
語言模型與RNN
阿新 • • 發佈:2019-02-14
注:cs224n
語言模型:一個用來預測下一個單詞的系統模型
用公式可以表示為:
這裡是一個位於詞彙表V={}中的詞。
一、最初用的語言模型被稱為n-gram Langurage Models

n-gram model 引入HMM假設:只依賴於前面的n-1個詞
即:
用頻率逼近概率得:
例:

n-gram langurage model 存在的問題


二、那麼如何建立一個神經網路語言模型呢?
首先想到的當然是與n-gram langurage model類似的視窗模型。
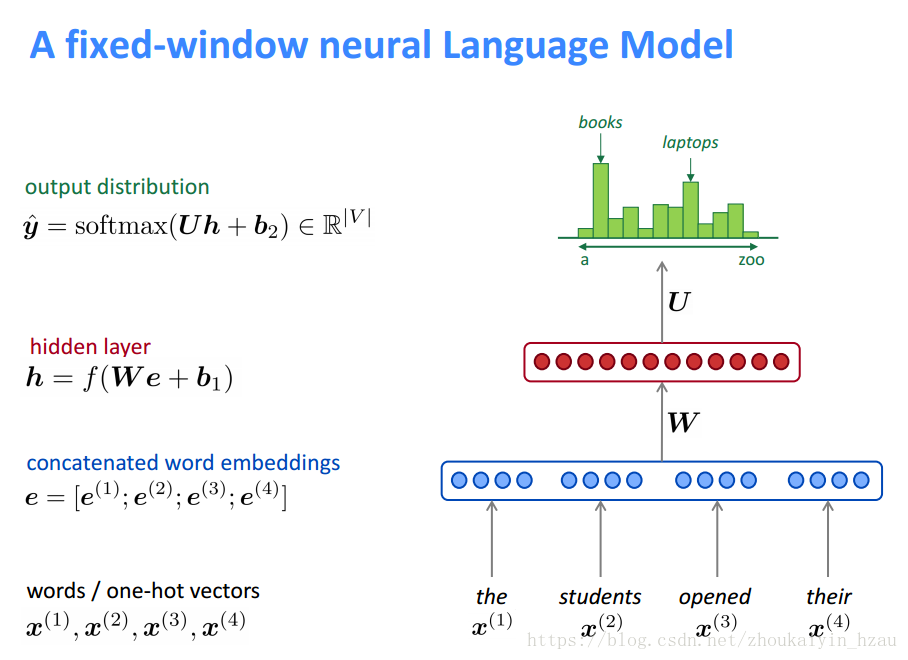
該模型是一個限定視窗長度的語言模型。相比於傳統的n-gram langurage model 他的優勢是:
一、不存在向量稀疏問題
二、模型複雜度為O(n)
而該模型得缺點在於
一、固定視窗往往太小
二、若增加視窗 W得維度將增加(w維度與視窗大小成正比)

三、引入迴圈神經網路
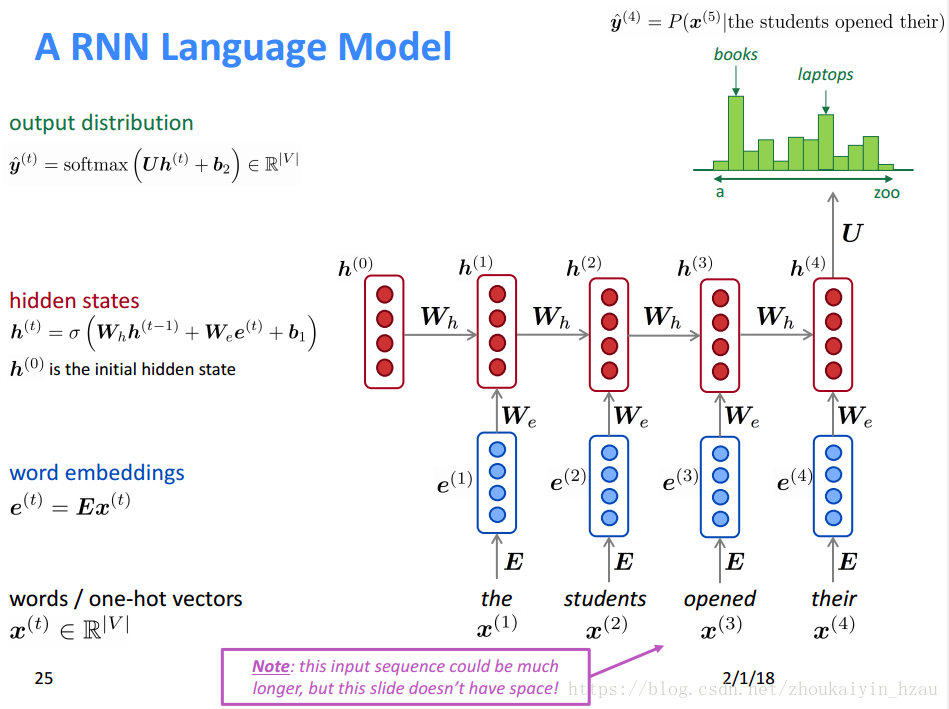
RNN的優缺點:

Training RNN langurage Model
1、將預料庫中的序列輸入RNN-LM計算每一個時刻輸出結果的分佈情況。
2、通常選用交叉熵來計算損失

對總的交叉熵去均值作為最終損失函式:

其模型表示為:

注:在整個corpus上計算交叉熵的複雜度太高,通常採用隨機梯度下降來計算。即在一個batch上計算交叉熵。
Question: 對的導數?
由鏈式法則:

因此:

這裡原本是對求導,但在求和的時候是對每一個時刻的w求導原因是:

六、評價語言模型
用perplexity評價語言模型

