 應評論的各位想要原始碼
UART串列埠通訊淺談之(三)--字元與資料的轉換
版權宣告:本文為博主原創文章,未經博主允許不得轉載。 https://blog.csdn.net/solar_Lan/article/details/78093692 學串列埠通訊的應用主要是實現微控制器和電腦之間的資訊互發,可以用電腦控制微控制器的一些資訊,可以把微控制器的一些資訊狀況發給電腦
不要讓你幾千的工資限制住你,學好大資料,年薪50W不是夢
大資料應該學什麼?如果是有基礎就根據個人情況來定,如果是零基礎想學習大資料,大資料應該學什麼?大資料要學的東西有很多,下面列舉了一些學習大資料就該學習的技術,許多想學習大資料不知道大資料應該學什麼的,可以參考一下。 1.瞭解大資料理論 要學習大資料你至少應該知道什麼是大資料,大資料一般運用在什麼
大資料學習線路圖分享,自學大資料看這裡就夠了!
學習大資料需要java作為基礎! 一般來說學大資料,首先要學java基礎、javaweb、SSM框架之後在開始大資料的學習。我給你一套大資料的學習線路圖,你從線路圖就能知道java學到什麼程式設計師就可以學大資料了! 大資料學習線路圖總
0基礎文科女生,轉行大資料或IT行業有可能嗎?
首先,這個問題是我之前在知乎上回答過的一個問題。問題拿到今天來看,仍然非常具有代表性。想必,這個女生所問的問題也是許多網友們的共性問題,那麼,我們就這個問題展開探討,來揭祕你所不知道的大資料或網際網路等IT研發工程師的世界。 很多初學者,對大資料的概念都是模糊不清的,大資料是什麼,能做什麼,學的時候,該按照
Java筆試題——2的100次方,不用大資料類(Biginteger)來解答
Java筆試題——2的100次方,不用大資料類(Biginteger)來解答 package cn.hncu.offer; public class Two100 { public static void main(String[] args) { int a[]=new int[1];//
個是雲端計算,一個大資料,一個人工智慧,
我今天要講這三個話題,一個是雲端計算,一個大資料,一個人工智慧,我為什麼要講這三個東西呢?因為這三個東西現在非常非常的火,它們之間好像互相有關係,一般談雲端計算的時候也會提到大資料,談人工智慧的時候也會提大資料,談人工智慧的時候也會提雲端計算。所以說感覺他們又相輔相成不可分割,如果是非技術的人員來講
荷蘭領事館領導參訪團蒞臨譽存科技,共話大資料技術發展
11月27日,荷蘭王國駐重慶總領事館總領事孔思哲先生攜荷蘭王國駐華大使館科技參贊萬寧先生 ,荷蘭王國駐重慶總領事館副館長陳俊亦先生,荷蘭王國駐華大使館科技官員馬青女士,荷蘭王國駐上海總領事館科技官員Anouk女士及荷蘭MonetDB大資料公司研發部主任張穎女士一行蒞臨譽存科技參觀交流,譽存科技