
神經網路(一):神經元模型與邏輯迴歸
一、仿生學
在經典的機器學習領域,有很多不同型別的模型,它們大致可以分為兩類:一類是比較注重模型可解釋性的傳統統計模型,比如線性迴歸和邏輯迴歸;另一類是側重於從結構上“模仿”資料的機器學習模型,比如監督式學習SVM和非監督式學習KMeans。
這些模型雖然在結構和形態上千差萬別,但它們有一個共同的建模理念,就是首先對資料做假設,然後根據這些假設進行數學推導,並最終得到模型的公式。其中最核心的部分就是模型的假設,它直接決定了模型的適用範圍,也是模型效果的保障。這些模型不但能對未知資料做預測,還能幫助我們去理解資料之間的相關關係。
但神經網路或者深度學習是一種全新的建模理念,它並不關心模型的假設以及相應的數學推導,也就是說它並不關心模型的可解釋性。這個理念的目的是借鑑仿生學
這種理念下設計出來的模型有很多酷炫的名字,比如神經網路、人工智慧以及深度學習等。這類模型雖然難以理解或者更準確地說,到目前為止人類還無法理解,但在某些特定應用場景裡的預測效果卻出奇得好,因此也常常引起爭論。一部分人認為,目前的人工智慧熱只是一個泡沫,整個學科並沒有實質性的突破;另一部分人認為人工智慧已經在突破的前夜,在不遠的未來,它將給人類帶來巨大的便利;還有一部分人認為人工智慧是極其危險的東西,我們正在創造一種新的具有智慧的“生命”,也許在不遠的未來,這種人造的智慧會統治地球並最終毀滅人類,就像很多科幻電影裡的情節那樣。
以上這3種觀點都有其道理2,本系列文章並不打算加入這種巨集觀議題爭論,而是採取中立立場討論相關的技術細節和發展趨勢。相信讀者通過這個系列的文章瞭解了人工智慧的基礎知識後,會對上面的話題有自己的觀點。
二、神經元
由於神經網路的模擬物件是人的大腦,那麼在討論具體的模型之前,我們有必要先從生物學的角度來看看人的大腦有哪些特性。
根據生物學的研究,人腦的計算單元是神經元(neuron)。它能根據環境變化做出反應,再將資訊給其他的神經元。在人腦中,大約有860億個神經元,它們相互聯結構成了極其複雜的神經系統,而後者正是人類智慧的物質基礎。因此遵循人腦的生物結構,我們首先需要搭建模型來模擬人的神經元。
如圖1所示,一個典型的神經元由4個部分組成。
- 樹突:一個神經元有若干個樹突,它們能接收來自其他神經元的訊號,並將訊號傳遞給細胞體。
- 細胞體:細胞體是神經元的核心,它把各個樹突傳遞過來的訊號加總起來,得到一個總的刺激訊號。
- 軸突:當細胞體內的刺激訊號超過一定閾值之後,神經元的軸突會對外發送訊號。
- 突觸:該神經元傳送的訊號(若有)將由突觸向其他神經元或人體內的其他組織(對神經訊號做出反應的組織)傳遞。需要注意的是,神經元通常有多個突觸,但它們傳遞的訊號都是一樣的。
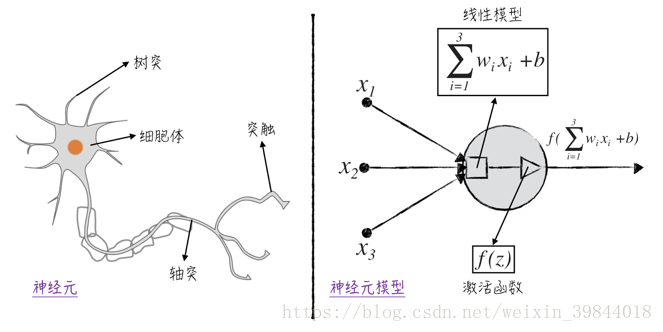
將上述的神經元結構抽象成數學概念,可以得到如圖1所示的神經元模型。
- 模型的輸入是資料裡的自變數,比如圖中的。它們用圓點表示,對應著神經元裡的樹突。
- 接收輸入變數的是一個線性模型,在圖中用正方形表示。這個線性模型對應著神經元的細胞體。值得注意的是,對於神經元中的線性模型,我們將模型中的權重項和截距項特意分開,用表示權重,用表示截距3。
- 接下來是一個非線性的啟用函式(activation function),它將控制是否對外發送訊號,在圖中用三角形表示,對應這神經元裡的軸突。在神經網路領域,常常用一個圓圈來概括地表示線性模型和啟用函式,並不將兩者分開,在本系列文章中,我們將沿用這一記號。
- 將模型的各個部分聯結起來得到最後的輸出,這個值將傳遞給下一個神經元模型,在圖中用箭頭表示,對應著神經元裡的突觸。值得注意的是,一個神經元可以有多個輸出箭頭,但它們所輸出的值都是一樣的。
在神經元模型中,非線性的啟用函式是整個模型的核心。在最初的神經元模型中4,的定義是非常直觀的,當函式的自變數大於某個閾值時,則等於1,否則等於0。具體的公式如下:
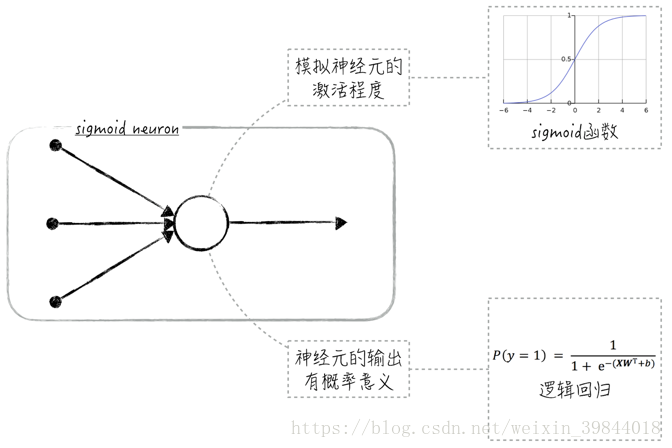
這個模型在學術上被稱為感知器(perceptron),它可被用來解決二元分類問題(因為模型的輸出是0或1)。感知器雖然在某種程度上模擬了神經元裡軸突的行為,但處理方式有些太過粗糙了,因為在生物學上,神經元輸出的是一個連續值而非離散值。這導致感知器的模型效果很一般。為了改進這一點,通常使用sigmoid函式(sigmoid function,也稱為S函式)來作為神經元的啟用函式5,這樣的模型被稱為sigmoid神經元(sigmoid neuron)。
三、Sigmoid神經元與二元邏輯迴歸
Sigmoid函式在資料科學領域是一個非常重要的函式。特別是在神經網路和深度學習領域,我們會經常見到它。sigmoid的函式影象呈S形狀,因此也常被稱為S函式,具體的公式如下:
使用sigmoid函式作為神經元裡的啟用函式有兩大好處。從實用的角度來講,sigmoid函式能將任意的實數值對映到區間,當公式(2)中的變數是很大的負數時,函式值接近0;當變數是很大的正數時,函式值接近1。這個特性在神經元上也能找到很好的解釋:函式值接近0表示神經元沒被啟用,而函式值接近1表示神經元完全被啟用。
從理論的角度來講,sigmoid函式模擬了兩種效應的相互競爭:假設正效應和負效應都和自變數是近似線性關係。具體的公式如下,其中,表示正效應,表示負效應,和是模型引數,和是服從正態分佈的隨機干擾項。
數學上可以證明,正效應大於負效應的概率可由一個sigmoid函式來近似,如公式(4)所示。
因此在神經元模型裡使用sigmoid函式,就相當於給神經元的輸出賦予了概率意義,這使得模型的理論基礎更加紮實,也使得模型能被用於解決二元分類問題,比如當sigmoid神經元的輸出大於0.5時,則預測類別為1,否則預測類別為0。值得注意的是,在這種情況下,sigmoid神經元其實就是二元邏輯迴歸模型,如圖2所示。
四、廣告時間
李國傑院士和韓家煒教授在讀過此書後,親自為其作序,歡迎大家購買。
另外,與之相關的免費視訊課程請關注這個連結
仿生學(bionics)是模仿生物的特殊本領的一門科學,它在瞭解生物結構和功能原理的基礎上,來研製新的機械和新的技術。以上簡介參考自維基百科 ↩︎
這3種觀點的論據和邏輯超出了本書的討論範圍,在此就不做展開,僅列舉它們背後的權威支持者。
機器學習領域重要的學者邁克爾·I.喬丹(Michael I. Jordan)教授就持第一種觀點,他認為我們離接近人類水平的人工智慧還很遠。雖然在某些領域,可以用神經網路來“偽造”智慧,但理智來說,這並不是智慧。
另一位很知名的學者吳恩達(Andrew Ng,他是邁克爾·I.喬丹的學生)以及企業家扎克伯格(Mark Zuckerberg)持第二種觀點。他們對人工智慧的發展表示樂觀,主張人工智慧是一場新的工業革命,將會像電力一樣改變工業以及人類的生活。
來自業界的比爾·蓋茨(Bill Gates)和伊隆·馬斯克(Elon Musk)則持第三種觀點,他們認為雖然現階段人工智慧並沒有表現出直接的危害,但按照現在的發展速度,在不遠的將來(5年或者10年之內),我們將直接面對人工智慧帶來的威脅 ↩︎在神經網路中,線性模型裡的截距項是有特殊生物含義的,它通常對應著神經元的啟用閾值,因此需要單獨處理它 ↩︎
Frank Rosenblatt於1957年在Cornell航空實驗室(Cornell Aeronautical Laboratory)設計了第一款人工神經網路。這個最初版的神經網路其實是一臺機器:由於當時的計算機還處在比較初級的階段,因此專門設計了一臺機器來實現這個模型 ↩︎
事實上基於工程實現上面的考慮,目前在實際應用中很少會使用sigmoid函式作為啟用函式 ↩︎
相關推薦
神經網路(一):神經元模型與邏輯迴歸
一、仿生學 在經典的機器學習領域,有很多不同型別的模型,它們大致可以分為兩類:一類是比較注重模型可解釋性的傳統統計模型,比如線性迴歸和邏輯迴歸;另一類是側重於從結構上“模仿”資料的機器學習模型,比如監督式學習SVM和非監督式學習KMeans。 這些模型雖然在結
神經網路(二):Softmax函式與多元邏輯迴歸
一、 Softmax函式與多元邏輯迴歸 為了之後更深入地討論神經網路,本節將介紹在這個領域裡很重要的softmax函式,它常被用來定義神經網路的損失函式(針對分類問題)。 根據機器學習的理論,二元邏輯迴歸的模型公式可以寫為如下的形式: (1)P(y=1)=11
Deep Learning模型之:CNN卷積神經網路(一)深度解析CNN
http://m.blog.csdn.net/blog/wu010555688/24487301 本文整理了網上幾位大牛的部落格,詳細地講解了CNN的基礎結構與核心思想,歡迎交流。 1. 概述 卷積神經網路是一種特殊的深層的神經網路模型,它的特殊性體現在兩個方面,一方面它的神經元
搭建簡單圖片分類的卷積神經網路(一)-- 訓練模型的圖片資料預處理
一、訓練之前資料的預處理主要包括兩個方面 1、將圖片資料統一格式,以標籤來命名並存到train資料夾中(假設原始圖片按類別存到資料夾中)。 2、對命名好的圖片進行訓練集和測試集的劃分以及圖片資料化。 先對整個專案檔案進行說明: 專案資料夾
吳恩達深度學習系列課程筆記:卷積神經網路(一)
本系列文章將對吳恩達在網易公開課“深度學習工程師”微專業內容進行筆記總結,這一部分介紹的是“卷積神經網路”部分。 1、計算機視覺 計算機視覺在我們還是生活中有非常廣泛的應用,以下幾個是最常見的例子: 影象分類: 可以對影象中的物體種類進行判斷,如確定影象中
10分鐘看懂全卷積神經網路( FCN ):語義分割深度模型先驅
大家好,我是為人造的智慧操碎了心的智慧禪師。今天是10月24日,既是程式設計師節,也是程式設計師
GAN (生成式對抗網路) (一): GAN 簡介
自從 Ian Goodfellow 在 14 年發表了 論文 Generative Adversarial Nets 以來,生成式對抗網路 GAN 廣受關注,加上學界大牛 Yann Lecun 在 Quora 答題時曾說,他最激動的深度學習進展是生成式對抗網路,使得 GAN 成為近年來在機器學習
detectron程式碼理解(一):Resnet模型構建理解
這裡具體以resnet50為例進行說明,一句一句地分析程式碼,程式碼位置位於Resnet.py,具體的分析函式為add_ResNet_convX_body. 在分析之前首先貼上resnet50的程式碼結構圖: # add the stem (by default, conv1 and
神經網路(三):神經網路
一、 神經元到神經網路 在之前的文章中(《神經網路(一)》和《神經網路(二)》),我們討論瞭如何為神經元搭建模型。雖然搭建模型的過程並不複雜,但得到的神經元模型也沒有太多的新意,比如使用sigmoid函式作為啟用函式,則得到的神經元模型就是邏輯迴歸。 在人體中
神經網路(四):應用示例之分類
一、 傳統分類模型的侷限 在之前的文章中(《神經網路(一)》、《神經網路(二)》和《神經網路(三)》),我們討論的重點是神經網路的理論知識。現在來看一個實際的例子,如何利用神經網路解決分類問題。(為了更好地展示神經網路的特點,我們在這個示例中並不劃分訓練集和測
JAVA伴我行——專案篇(一):開發模型,敏捷開發和瀑布模型的結合
在專案的開發過程中,我們或多或少都會遵循一定的模式。最常見的就是瀑布模型了(也許平時沒有注意,但你確實在遵循這個模型)。 瀑布模型的典型表現就是遵循以下順序:需求調研/分析,詳細設計/概要設計,編碼階段,測試階段,整體優化/執行維護。 遵循瀑布模型的好處是我們能夠嚴格按照軟
人工神經網路(一)概述
百科解釋: 人工神經網路(Artificial Neural Network,即ANN ),是20世紀80 年代以來人工智慧領域興起的研究熱點。它從資訊處理角度對人腦神經元網路進行抽象, 建立某種簡單模型,按不同的連線方式組成不同的網路。在工程與學術界也常直接簡稱為神
【機器學習】神經網路(一)——多類分類問題
一、問題引入 早在監督學習中我們已經使用Logistic迴歸很好地解決二類分類問題。但現實生活中,更多的是多類分類問題(比如識別10個手寫數字)。本文引入神經網路模型解決多類分類問題。 二、神經網路模型介紹 神經網路模型是一個非常強大的模型,起源於嘗試讓機
【機器學習】動手寫一個全連線神經網路(三):分類
我們來用python寫一個沒有正則化的分類神經網路。 傳統的分類方法有聚類,LR邏輯迴歸,傳統SVM,LSSVM等。其中LR和svm都是二分類器,可以將多個LR或者svm組合起來,做成多分類器。 多分類神經網路使用softmax+cross entropy組
BP神經網路(一)
BP神經網路是利用影響力計算來調節權值的,就是那些東西影響了我,這個影響力就是我們以前所說的-偏導數。 所以要合理正確的改變權值,我們必須知道有哪幾種力量在影響著權值,或者哪幾種力量被權值影響。 在知道了那幾個被我們影響的東西誤差情況後,我們才能按照它合理的調整自己,這就是BP神經網路權值調
Netty 入門(一):基本元件與執行緒模型
Netty 的學習內容主要是圍繞 TCP 和 Java NIO 這兩個點展開的,後文中所有的內容如果沒有特殊說明,那麼所指的內容都是與這兩點相關的。由於 Netty 是基於 Java NIO 的 API 之上構建的網路通訊框架,Java NIO 中的幾個元件,都能在 Netty 中找到對應的封裝。下面我們
卷積神經網路(二):應用簡單卷積網路實現MNIST數字識別
卷積神經網路簡單實現MNIST數字識別 本篇的主要內容: 一個兩層卷積層的簡單卷積網路的TensorFlow的實現 網路的結構 在這張圖裡,我把每一層的輸入以及輸出的結構都標註了,結合閱讀程式碼食用效果更佳。 具體程式碼 具體的內容,都寫在相應位置的註釋中
機器學習與神經網路(四):BP神經網路的介紹和Python程式碼實現
前言:本篇博文主要介紹BP神經網路的相關知識,採用理論+程式碼實踐的方式,進行BP神經網路的學習。本文首先介紹BP神經網路的模型,然後介紹BP學習演算法,推導相關的數學公式,最後通過Python程式碼實現BP演算法,從而給讀者一個更加直觀的認識。 1.BP網路模型 為了將理
卷積神經網路(四):學習率、權重衰減、動量
學習率、權重衰減、動量被稱為超引數,因為他們不是由網路訓練而得到的引數 權重衰減 L2正則化就是在代價函式後面再加上一個正則化項: C0代表原始的代價函式,後面那一項就是L2正則化項,λ就是權重衰減項。 作用:防止過擬合 原理: 一個所謂“顯
Matlab實現BP神經網路和RBF神經網路(一)
本實驗依託於教材《模式分類》第二版第六章(公式符號與書中一致) 實驗內容: 設計編寫BP神經網路和RBF神經網路,對給定資料集進行分類測試,並將分類準確率與SVM進行對比。 實驗環境: matlab2016a 資料集: 資料集大小3*30