
從分類,排序,top-k多個方面對推薦演算法穩定性的評價
介紹
論文名: “classification, ranking, and top-k stability of recommendation algorithms”.
本文講述比較推薦系統在三種情況下, 推薦穩定性情況.
與常規準確率比較的方式不同, 本文從另一個角度, 即推薦演算法穩定性方面進行比較.
詳細
參與比較的推薦演算法
包括:
- baseline
- 傳統基於使用者
- 傳統基於物品
- oneSlope
- svd
比較方式
比較的過程分為兩個階段:
階段一, 將原始資料分為兩個部分, 一部分為已知打分, 另一部分為未知打分, 用於預測.
階段二, 在用於預測打分那部分資料中, 取出一部分資料, 加入到已知打分部分, 剩餘部分仍然為預測部分.
比較階段一中的預測結果和階段二中預測結果的比較.
資料劃分情況如圖所是.
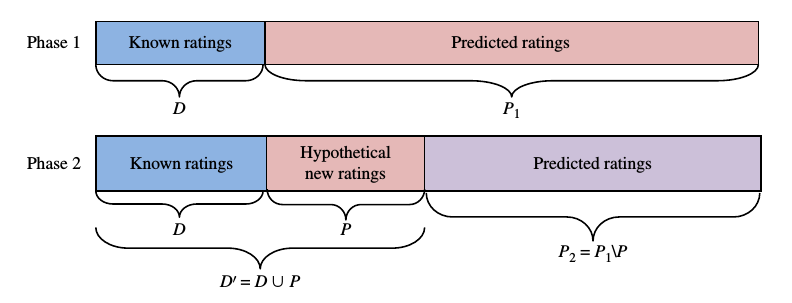
比較的方式
預測穩定性
預測性的評價方式有以下幾種:
MAE, RMSE
分類穩定性
分型別的評價方式有以下幾種:
準確率, 召回率, F-分數.
排名穩定性
排名型的評價方式有以下幾種:
排名相關性, Spearman的
前K項穩定性
前k項的評價方式有以下幾種:
點選率穩定性(hit-rate), NDCG(normalized discounted cumulative gain).
比較的場景
稀疏性衝擊
改變資料的稀疏性, 從幾個方面比較這些推薦演算法的穩定性.
結果如圖所是.
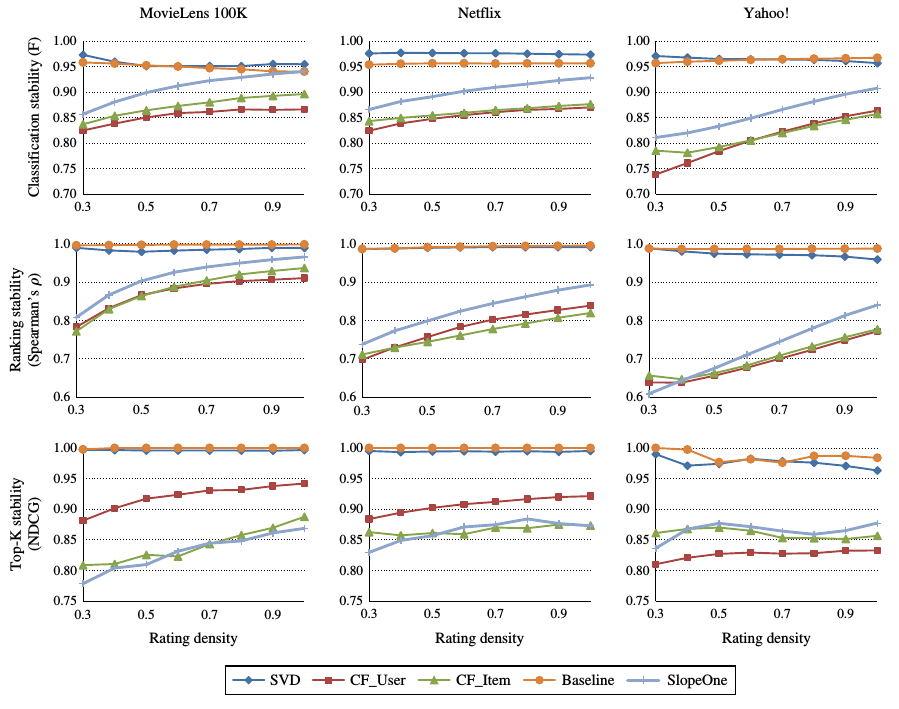
基於記憶體的推薦演算法和slopeone演算法表現出強烈的不穩定性和對資料敏感性.
svd和baseline演算法相對穩定.
評價數量衝擊
改變第二階段中新加入資料的數量, 比較兩次實驗的差異.
結果如圖所是:
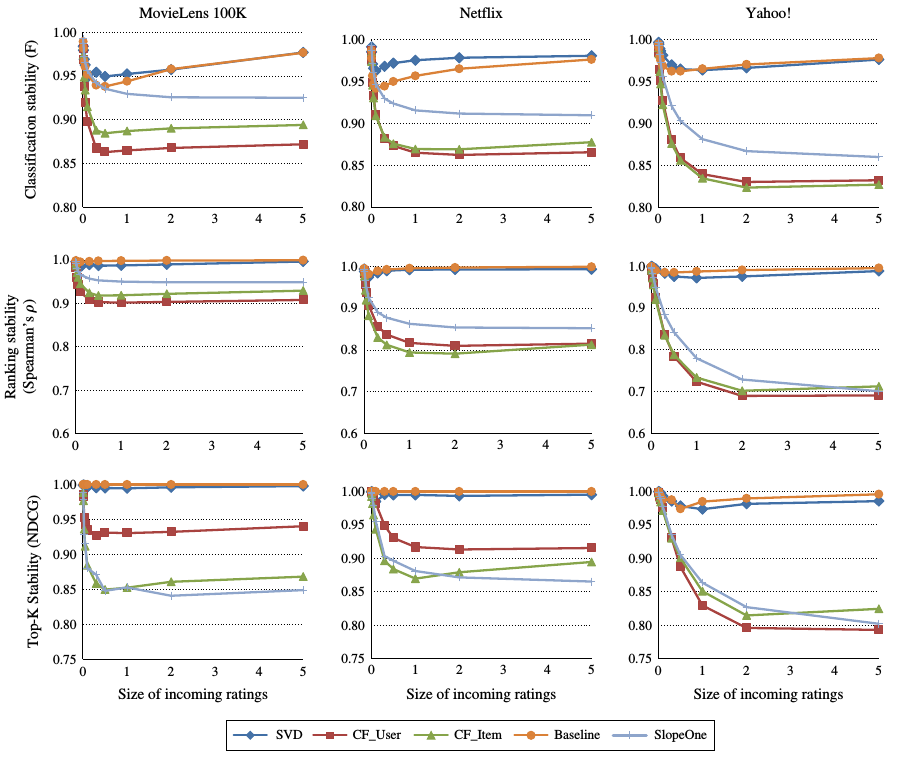
橫座標為比例, 即已知打分資料的倍數, 從10%到500%.
從圖中可以看出, 在新加入的資料較少時, 各個推薦演算法表現出高度的穩定性.
當新加入的資料較多時, 基於記憶體的推薦演算法的穩定性不斷下降.
相反, 基於模型的方法相對穩定.
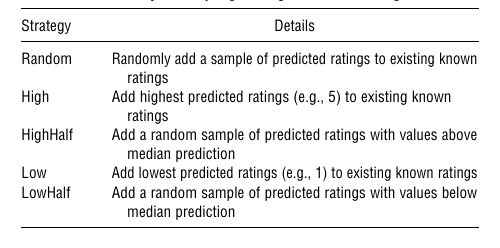
打分分佈衝擊
除了新加入的資料外, 新加入的資料的資料分佈也一定程度上影響了推薦演算法的穩定性.
下表顯示了修改資料分佈的策略:
實驗的結果如下:
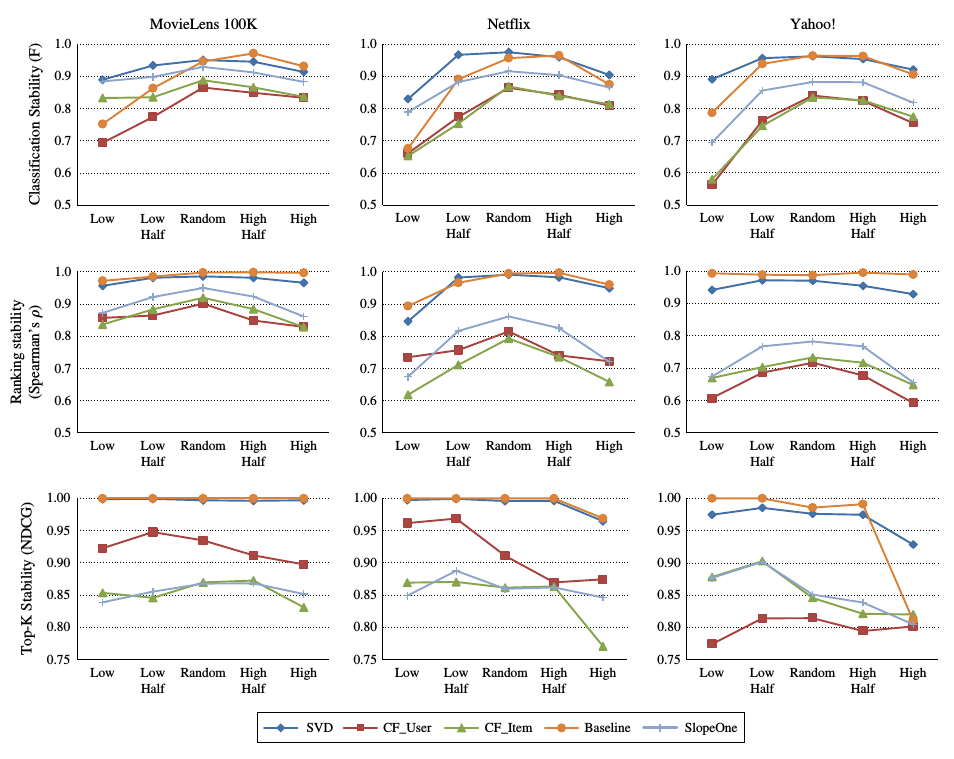
從圖中可以看出, 當加入的資料為隨機時, 各個推薦演算法都表現出相對較高的穩定性.
但是, 當新增的資料出現歪斜時, 基於記憶體的推薦演算法的穩定性降低較快, 基於模型的推薦演算法的穩定性基本保持不變.
演算法引數衝擊
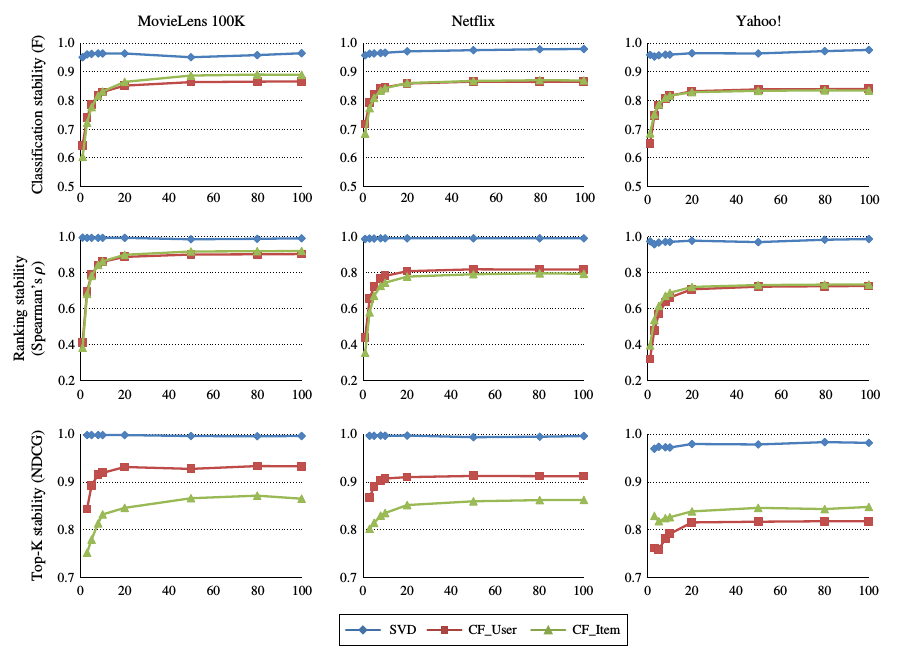
對於推薦演算法而言, 除了資料的因素外, 還有演算法本身引數對演算法穩定性的影響.
對於基於記憶體的演算法, 相似使用者/物品的數量影響著推薦演算法的效果,
對於svd演算法, 隱含屬性的數量影響著推薦演算法的結果.
實驗通過修改推薦演算法引數的方式進行比較, 結果如圖所時:
對於top-K的比較, k值的大小也影響推薦演算法的穩定性.
通過修改k的大小, 實驗的結果如圖所時:
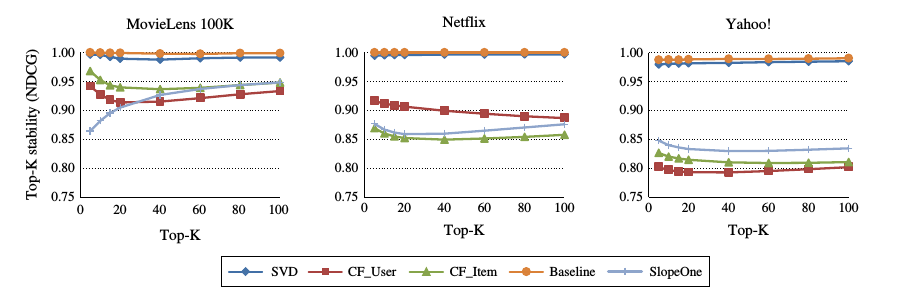
實驗結果表示:
對於修改演算法的引數, 對svd演算法的影響較少, 對於基於記憶體的演算法影響較大.
修改top-k中k的大小, 對基於模型的推薦演算法影響較小, 對於基於記憶體的推薦演算法的穩定性影響較大.
總結
對於上面多種情況的比較.
基於模型的推薦演算法在多種情況下, 穩定性較高, 特別時svd演算法.
基於記憶體的推薦演算法穩定性較差.