
RNN實現字元級語言模型 - 恐龍島_g
阿新 • • 發佈:2018-11-12
問題描述:樣本為所有恐龍名字,為了構建字元級語言模型來生成新的名稱,你的模型將學習不同的名稱模式,並隨機生成新的名字。
在這裡你將學習到:
- 如何儲存文字資料以便使用rnn進行處理。
- 如何合成數據,通過每次取樣預測,並將其傳遞給下一個rnn單元。
- 如何構建字元級文字生成迴圈神經網路。
- 為什麼梯度修剪很重要?
1 import numpy as np 2 import random 3 import time 4 import cllm_utils
1 - 問題描述
1.1 - 資料集與預處理
1
|
data='Aachenosaurus\nAardonyx\nAbdallahsaurus\...' chars=['o', 'm', 'k', 'v', 'w', 'b', 'j', 'd', 'x', 'a', 'h', 'i',
|
1 char_to_ix = {ch:i for
|
{'\n': 0, 'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6,
|
1.2 - 模型回顧
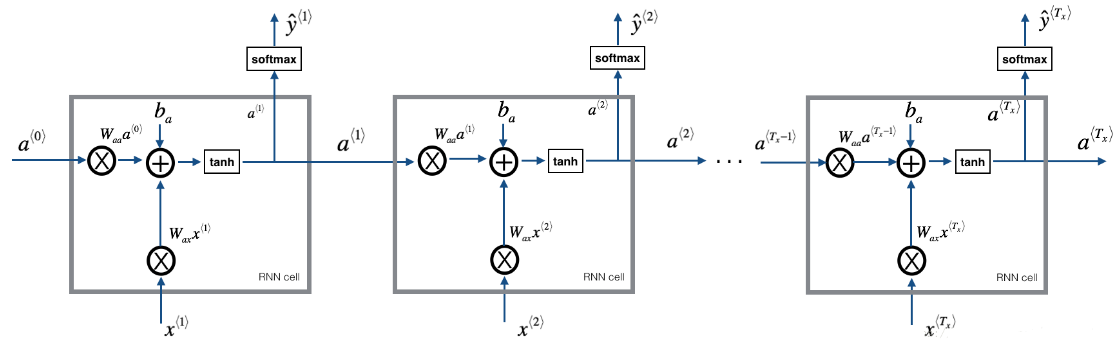
模型的結構如下:
- 初始化引數
- 迴圈:
- 前向傳播計算損失
- 反向傳播計算關於損失的梯度
- 修剪梯度以免梯度爆炸
- 用梯度下降更新規則更新引數。
- 返回學習後了的引數
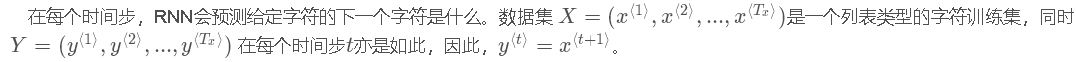
2 - 構建模型中的模組
在這部分,我們將來構建整個模型中的兩個重要的模組:
- 梯度修剪:避免梯度爆炸
- 取樣:一種用來產生字元的技術
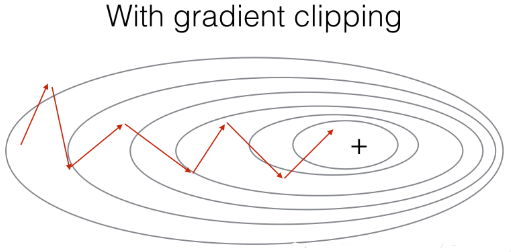
2.1 梯度修剪
在這裡,我們將實現在優化迴圈中呼叫的clip函式.回想一下,整個迴圈結構通常包括前向傳播、成本計算、反向傳播和引數更新。
在更新引數之前,我們將在需要時執行梯度修剪,以確保我們的梯度不是“爆炸”的.
接下來我們將實現一個修剪函式,該函式輸入一個梯度字典輸出一個已經修剪過了的梯度.有很多的方法來修剪梯度,我們在這裡
使用一個比較簡單的方法.梯度向量的每一個元素都被限制在[−N,N] [-N,N][−N,N]的範圍,通俗的說,有一個maxValue(比如10),
如果梯度的任何值大於10,那麼它將被設定為10,如果梯度的任何值小於-10,那麼它將被設定為-10,如果它在-10與10之間,那麼它將不變。
1 def clip(gradients, maxValue): 2 """ 3 使用maxValue來修剪梯度 4 5 引數: 6 gradients -- 字典型別,包含了以下引數:"dWaa", "dWax", "dWya", "db", "dby" 7 maxValue -- 閾值,把梯度值限制在[-maxValue, maxValue]內 8 9 返回: 10 gradients -- 修剪後的梯度 11 """ 12 # 獲取引數 13 dWaa, dWax, dWya, db, dby = gradients['dWaa'], gradients['dWax'], gradients['dWya'], gradients['db'], gradients['dby'] 14 15 # 梯度修剪 16 for gradient in [dWaa, dWax, dWya, db, dby]: 17 np.clip(gradient, -maxValue, maxValue, out=gradient) 18 19 gradients = {"dWaa": dWaa, "dWax": dWax, "dWya": dWya, "db": db, "dby": dby} 20 21 return gradients
|
函式接受最大閾值,並返回修剪後的梯度
|
1 def sample(parameters, char_to_is, seed): 2 """ 3 根據RNN輸出的概率分佈序列對字元序列進行取樣 4 5 引數: 6 parameters -- 包含了Waa, Wax, Wya, by, b的字典 7 char_to_ix -- 字元對映到索引的字典 8 seed -- 隨機種子 9 10 返回: 11 indices -- 包含取樣字元索引的長度為n的列表。 12 """ 13 14 # 從parameters 中獲取引數 15 Waa, Wax, Wya, by, b = parameters['Waa'], parameters['Wax'], parameters['Wya'], parameters['by'], parameters['b'] 16 vocab_size = by.shape[0] 17 n_a = Waa.shape[1] 18 19 # 步驟1 20 ## 建立獨熱向量x 21 x = np.zeros((vocab_size,1)) 22 23 ## 使用0初始化a_prev 24 a_prev = np.zeros((n_a,1)) 25 26 # 建立索引的空列表,這是包含要生成的字元的索引的列表。 27 indices = [] 28 29 # IDX是檢測換行符的標誌,我們將其初始化為-1。 30 idx = -1 31 32 # 迴圈遍歷時間步驟t。在每個時間步中,從概率分佈中抽取一個字元, 33 # 並將其索引附加到“indices”上,如果我們達到50個字元, 34 #(我們應該不太可能有一個訓練好的模型),我們將停止迴圈,這有助於除錯並防止進入無限迴圈 35 counter = 0 36 newline_character = char_to_ix["\n"] 37 38 while (idx != newline_character and counter < 50): 39 # 步驟2:使用公式1、2、3進行前向傳播 40 a = np.tanh(np.dot(Wax, x) + np.dot(Waa, a_prev) + b) 41 z = np.dot(Wya, a) + by 42 y = cllm_utils.softmax(z) 43 44 # 設定隨機種子 45 np.random.seed(counter + seed) 46 47 # 步驟3:從概率分佈y中抽取詞彙表中字元的索引 48 idx = np.random.choice(list(range(vocab_size)), p=y.ravel()) 49 50 # 新增到索引中 51 indices.append(idx) 52 53 # 步驟4:將輸入字元重寫為與取樣索引對應的字元。 54 x = np.zeros((vocab_size,1)) 55 x[idx] = 1 56 57 # 更新a_prev為a 58 a_prev = a 59 60 # 累加器 61 seed += 1 62 counter +=1 63 64 if(counter == 50): 65 indices.append(char_to_ix["\n"]) 66 67 return indices 68
|

|



3 - 構建語言模型
3.1 - 梯度下降
在這裡,我們將實現一個執行隨機梯度下降的一個步驟的函式(帶有梯度修剪)。我們將一次訓練一個樣本,所以優化演算法將是隨機梯度下降,這裡是RNN的一個通用的優化迴圈的步驟:
- 前向傳播計算損失
- 反向傳播計算關於引數的梯度損失
- 修剪梯度
- 使用梯度下降更新引數
我們來實現這一優化過程(單步隨機梯度下降),這裡我們提供了一些函式:
1 # 示例,可參照上一篇部落格RNN的前向後向傳播。 2 def rnn_forward(X, Y, a_prev, parameters): 3 """ 4 通過RNN進行前向傳播,計算交叉熵損失。 5 6 它返回損失的值以及儲存在反向傳播中使用的“快取”值。 7 """ 8 .... 9 return loss, cache 10 11 def rnn_backward(X, Y, parameters, cache): 12 """ 13 通過時間進行反向傳播,計算相對於引數的梯度損失。它還返回所有隱藏的狀態 14 """ 15 ... 16 return gradients, a 17 18 def update_parameters(parameters, gradients, learning_rate): 19 """ 20 Updates parameters using the Gradient Descent Update Rule 21 """ 22 ... 23 return parameters
|
|
1 def optimize(X, Y, a_prev, parameters, learning_rate = 0.01): 2 """ 3 執行訓練模型的單步優化。 4 5 引數: 6 X -- 整數列表,其中每個整數對映到詞彙表中的字元。 7 Y -- 整數列表,與X完全相同,但向左移動了一個索引。 8 a_prev -- 上一個隱藏狀態 9 parameters -- 字典,包含了以下引數: 10 Wax -- 權重矩陣乘以輸入,維度為(n_a, n_x) 11 Waa -- 權重矩陣乘以隱藏狀態,維度為(n_a, n_a) 12 Wya -- 隱藏狀態與輸出相關的權重矩陣,維度為(n_y, n_a) 13 b -- 偏置,維度為(n_a, 1) 14 by -- 隱藏狀態與輸出相關的權重偏置,維度為(n_y, 1) 15 learning_rate -- 模型學習的速率 16 17 返回: 18 loss -- 損失函式的值(交叉熵損失) 19 gradients -- 字典,包含了以下引數: 20 dWax -- 輸入到隱藏的權值的梯度,維度為(n_a, n_x) 21 dWaa -- 隱藏到隱藏的權值的梯度,維度為(n_a, n_a) 22 dWya -- 隱藏到輸出的權值的梯度,維度為(n_y, n_a) 23 db -- 偏置的梯度,維度為(n_a, 1) 24 dby -- 輸出偏置向量的梯度,維度為(n_y, 1) 25 a[len(X)-1] -- 最後的隱藏狀態,維度為(n_a, 1) 26 """ 27 28 # 前向傳播 29 loss, cache = cllm_utils.rnn_forward(X, Y, a_prev, parameters) 30 31 # 反向傳播 32 gradients, a = cllm_utils.rnn_backward(X, Y, parameters, cache) 33 34 # 梯度修剪,[-5 , 5] 35 gradients = clip(gradients,5) 36 37 # 更新引數 38 parameters = cllm_utils.update_parameters(parameters,gradients,learning_rate) 39 40 return loss, gradients, a[len(X)-1]
|
3.2 - 訓練模型
給定恐龍名稱的資料集,我們使用資料集的每一行(一個名稱)作為一個訓練樣本。每100步隨機梯度下降,你將抽樣10個隨機選擇的名字,看看演算法是怎麼做的。
記住要打亂資料集,以便隨機梯度下降以隨機順序訪問樣本。當examples[index]包含一個恐龍名稱(String)時,為了建立一個樣本(X,Y),你可以使用這個:
1 index = j % len(examples) 2 X = [None] + [char_to_ix[ch] for ch in examples[index]] 3 Y = X[1:] + [char_to_ix["\n"]]