
深度學習之風格轉換——Style Transfer
最近在學習CS20課程——一門講述tensorflow應用的實踐性課程,正好Assignment2講到了Style Transfer這個東西,這裡把我的理解總結一下(程式碼基於Tensorflow)。
簡介
這是一個使用兩個圖片(以A和B表示)作為輸入(圖A作為內容輸入(content input),圖B作為風格輸入(style input)。最終的目的是得到一張具有圖B的風格和圖A的內容的影象。
- style picture
- content picture
what we got
用一個簡單的方程可以表示為:style + content = picture of highly abstracted



步驟簡述
- 使用一個訓練好的CNN結構(一般來說做Image classification的就可以,比如VGG, GoogLeNet等等)
- 我們要有一個概念:CNN中低層特徵圖保留的內容比較多,而高層更多的是紋理,正是利用這一點,我們將組合內容資訊和紋理資訊並將兩者相結合得到一個全新的圖片。
對content和style分別定義損失函式,並將其組合起來作為整個結構的Loss function。
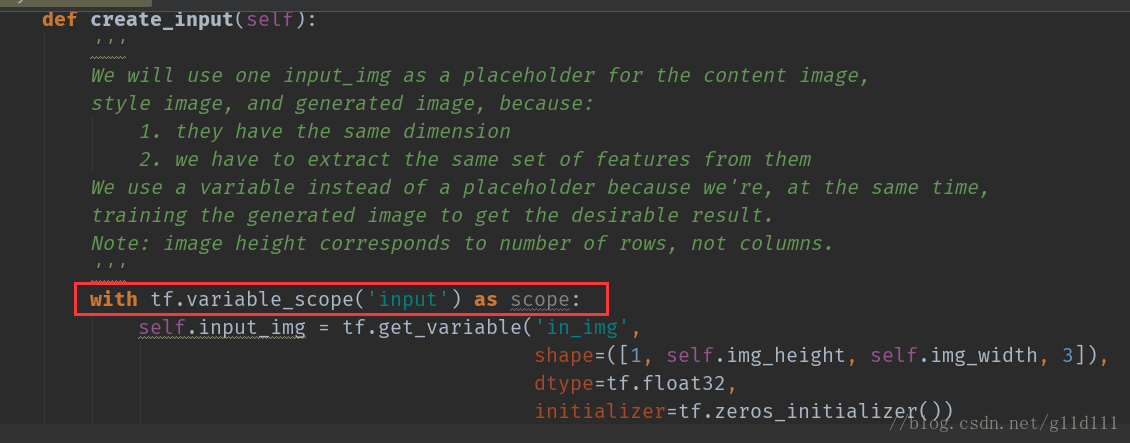
值得注意的是,我們輸入時候使用的結構使用的是一樣的結構(無論是style pic、content pic還是trianable input),為了避免重複的子計算圖裝配(To save us from having to assemble the same subgraph multiple times, we will use one variable for all three of them.
),需要使用tf.variable_scope(‘input’)。
跟之前的CNN中通過反向傳播調整網路結構引數如w和b不同的是,這裡的目標是對一個輸入的content pic加入白噪聲後的圖片進行不斷調整,給其加入內容和紋理資訊。
損失函式說明
其中α和β是權重,論文指出α/β=0.001或者0.0001,這個比例是根據內容和風格的比例來調整的,當你想要風格更濃烈,就提高α/β的值,反之則降低α/β。
1. content loss
content loss比較容易理解,論文裡定義如下:
假設某一層得到的響應是
其中為l層filter的個數,為filter的大小()。表示的是第層第個filter在位置的輸出。這裡的是層生成影象的特徵表示(content representation of the generated image),是層內容影象的特徵表示(content representation of the content image)。實際上就是關於和的均方誤差。論文中建議使用的layer是conv4_2。
下面翻譯自CS20 Assignment2 的note
然而在實踐中發現,這個content loss收斂的很慢。所以這裡可以將前面的係數1/2換成1/(4s)。s為的所有維度的乘積,比如為[5, 5, 3]。那麼s = 5*5*3=75。
2. style loss
style loss有些複雜,在論文中,它有三步計算得來。首先讓我們來看style loss的定義: