
opencv舌頭監測模型+keras神經網路(LeNet)
基於前面使用opencv實現舌頭模型檢測後,本次主要針對模型引數調優,提高圖片識別率。
之前的模型精準率很高,但召回率不一定為1,有時候舌頭圖片並沒有被圈出。所以我們需要調整引數讓模型吧舌頭都識別出來,再通過LeNet模型做後續識別,將不是舌頭的剔除掉。
首先修改opencv訓練後的模型引數,調低scaleFactor值,讓模型更敏感,圈出更多的圖片(舌頭+額外的其他非舌頭圖片)
在預設引數(scaleFactor=1.38, minNeighbors=4, minSize=(20,20),)下,
Cascades模型的識別率偏低但精度高,
在該引數下,在資料規模為500的測試集中,一共切割出
修改為:(scaleFactor=1.002,, minNeighbors=3, minSize=(3,3),),
在該引數下,在資料規模為500的測試集中,一共切割出4823張小圖,覆蓋了500張圖片中的499張圖片,剩餘的4324張小圖為識別錯誤圖片,或冗餘圖片。
對比發現,前者的精準率很高,但召回率低於後者。所以我們在加上LeNet模型對後者進行再次過來篩選。
收集整理資料集
在上一個步驟中,我們通過Cascades演算法共獲得4823切割後的小圖,首先我們需要人工把這些圖片分為正樣本(是舌頭)和圖樣本(非舌頭)。
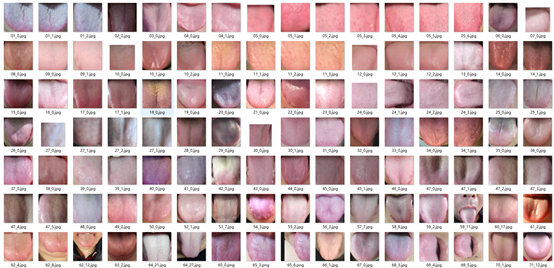
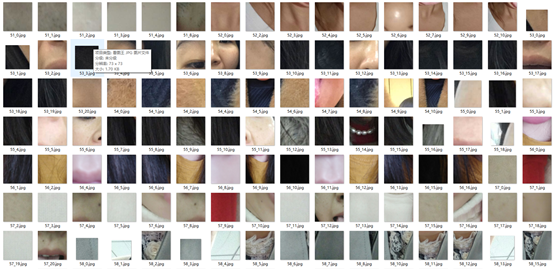
考慮到後期神經網路模型的計算量,在載入資料時,我們會將圖片標化為200 * 200的灰度圖片,分完後的效果如下:
正樣本:
負樣本:
構建卷積神經網路並訓練
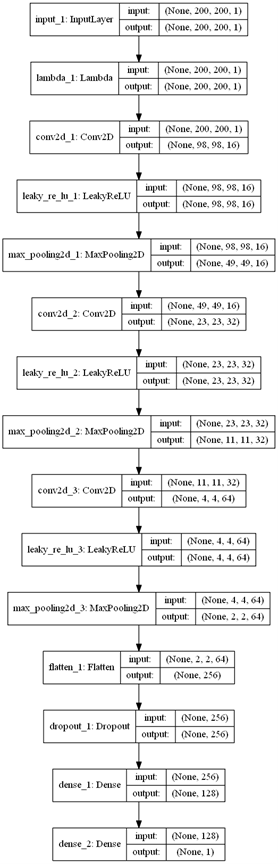
為了提高模型的判別準確率,我們構建了一個深度為15層的卷積神經網路,
卷積網路的輸入是以200 * 200 的灰度圖片,輸出是一個0-1之前的值,該值是一個概率值,
import cv2
import os
import numpy as np
import tensorflow as tf
import keras.backend as K
from keras.datasets import mnist
from keras.layers import *
from keras.models import *
from keras.optimizers import *
from keras.initializers import *
from keras.callbacks import *
from keras.utils.vis_utils import plot_model#顯示層級圖
from tqdm import tqdm
def loadGrayImg(path, shape=(200, 200, 1)):
"""
獲取灰度值圖片
:param path:
:return:
"""
img = cv2.imread(path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = cv2.resize(img, (shape[0], shape[1]))
return np.reshape(img, shape)
def loadData(dir, shape=(200, 200, 1)):
"""
載入資料集
:param dir:
:return:
"""
imgs = []
for fn in os.listdir(dir):
if fn.endswith('jpg'):
imgs.append(loadGrayImg(os.path.join(dir, fn), shape=(200, 200, 1)))
return np.array(imgs)#轉換為numpy矩陣
def net():
"""卷及網路模型"""
inputs = Input(shape=(200, 200, 1))
model = Lambda(lambda x: (x - 127.5) / 127.5)(inputs)#將畫素值變為(-1,-1)----灰度值是從0-255
#卷積層--16個特徵圖,關機過濾器(5*5),步長2*2,特徵圖大小:(200-5+2)/2=98
model = Conv2D(16, 5, strides=(2, 2))(model)
#啟用層--高階啟用層Advanced Activation-----LeakyReLU層,LeakyRelU是修正線性單元(Rectified Linear Unit,ReLU)的特殊版本,當不啟用時,
# LeakyReLU仍然會有非零輸出值,從而獲得一個小梯度,避免ReLU可能出現的神經元“死亡”現象。即,f(x)=alpha * x for x < 0, f(x) = x for x>=0
# sigmoid和tanh在x趨於無窮的兩側,都出現導數為0的現象,成為軟飽和啟用函式。也就是造成梯度消失的情況,從而無法更新網路狀態。
# relu的主要特點就是:單側抑制,相對寬闊的興奮邊界,稀疏啟用性。稀疏啟用性,是指使得部分神經元輸出為0,造成網路的稀疏性,
#緩解過擬合現象。但是當稀疏過大的時候,出現大部分神經元死亡的狀態,因此後面還有出現改進版的prelu.就是改進左側的分佈
model = LeakyReLU()(model)
#池化層----輸出49*49*16
model = MaxPooling2D(strides=2)(model)
#卷積層---32個特徵圖,(49-5+2)/2=23-------輸出23*23*32
model = Conv2D(32, 5, strides=(2, 2))(model)
#啟用層
model = LeakyReLU()(model)
#池化層--輸出11*11*32
model = MaxPooling2D(strides=2)(model)
#卷積層--64個特徵圖feature map,輸出(11-5+2)/2=4*4*64
model = Conv2D(64, 5, strides=(2, 2))(model)
#啟用層
model = LeakyReLU()(model)
#池化層---輸出2*2*64
model = MaxPooling2D(strides=2)(model)
#展開層--輸出256
model = Flatten()(model)
#drop層,預設0.5最好
model = Dropout(0.2)(model)
#全連線層,壓縮為需要的維度128,如果本層的輸入資料的維度大於2,則會先被壓為與kernel相匹配的大小。
model = Dense(128)(model)
# 全連線層,壓縮為需要的維度128
model = Dense(units=1, activation='sigmoid')(model)#使用simgod輸出0-1之間的值 ,二分類
#生成模型
model = Model(inputs=inputs, outputs=model)
#執行模型,開始訓練
model.compile(optimizer='nadam', loss='binary_crossentropy', metrics=['accuracy'])
return model
def train(echos=500, batch_size=128):
"""訓練模型"""
model = net()
model.summary()
plot_model(model, show_shapes=True, show_layer_names=True)
positive = loadData('train/positive')#載入正資料
negtive = loadData('train/negtive')#載入負資料
#合併兩個矩陣----相當於拼接到前面一個數組的後面
x = np.concatenate([positive, negtive])
y = np.zeros(len(x))
#賦值標籤
y[0:len(positive)] = 1.
y[len(positive):] = 0.
#進度條
for i in tqdm(range(int(echos))):
model.fit(x, y, batch_size=batch_size)#訓練傳入資料和標籤
model.save('model/tongue_%d.model' % i)
if __name__ == '__main__':
train()最後整合Cascades模型和卷積網路模型,做影象切割
在識別和切割舌頭頭圖片時,主要用到了Cascades模型和卷積網路模型兩種演算法模型。
其中Cascades模型主完成於舌頭的座標定位;隨後我們會根據這個鞋座標切割出一組影象,而卷積網路模型則用於計算這一組影象中每一個圖片屬於舌頭的概率,最終選取概率最高的一張作為輸出。