
LightRNN —— 基於RNN的輕量級語言模型
2017年6月我在MSRA實習的時候,在微軟內部的Talk上聽過MSRA主管研究員秦濤博士講過一篇他們團隊在2016年頂會NIPS上發表的最新成果《LightRNN: Memory and Computation-Efficient Recurrent Neural Networks》。期間也有幸面對面向秦老師請教了一些論文裡的問題,感覺確確實實學到了不少的東西,故寫部落格記錄一下。
之所以叫做LightRNN,是因為這種語言模型相對於傳統的語言模型來說,擁有更小的模型容量和更高的計算速度。傳統的語言模型在進行詞向量表徵的時候使用的都是相互沒有關聯的獨立的詞向量,但是在這篇paper中一個詞語將對應一個行向量和一個列向量,其中一些詞語會共享行向量和列向量,具體的方式如下圖所示:
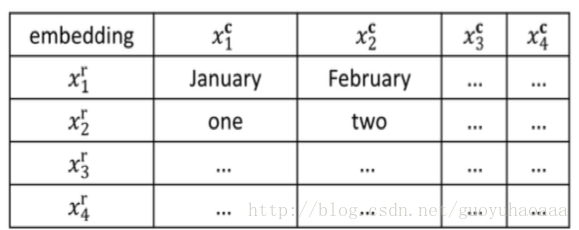
行向量和列向量分佈對應矩陣的行和列,其中矩陣中的元素就是目標詞語。這樣如果詞典中詞語的個數為|v|,傳統的方法就要生成v個與之對應的詞向量,但是在LightRNN中則只需要
下面就來詳細介紹一下這種基於RNN架構的輕量級語言模型,其整體的架構如下所示:
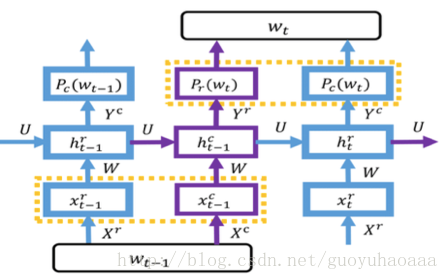
從圖中可以看出模型一共包含了2種RNN網路(紫色和藍色),分別用來處理列向量資訊和行向量資訊,同時通過隱藏層變數
step 1:
step 2:
(PS:公式中的r和c上標分佈代表了row和column)
從步驟可以看出,在計算
之所以採用看上去這麼奇怪的方式交雜在一起,是因為一個詞語完整的語義必須由其行向量和列向量共同去表徵,因此想辦法聯合計算在一起,不能單獨對行向量和列向量進行處理。
在進行預測的時候,
需要注意的是,在上述公式中,預測
其實到了這裡,LightRNN模型已經介紹完了。但是其中還是有一個比較重要的地方需要注意。就是那些共享了行向量和列向量的詞語,從理論上講應該是具有一定的相關性。但是在基礎的模型中,矩陣中的詞語是隨機分配的,這樣顯然是不合理的,模型對這種情況採用了一種非常巧妙的迭代式的方式,稱之為Bootstrap演算法。
其整體思想是:
1 剛開始將詞語隨機分配在矩陣中,然後根據LightRNN語言模型進行調優;
2 固定矩陣中的行列向量,調整詞語的位置,進一步優化損失函式;
3 重複1 2,直到演算法達到停止條件(一般會有一個預先設定的迭代次數)。
可以看出在上述過程中,最關鍵的是步驟2,即如何重新調整矩陣中詞語位置:
以RNN為代表的語言模型在機器翻譯領域已經達到了State of Art的效果,本文將簡要介紹語言模型、機器翻譯,基於RNN的seq2seq架構及優化方法。
語言模型
語言模型就是計算一序列詞出現的概率P(w1,w2,...,wT)。
語
2017年6月我在MSRA實習的時候,在微軟內部的Talk上聽過MSRA主管研究員秦濤博士講過一篇他們團隊在2016年頂會NIPS上發表的最新成果《LightRNN: Memory and Computation-Efficient Recurrent Neur
一、LSTM的相關概念部落格上有很多講解的很好的博主,我看的是這個博主的關於LSTM的介紹,感覺很全面,如果對LSTM原理不太明白的,可以點選這個連結。LSTM相關概念,這裡就不多做介紹了哈!二、GRU介紹這裡為什麼要介紹下GRU呢!因為在RNN的各種變種中,除了LSTM,另
參考部落格:
以上鍊接講解詳細,主要說明以下:
(1)資料的總量為 batch_size * num_steps * epoch_size
batch_size:一批資料的樣本數
num_steps:LSTM單元的展開步數,即橫向LSTM序列上有幾個單元
epoc
語言模型
語言模型能夠計算一段特定的字詞組合出現的頻率, 比如:”the cat is small” 和 “small the is cat”, 前者出現的頻率高
同樣的,根據前面所有的字詞序列資訊, 我們可以確定下一個位置某個特定詞出現的頻率, 豎線左邊表示下一個出現詞 問題描述:樣本為所有恐龍名字,為了構建字元級語言模型來生成新的名稱,你的模型將學習不同的名稱模式,並隨機生成新的名字。
在這裡你將學習到:
如何儲存文字資料以便使用rnn進行處理。
如何合成數據,通過每次取樣預測,並將其傳遞給下一個rnn單元。
如何構建字元級文字生成迴圈神經網路。
為
論文題目:Character-Level Language Modeling with Deeper Self-Attention
論文地址:https://arxiv.org/abs/1808.04444v1
摘要
LSTM和其他RNN的變體在
開篇
這篇文章主要是實戰內容,不涉及一些原理介紹,原理介紹為大家提供一些比較好的連結:
1. Understanding LSTM Networks :
RNN與LSTM最為著名的文章,貼圖和內容都恰到好處,為研究人員提供很好的參考價值。
中文漢化版:(譯
今天的部落格主要參考了論文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》。這篇paper是Google公司下幾個研究員發表的,而且在NLP領域引起了很大的轟動(在多個NLP任
開發環境 jupyter notebook
1 載入資料
import numpy as np
import pandas as pd
# 檢視訓練資料
train_data = pd.rea
最近使用Pytorch,搭建了一個RNNLM,目的是為了利用詞典中的每個詞的One-Hot編碼(高維的稀疏向量),來生成 Dense Vectors。這篇文章不講解RNN原理以及為什麼使用RNN語言模型,只是對pytorch中的程式碼使用進行講解。
目前Pyt
說明:本文為斯坦福大學CS224d課程的中文版內容筆記,已得到斯坦福大學課程@Richard Socher教授的授權翻譯與發表
1.語言模型
語言模型用於對特定序列的一系列詞彙的出現概率進行計算。一個長度為m的詞彙序列{w1,…,wm}的聯合概率被表示為
基於LSTM(Long-Short Term Memory,長短時記憶人工神經網路,RNN的一種)搭建一個文字意圖分類的深度學習模型(基於Python3和Tensorflow1.2),其結構圖如下:
如圖1所示,整個模型包括兩部分
第一部分:句子特徵提取
Step1 讀
歡迎點選參觀我的 ——> 個人學習網站
(未完待續)
準備工作
我們將會訓練一個RNN用於語言方面,目標是給出一系列單詞,然後預測下一個單詞。為此,我們使用專門衡量這些模型好壞的標準資料:PTB資料。它的資料量比較小並且訓練起來相對較快。
基本思路:
已知詞w,在文章中統計其上下文u1,u2。。。在負樣本集中選取負樣本u3、u4。。。
詞w的詞向量與其對應的每個樣本向量乘積,利用sigmod函式求得概率估計值。與標記值target的殘差求梯度下降,優化輸入詞向量、權值向量、偏置向量。
問題:
初始化輸入詞向量
LM perplexity by using tensorflow
1、Language model perplexity是衡量語言模型好壞的重要指標,其計算公式P(sentence)^-(1/N)
2、tensorflow的RNN模型如何使用
參考API
轉載:https://spaces.ac.cn/archives/3956/
迄今為止,前四篇文章已經介紹了分詞的若干思路,其中有基於最大概率的查詞典方法、基於HMM或LSTM的字標註方法等。這些都是已有的研究方法了,筆者所做的就只是總結工作而已。查詞典方法和字
今天的內容是基於 LSTM 建立一個語言模型
人每次思考時不會從頭開始,而是保留之前思考的一些結果,為現在的決策提供支援。RNN 的最大特點是可以利用之前的資訊,即模擬一定的記憶,具體可以看我之前寫過的這篇文章:
詳解迴圈神經網路(Recurrent
注:cs224n
語言模型:一個用來預測下一個單詞的系統模型
用公式可以表示為:
P(x(t+1)=wj|x(t),...,x(1))P(x(t+1)=wj|x(t),...,x(1))
這裡wjwj是一個位於詞彙表V={w1,...,w|V|w1,.. msg 市場調查 不能 說明 param uga resid 線下 mar 本文顯示了如何基於潛在的ARMA-GARCH過程(當然也涉及更廣泛意義上的QRM)來擬合和預測風險價值(VaR)。
1 從ARMA-GARCH進程模擬(log-return)數據
我們考慮使用\
首先整個模型的損失函式如下所示:
如果按照從詞語的維度再來看這個損失函式,就變成了如下所示:
相關推薦
基於RNN的語言模型與機器翻譯NMT
LightRNN —— 基於RNN的輕量級語言模型
TensorFlow 實現基於LSTM的語言模型
tensorflow RNN LSTM語言模型
語言模型和RNN CS244n 大作業 Natural Language Processing
RNN實現字元級語言模型 - 恐龍島_g
基於深度self-attention的字符集語言模型(transformer)論文筆記
【Language model】使用RNN LSTM訓練語言模型 寫出45°角仰望星空的文章
Bert-一種基於深度雙向Transform的語言模型預訓練策略
基於NLP自然語言構建的文件自動分類系統(搜狐娛樂)—word2vec模型
No.2 Pytorch 實現RNN語言模型
深度學習與自然語言處理(7)_斯坦福cs224d 語言模型,RNN,LSTM與GRU
基於RNN的文字分類模型(Tensorflow)
TensorFlow自然語言處理篇--------遞迴(迴圈)神經網路RNN(LSTM模型)
基於負取樣的skip-garm的語言模型實現-R
Language Model perplexity by using tensorflow使用tensorflow RNN模型計算語言模型的困惑度
【中文分詞系列】 5. 基於語言模型的無監督分詞
TensorFlow-10-基於 LSTM 建立一個語言模型
語言模型與RNN
R語言基於ARMA-GARCH-VaR模型擬合和預測實證研究分析案例