
大小堆排序 & Top K 問題
大小堆排序
堆這種資料結構定義比較簡單,大根堆就是父節點的值大於左右子孩子節點的值(小根堆相反),而且利用陣列下標就可以很好的表現堆(不過要注意是從0 還是 1開始)。堆常用語實現優先佇列,Top K等問題。
演算法導論第6章對堆的進行了詳細講解,我就不贅述了(看書是不夠的,要把思路用程式碼實現出來才是真的懂了,爭取把演算法導論上常用的資料結構和演算法都自己實現一般)。
大根堆
具體程式碼(按照演算法導論中下標從1開始):
/******* 大小堆排序 & topk問題 ***********/
//調整大根堆(大堆化),陣列從1下標開始
void adjust_maxheap(int 測試程式碼與執行截圖:
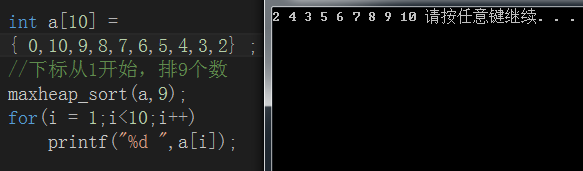
小根堆
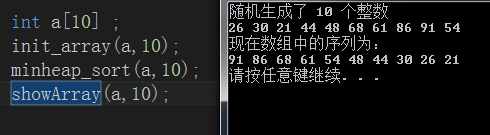
具體程式碼(下標從0開始):
void adjust_minheap(int a[],int size,int i)
{
int left = i*2+1;
int right = i*2+2;
int min_index;
if( left < size && a[left]<a[i])
min_index = left;
else
min_index = i;
if( right < size && a[right]< a[min_index])
min_index = right;
if( min_index != i)
{
SWAP(a[i],a[min_index]);
adjust_minheap(a,size,min_index);
}
}
void build_minheap(int a[],int size)
{
int start = size>>1;
for(start;start>=0;start--)
{
adjust_minheap(a,size,start);
}
}
void minheap_sort(int a[],int size)
{
int i,j=size,last= size -1;
for(i = 0;i<size;i++)
{
build_minheap(a,j--);
SWAP(a[0],a[last]);
last -= 1;
}
}測試程式碼與執行截圖:
運用堆排序解決Top K問題
top k問題就是在一堆資料中選擇前K大(前K小)的資料。做法有許多,可以先把所有資料排序,然後選前k個。
然後用堆排序解決Top K問題則不用先全部排序,只需維護一個大小為K的堆即可。
實現思路:
如果要選出前K大,則將資料中的前K個元素建立成一個小根堆,從第K+1個元素開始往後依次比較,如果元素大於小根堆的堆頂,那麼就和堆頂交換,交換後重新調整為小根堆。這樣變數一遍所有資料,最後得到的大小為K的小根堆就是前K大的樹。
具體程式碼:
void topk_biggest(int a[],int size,int k)
{
int i;
for(i = k;i<size;i++)
{
build_minheap(a,k);
if(a[i]>a[0])
SWAP(a[i],a[0]);
}
printf("最大%d個數為:",k);
for(i =0;i<k;i++)
printf("%d ",a[i]);
}
Top k 測試程式碼&執行截圖:

相關推薦
大小堆排序 & Top K 問題
大小堆排序 堆這種資料結構定義比較簡單,大根堆就是父節點的值大於左右子孩子節點的值(小根堆相反),而且利用陣列下標就可以很好的表現堆(不過要注意是從0 還是 1開始)。堆常用語實現優先佇列,Top K等問題。 演算法導論第6章對堆的進行了詳細講解,我就不贅述
Java 堆排序 Top K
1.堆 堆實際上是一棵完全二叉樹,其任何一非葉節點滿足性質: Key[i]<=key[2i+1]&&Key[i]<=key[2i+2]或者Key[i]>=Key[2i+1]&&key[i]>=
最小堆解決Top K問題
問題描述: 有一組資料n個,要求取出這組資料中最大的K個值。 對於這個問題,解法有很多中。比如排序及部分排序,不過效率最高的要數最小堆,它的時間複雜度為O(nlogk)。 解題思路: 取出
最小堆解決 Top K 問題
Top K 問題指從一組資料中選出最大的K個數。常見的例子有:熱門搜尋前10,最常聽的20首歌等。 對於這類問題,可能我們會首先想到先對這組資料進行排序,再選取前K個數。雖然這能解決問題,但效率不高,因為我們只需要部分有序,它卻對整體進行了排序。最小堆是解決To
hadoop 中文詞頻排序 top-k 問題
本人最近一直在hadoop領域,摸爬滾打,由於最近老是佈置了一項作業:讓統計一個檔案中出現次數最高的單詞。一看到題目我就想用hadoop來實現這個問題,由於有現成的wordcount框架,所以就在這之上進行程式的修改新增即可。 準備過程: 1、我去下
從分類,排序,top-k多個方面對推薦演算法穩定性的評價
介紹 論文名: “classification, ranking, and top-k stability of recommendation algorithms”. 本文講述比較推薦系統在三種情況下, 推薦穩定性情況. 與常規準確率比較的方式不同, 本
排序演算法整理(6)堆排序的應用,top K 問題
top K問題是這樣的,給定一組任意順序的數,假設有n個。如何儘快地找到它們的前K個最大的數? 首先,既然是找前K個最大的數,那麼最直觀的辦法是,n個數全部都排序,然後挑出前K個最大數。但是這樣顯然做了一些不必要的事兒。 利用堆這種資料結構,藉助前文《排序演算法整理(5)堆
Top K問題——基於堆排序
一、簡介 所謂的Top K問題其實就是找陣列中最大的前k個值。為此,只要我們能夠找到陣列中的第k大值,那麼Top K問題就會迎刃而解。在此宣告一下,本文寫的方法肯定不是最好的。不過最近看了幾個題,其核心都是找第k大的值。這裡,我只是總結下而已。 二、
最小的k個數1 堆排序實現
葉子節點 gpo 新建 void 堆排序實現 oid end 個數 時間 // 使用堆排序實現 其時間復雜度為O(nlgn) private static void buildMaxHeap(int[] input, int end) { // 從
陣列中的第K個最大元素--利用堆排序
題: 在未排序的陣列中找到第 k 個最大的元素。請注意,你需要找的是陣列排序後的第 k 個最大的元素,而不是第 k 個不同的元素。 例: 輸入: [3,2,1,5,6,4] 和 k = 2 輸出: 5
快速選擇排序 Quick select 解決Top K 問題
1. 思想 Quick select演算法通常用來在未排序的陣列中尋找第k小/第k大的元素。 Quick select和Quick sort類似,核心是partition。 1. 什麼是partitio
排序專題1 - leetcode215. TopK/347. Top K Frequent Elements/451. Sort Characters By Frequency
215. Kth Largest Element in an Array 題目描述 找出陣列中第k大的數。 假設k是有效的,即 1 ≤ k ≤ 陣列長度。 例子 Example 1: Input: [3,2,1,5,6,4] and
演算法題(二十六)利用堆排序解決找出最小的k個值問題
題目描述 輸入n個整數,找出其中最小的K個數。例如輸入4,5,1,6,2,7,3,8這8個數字,則最小的4個數字是1,2,3,4,。 分析 問題很簡單,升序排序後直接輸出前k個,不過要考慮時間複雜度的問題。可以用堆排序,構建有k個值的大頂堆,然後用堆頭部與其他值比較,堆
【資料結構】用模版實現大小堆、實現優先順序佇列,以及堆排序
一、用模版實現大小堆 如果不用模版的話,寫大小堆,就需要分別實現兩次,但是應用模版的話問題就簡單多了,我們只需要實現兩個仿函式,Greater和Less就行了,仿函式就是用類實現一個()的過載就實現了仿函式。這個看下程式碼就能理解了。再設計引數的時候,需要把模版
快速排序在Top k問題中的運用(quickSort and quickSelect in Top k)
參考http://blog.csdn.net/shuxingcq/article/details/75041795 快速排序演算法在陣列中選擇一個稱為主元(pivot)的元素,將陣列分為兩部分,使得 第一部分中的所有元素都小於或等於主元,而第二部分的所有元素都大於主
用堆排序尋找陣列中最大的K個數
/*********************************************************************************** 堆排序(Heapsort)是指利用堆這種資料結構所設計的一種排序演算法。 堆積是一個近似完全二叉樹的結構
Top K問題——基於快速排序
一、簡介 所謂的Top K問題其實就是找陣列中最大的前k個值。為此,只要我們能夠找到陣列中的第k大值,那麼Top K問題就會迎刃而解。在此宣告一下,本文寫的方法肯定不是最好的。不過最近看了幾個題,其核心都是找第k大的值。這裡,我只是總結下而已。 二、
海量資料處理的 Top K演算法(問題) 小頂堆實現
問題描述:有N(N>>10000)個整數,求出其中的前K個最大的數。(稱作Top k或者Top 10) 問題分析:由於(1)輸入的大量資料;(2)只要前K個,對整個輸入資料的儲存和排序是相當的不可取的。 可以利用資料結構的最小堆(小頂堆)來
TOP-K排序演算法,從海量不重複資料中找出最大/小的K個數
如題,TOP-K排序的主要功能是找出一堆不重複資料中的最小或最大的幾個數,此處我們介紹這種型別題目的某種解法: 最大最小堆,最大堆結構裡面的每一個數不都是小於root的值麼?和我們要解決的問題很像。由此,我們可以構造一個堆,並且用它來儲存我們需要找的那幾個數。有這麼一個動態
演算法問題分類---Top-K問題與多路歸併排序
Pro1:尋找前K大數 方法1:K小根堆 後面的值若大於當前根,則替換之,並調整堆 大部分人都推薦的做法是用堆,小根堆。下面具體解釋下: 如果K = 1,那麼什麼都不需要做,直接遍歷一遍,時間複雜度O(N)。 下面討論K 比較大的情況,比如1萬。 建立一個小根堆,則根是當