
MySQL全文索引Match Against與Like比較
[原文地址:http://blog.csdn.net/zyz511919766/article/details/12780173]
1.概要
InnoDB引擎對FULLTEXT索引的支援是MySQL5.6新引入的特性,之前只有MyISAM引擎支援FULLTEXT索引。對於FULLTEXT索引的內容可以使用MATCH()…AGAINST語法進行查詢。
為了在InnoDB驅動的表中使用FULLTEXT索引MySQL5.6引入了一些新的配置選項和INFORMATION_SCHEMA表。比如,為了監視一個FULLTEXT索引中文字處理過程的某一方面可以查詢INNODB_FT_CONFIG,INNODB_FT_INDEX_TABLE,INNODB_FT_INDEX_CACHE,INNODB_FT_DEFAULT_STOPWORD,INNODB_FT_DELETED和INNODB_FT_BEING_DELETED這些表。可以通過innodb_ft_num_word_optimize和innodb_optimize_fulltext_only選項控制OPTIMIZETABLE命令對InnoDB FULLTEXT索引的更新。
2.相關庫表
INFORMATION_SCHEMA庫中與InnoDB全文索引相關的表如下:
? INNODB_SYS_INDEXES:提供了InnoDB索引的狀態資訊。
? INNODB_SYS_TABLES:提供了InnoDB表的狀態資訊。
? INNODB_FT_CONFIG:顯示一個InnoDB表的FULLTEXT索引及其相關處理的元資料。
? INNODB_FT_INDEX_TABLE:轉化後的索引資訊用於處理基於InnoDB表FULLTEXT索引的文字搜尋。一般用於除錯診斷目的。使用該表前需先配置innodb_ft_aux_table配置選項,將其指定為想要檢視的含FULLTEXT索引的InnoDB表,選項值的格式為database_name/table_name。配置了該選項後INNODB_FT_INDEX_TABLE,INNODB_FT_INDEX_CACHE, INNODB_FT_CONFIG, INNODB_FT_DELETED和INNODB_FT_BEING_DELETED表將被填充與innodb_ft_aux_table配置選項指定的表關聯的搜尋索引相關資訊。
? INNODB_FT_INDEX_CACHE:向含FULLTEXT索引的InnoDB表插入資料後新插入資料轉後的索引資訊。表結構與INNODB_FT_INDEX_TABLE一致。為含FULLTEXT索引的InnoDB表執行DML操作期間重組索引開銷很大,因此將新插入的被索引的詞單獨儲存於該表中,當且僅當為InnoDB表執行OPTIMIZE TABLE語句後才將新的轉換後的索引資訊與原有的主索引資訊合併。使用該表前需先配置innodb_ft_aux_table配置選項。
? INNODB_FT_DEFAULT_STOPWORD:在InnoDB表上建立FULLTEXT索引所使用的預設停止字表。
? INNODB_FT_DELETED:記錄了從InnoDB表FULLTEXT索引中刪除的行。為了避免為InnoDB的FULLTEXT索引執行DML操作期間重組索引的高開銷,新刪除的詞的資訊單獨儲存於此表。當且僅當為此InnoDB表執行了OPTIMIZE TABLE操作後才會從主搜尋索引中移除已刪除的詞資訊。使用該表前需先配置innodb_ft_aux_table選項。
? INNODB_FT_BEING_DELETED:為含FULLTEXT索引的InnoDB表執行OPTIMIZE TABLE操作時會根據INNODB_FT_DELETED表中記錄的文件ID從InnoDB表的FULLTEXT索引中刪除相應的索引資訊。而INNOFB_FT_BEING_DELETED表用於記錄正在被刪除的資訊,用於監控和除錯目的。
3.相關配置選項
? innodb_ft_aux_table:指定包含FULLTEXT索引的InnoDB表的的名稱。該變數在執行時設定用於診斷目的。設定該值後INNODB_FT_INDEX_TABLE, INNODB_FT_INDEX_CACHE, INNODB_FT_CONFIG,INNODB_FT_DELETED和INNODB_FT_BEING_DELETED表將被填充與innodb_ft_aux_table指定的表關聯的搜尋索引相關資訊。
? innodb_ft_cache_size:當建立一個InnoDB FULLTEXT索引時在記憶體中儲存已解析文件的快取大小。
? innodb_ft_enable_diag_print:是否開啟額外的全文搜尋診斷輸出。
? innodb_ft_enable_stopword:是否開啟停止字。InnoDB FUllTEXT索引被建立時為其指定一個關聯的停止字集。(若設定了innodb_ft_user_stopword_table則停止字由該選項指定的表獲取,若沒有設定innodb_ft_user_stopword_table而設定了innodb_ft_server_stopword_table則停止字由該選項指定的表獲取,否則使用內建的停止字。)
? innodb_ft_max_token_size:儲存在InnoDB的FULLTEXT索引中的最大詞長。設定這樣一個限制後可通過忽略過長的關鍵字等有效降低索引大小從而加速查詢。
? innodb_ft_min_token_size:儲存在InnoDB的FULLTEXT索引中的最小詞長。增加該值後會忽略掉一些通用的沒有顯著意義的詞彙從而降低索引大小繼而加速查詢。
? innodb_ft_num_word_optimize:為InnoDB FULLTEXT索引執行OPTIMIZE操作每次所處理的詞數。因為在含有全文搜尋索引的表中執行批量的插入或更新操作需要大量的索引維護操作來合併所有的變化。因此,一般會執行一系列OPTIMIZE TABLE語句,每次從上一次的位置開始,處理指定數目的詞,知道搜尋索引被完全更新。
? innodb_ft_server_stopword_table:含有停止字的表,在建立InnoDB FULLTEXT索引時或忽略表中的停止字。停止字表需為InnoDB表,且在指定前應當已存在。
? innodb_ft_sort_pll_degree:為較大的表構建搜尋索引時用於索引和記號化文字的並行執行緒數。
? innodb_ft_user_stopword_table:含有停止字的表,在建立InnoDB FULLTEXT索引時或忽略表中的停止字。停止字表需為InnoDB表,且在指定前應當已存在。
? innodb_optimize_fulltext_only:改變OPTIMIZE TABLE語句對InnoDB表操作的方式。對含FULLTEXT 索引的InnoDB表進行維護操作期間,一般臨時的開啟該選項。預設情況下,OPTIMIZE TABLE語句會重組表的聚集索引中的資料。若開啟了該選項則該語句會跳過表資料的重組,而是隻處理FULLTEXT索引中新插入的、刪除的、更新的標記資料。(在對作為FULLTEXT索引的一部分的InnoDB表列進行了大量的插入、更新或刪除操作後,先將innodb_optimize_fulltext_only設定為on以改變OPTIMIZE TABLE的預設行為,然後設定innodb_ft_num_word_optimize為合適的值以將索引維護時間控制在一個合理的可接受範圍內,最後執行一系列的OPTIMIZE語句知道搜尋索引被完全更新。)
4.全文搜尋功能
全文搜尋的語法:MATCH(col1,col2,…) AGAINST (expr[search_modifier])。其中MATCH中的內容為已建立FULLTEXT索引並要從中查詢資料的列,AGAINST中的expr為要查詢的文字內容,search_modifier為可選搜尋型別。search_modifier的可能取值有:IN NATURAL LANGUAGEMODE、IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION、IN BOOLEAN MODE、WITH QUERY EXPANSION。search_modifier的每個取值代表一種型別的全文搜尋,分別為自然語言全文搜尋、帶查詢擴充套件的自然語言全文搜尋、布林全文搜尋、查詢擴充套件全文搜尋(預設使用IN NATURAL LANGUAGE MODE)。
MySQL中全文索引的關鍵字為FULLTEXT,目前可對MyISAM表和InnoDB表的CHAR、VARCHAR、TEXT型別的列建立全文索引。全文索引同其他索引一樣,可在建立表是由CREATE TABLE語句建立也可以在表建立之後用ALTER TABLE或者CREATE INDEX命令建立(對於要匯入大量資料的表先匯入資料再建立FULLTEXT索引比先建立索引後匯入資料會更快)。
4.1自然語言全文搜尋
自然語言全文搜尋是MySQL全文搜尋的預設搜尋方式,實現從一個文字集合中搜索給定的字串。這裡,文字集合指的是指由FULLTEXT索引的一個或者多個列。
建表,並給title,body欄位加FULLTEXT索引
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title,body)
) ENGINE=InnoDB;
匯入資料
INSERT INTO articles (title,body) VALUES
('MySQL Tutorial','DBMS stands for DataBase ...'),
('How To Use MySQL Well','After you went through a ...'),
('Optimizing MySQL','In this tutorial we will show ...'),
('1001 MySQL Tricks','1. Never run mysqld as root. 2. ...'),
('MySQL vs. YourSQL','In the following database comparison ...'),
('MySQL Security','When configured properly, MySQL ...');
例1:
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('database' IN NATURAL LANGUAGE MODE);

可以看到,語句查詢到了包含指定內容的行。實際上,返回的行是按與所查詢內容的相關度由高到低的順序排列的。這個相關度的值由WHERE語句中的MATCH (…) AGAINST (…)計算所得,是一個非負浮點數。該值越大表明相應的行與所查詢的內容越相關,0值表明不相關。該值基於行中的單詞數、行中不重複的單詞數、文字集合中總單詞數以及含特定單詞的行數計算得出。
例2:
由上例可知MATCH (…) AGAINST (…)實際上會計算一個相關值,可通過下例來驗證。
SELECT id, MATCH (title,body)
AGAINST ('Tutorial' IN NATURAL LANGUAGE MODE) AS score
FROM articles;
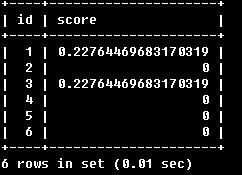
可以看到,所得結果的第二列即為改行與查詢內容的相關度。上例1中所得結果的順序就是按此相關度排列的。
例3:
若想既看到查詢到的結果又需要了解具體的相關度,可用下述方法達成。
SELECT id, body, MATCH (title,body) AGAINST
('Security implications of running MySQL as root'
IN NATURAL LANGUAGE MODE) AS score
FROM articles WHERE MATCH (title,body) AGAINST
('Security implications of running MySQL as root'
IN NATURAL LANGUAGE MODE);
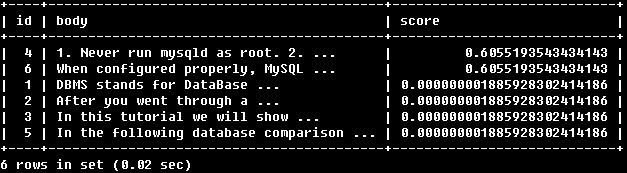
可以看到,通過在查詢部分和條件部分分別使用相同的MATCH(…) AGAINST(…)可以同時獲取兩方面的內容(不會增加額外開銷,優化器知道兩個MATCH(…) AGAINST(..)是相同的,只會執行一次該語句)
注意事項
預設情況下全文搜尋大小寫不敏感,如上例1,查詢的內容為‘database’但含有‘DataBase’的行也會返回。可以通過為FULLTEXT索引列所使用的字符集指定一個特定的校對集來改變這種行為。
考慮下述兩個SELECT語句:
1. SELECTCOUNT(*) FROM articles
WHEREMATCH (title,body)
AGAINST('database' IN NATURAL LANGUAGE MODE);
2. SELECTCOUNT(IF(MATCH (title,body)
AGAINST('database' IN NATURAL LANGUAGE MODE), 1, NULL)) AS count
FROMarticles;
這兩條查詢語句均可返回匹配的行數。但第一條語句可以利用基於WHERE從句的索引查詢,因此在匹配的行數較少時速度較第二句更快。第二句執行了全表掃描,因此在匹配的行數較多時較第一句更快。
MATCH()函式中的列必須與FULLTEXT索引中的列相同。如MATCH(title,body)與FULLTEXT(title,body)。若要單獨搜尋某列,如body列,則需另外單獨為該列建全文索引FULLTEXT(body),然後用MATCH(body)搜尋。
對於InnoDB表MATCH()中的列僅能來自於同一個表,因為索引不能快多張表(MyISAM表的的布林搜尋因為可以不使用索引所以可以跨多張表中的列,但速度很慢)。
全文搜尋不僅可以搜尋類似例1中‘database’這樣的單個的單詞,還可以搜尋句子(這才是其被稱為‘全文搜尋‘的關鍵),如例3。全文搜尋把任何數字、字母、下劃線序列看作是單詞,還可以包含“’”如aaa’bbb備解析為一個單詞,但aaa’’bbb備解析為兩個單詞,FULLTEXT解析器自動移除首尾的“’”,如’aaa’bbb’被解析為aaa’bbb。FULLTEXT解析器用“ ”(空格)、“,”(逗號)“.”(點號)作為預設的單詞分隔符,因此對於不使用這些分隔符的語言如漢語來說FULLTEXT解析器不能正確的識別單詞,對於這種情況需做額外處理。
全文搜尋中一些單詞會被忽略。首先是過短的單詞,InnoDB全文搜尋中預設為3個字元,MyISAM預設4個字元,可通過在建立FULLTEXT索引前改變配置引數來改變預設行為,對於InnoDB該引數為:innodb_ft_min_token_size,對於MyISAM為ft_min_word_len;另外stopword列表中的單詞會被忽略。stopword列表包含諸如“the”、“or”、“and”等常用單詞,這些詞通常被認為沒有什麼語義價值。MySQL由內建的停止字列表,但是可以所使用自定義的停止字列表來覆蓋預設列表。對於InnoDB控制停止字的配置引數為innodb_ft_enable_stopword,innodb_ft_server_stopword_table, innodb_ft_user_stopword_table對於MyISAM引數為ft_stopword_file。
文字集合和查詢語句中的單詞的權重由該單詞在集合或語句中的重要性確定。單詞在越多的行中出現則該單詞的權重越低,因為這表明其在文字集合中的語義價值較小。反之權重越高。例1中提到的相關度計算也與此值有關。
4.2布林全文搜尋
如果在AAGAINST()函式中指定了INBOOLEN MODE模式,則MySQL會執行布林全文搜尋。在該搜尋模式下,待搜尋單詞前或後的一些特定字元會有特殊的含義。
例1:
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('+MySQL-YourSQL' IN BOOLEAN MODE);
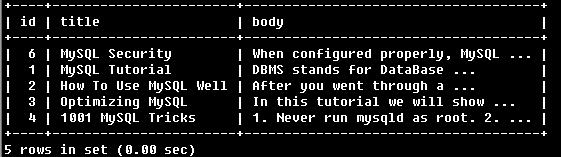
該查詢語句中“MySQL”前的“+”表明結果中必須包含“MySQL”而“YourSQL”前的“-”表明所得結果中不能含有“YourSQL”。
除了“+”和“-”外還有其他一些特定的字元。如空字元表明後跟的單詞是可選的,但出現的話會增加該行的相關性;“@distance”用於指定兩個或多個單詞相互之間的距離(以單詞度量)需在指定的範圍內;“>”用於增加後跟單詞對其所在行的相關性的貢獻“<”用於降低該貢獻;“()”用於將單詞分組為子表示式且可以巢狀;“~”是後跟單詞對其所在行的相關性的貢獻值為負;“*”為普通的萬用字元,若為單詞指定了萬用字元,那麼即使該單詞過短或者出現在了停止字列表中它也不會被移除;“””,括在雙引號中的短語指明行必須在字面上包含指定的短語,全文搜尋將短語分割為詞後在FULLTEXT索引中搜索。非字字元無需完全匹配,如”test phrase”可以匹配含”test phrase”和”test phrase”的行,但匹配含”phrase test”的行。
例2:
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('MySQL YourSQL' IN BOOLEAN MODE);
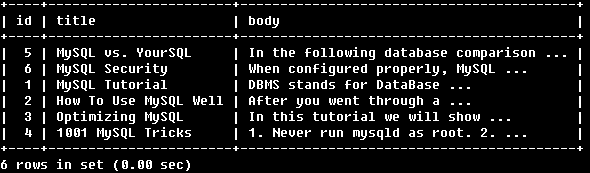
找到包含MySQL或者YourSQL的行
例3:
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('+MySQL+YourSQL' IN BOOLEAN MODE);

找到包含同時MySQL和YourSQL的行
例4:
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('+MySQL YourSQL' IN BOOLEAN MODE);
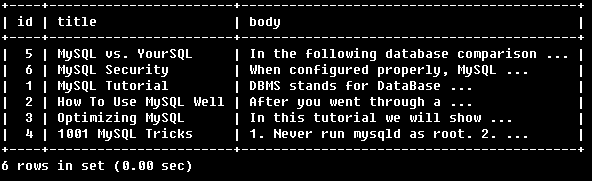
找到必須包含MySQl的行,YourSQL可有可無,但有YourSQL會增加相關性。
例5:
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('+MySQL ~YourSQL' INBOOLEAN MODE);
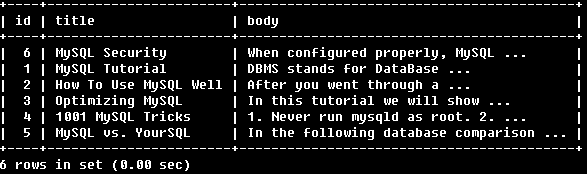
找到包含必須包含MySQL的行,YourSQL可有可無,若出現了YourSQL則會降低其所在行的相關性。
例6:
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('+MySQL +(>Security <Optimizing)' IN BOOLEANMODE);
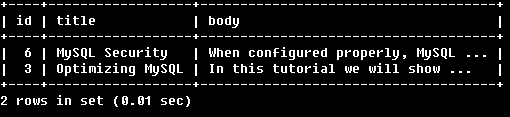
找到必須同時包含MySQL以及Security或Optimizing的行Security會增加所在行的相關性,而Optimizing會降低所在行的相關性。
例7:
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('da*' IN BOOLEAN MODE);
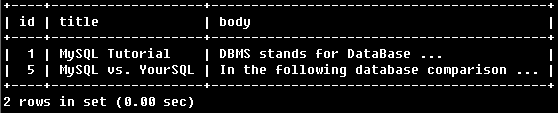
找到包含da*的行。如包含DataBase、database等。
例8:
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST('"MySQL,Tutorial"' IN BOOLEAN MODE);
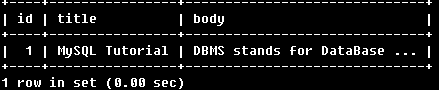
找到包含“MySQL Tutorial”短語的行。
布林全文搜尋的一些特點
? MyISAM全文搜尋會忽略至少在一半以上資料行中出現的單詞(也即所謂的50%閾值),InnoDB無此限制。而在布林全文搜尋中MyISAM的50%閾值不生效。
? 停止字列表也適用於布林全文搜尋。
? 最小和最大詞長全文搜尋引數也適用於布林全文搜尋
? MyISAM中的布林搜尋在FULLTEXT索引不存在的時候仍可工作,但速度很慢。而InnoDB表的各類全文搜尋必須有FULLTEXT索引,否則會出現找不到與指定列相匹配的FULLTEXT索引的錯誤
? InnoDB中的全文搜尋不支援在單一搜索單詞前使用多個操作符如“++MySQL”。MyISAM中全文搜尋可以處理這種情況,但是會忽略除了緊鄰單詞之外的其他操作符。
4.3查詢擴充套件全文搜尋
某些時候我們通過全文搜尋來查詢包含某方面內容的行,比如我們搜尋“database”,實際上我們期望返回結果不僅僅是僅包含“database”單詞的行,一些包含“MySQL”、“SQLServer”、“Oracle”、“DB2”、“RDBMS”等的行也期望被返回。這個時候查詢擴充套件全文搜尋就能大顯身手。
通過在AGAINST()函式中指定WITHQUERY EXPANSION 或者IN NATURAL MODE WITH QUERY EXPANSION可以開啟查詢擴充套件全文搜尋模式。其工作原理是執行兩次搜尋,第一次用給定的短語搜尋,第二次使用給定的短語結合第一次搜尋返回結果中相關性非常高的一些行進行搜尋。
例1:
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('database' IN NATURAL LANGUAGE MODE);
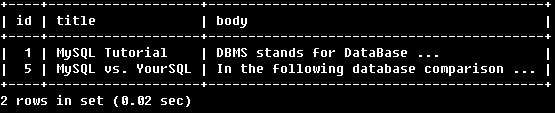
使用自然語言搜尋返回了包含“database”的行。
例2:
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('database' WITH QUERY EXPANSION);
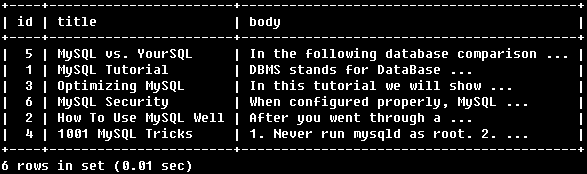
使用查詢擴充套件全文搜尋,不進返回了包含“database”的行,也返回了與例1中返回的行的內容相關的行。
注意事項
因為查詢擴充套件會返回一些不相關的內容,因此會顯著的引入噪聲。索引僅當要查詢的短語較短時才在考慮使用查詢擴充套件全文搜尋。
4.4全文搜尋的停止字
上文已經簡單介紹過了停止字列表,這裡做詳細介紹。停止字列表用MySQL Server所使用的字符集和校對集(分別由character_set_server和collation_server兩個引數控制)載入並執行搜尋。若用於全文索引和搜尋的停止字檔案或者停止字表使用了與MySQL Server不同的字符集和校對集會則導致查詢停止字時錯誤的命中或未命中。
停止字查詢的大小寫敏感性也依賴於MySQL Server所使用的校對集,例如校對集為latin1_swedish_ci則查詢是大小寫不敏感的,若校對集為latin1_geberal_cs或者latin1_bin則查詢是大小寫敏感的。
InnoDB預設的停止字列表相對較短(因為技術上的或者文學等方面的文件常使用較短的詞作為關鍵字或者有其他顯著意義)。InnoDB預設的停止字列表儲存在information_schema.innodb_ft_default_stopword表中。當然也可以通過自定義與innodb_ft_default_stopword表結構相同的表,填充期望的停止字,然後通過innodb_ft_server_stopword_table選項指定自定義的停止字表db_name/table_name,來改變預設的行為。另外還可以為innodb_ft_user_stopword_table選項指定含停止字的表,若同時指定了innodb_ft_default_stopword和innodb_ft_user_stopword_table則將使用後者指定的停止字表。上述操作改變所使用停止字表的操作需在建立全文索引前完成。且在指定所使用的停止字表時,表必須已經存在。
對於MyISAM可通過 ft_stopword_file選項指定所使用的停止字列表。MyISAM預設的停止字列表可在MySQL原始碼的 storage/myisam/ft_static.c檔案中找到。
4.5全文搜尋的限制
? 目前只有InnoDB和MyISAM引擎支援全文搜尋。其中InnodB表對FULLTEXT索引的支援從MySQL5.6.4開始。
? 分割槽表不支援全文搜尋。
? 全文索引適用於多數多位元組字符集。例外情況是:對於Unicode,utf8字符集可用但ucs2字符集不適用。儘管不能在ucs2列建立FULLTEXT索引,但可以在MyISAM表IN BOOLEAN MODE模式的搜尋中搜索沒有建立FULLTEXT索引的列。utf8的特性適用於utf8mb4,ucs2的特性適用於utf16、utf16e和utf32。
? 表意型語言如漢語、日語沒有諸如空格之類的單詞定界符。因此FULLTEXT解析器不能確定此類語言中詞的起止。對於此種情況要特殊處理(比如將中文轉換成一種單位元組類似英文習慣的儲存方式)。
? 允許在同一表中使用多種字符集,但FULLTEXT索引中的列必須使用同一字符集和校對集。
? MATCH()函式中的列必須與FULLTEXT索引中定義的列完全一致,除非是在MyISAM表中使用IN BOOLEAN MODE模式的全文搜尋(可在沒有建立索引的列執行搜尋,但速度很慢)。
? AGAINST()函式中的引數需為在查詢評估期間保持不變的字串常量。
? FULLTEXT搜尋的索引提示比non-FULLTEXT搜尋的索引提示要多一些限定:對於自然語言模式的全文搜尋,索引提示會被忽略而不給出任何提示,比如雖明確在查詢語句中給出了IGNORE INDEX(i)指明不使用i索引,但是該索引提示會被忽略掉,最終的查詢中仍會使用索引i;對於布林模式的全文搜尋,FOR ORDER BY和FOR GROUP BY的索引提示會被忽略,FOR JOIN和不帶FOR修飾符的索引提示不被忽略。
4.6全文搜尋引數調整
僅有少量的使用者可調引數用於調整MySQL的全文搜尋能力。可以通過修改原始碼來獲取更多對MySQL全文搜尋行為的控制。但一般情況下不推薦這麼做,除非很清楚自己在做什麼,因為這些引數已經針對效率做過調整,修改預設的行為多數情況下反而會帶來效能下降。
多數全文搜尋相關的變數不能在Server執行的時候修改。需在Server啟動時指定這些引數,或者修改完引數之後重新啟動Server。另外,某些變數修改後需要重建FULLTEXT索引。
控制最小、最大字長的配置選項對於InnoDB為:innodb_ft_min_token_size和innodb_ft_max_token_size,對於MyISAM為:ft_min_word_len 和 ft_max_word_len。改變這些選項中任意一個的值都需重建FULLTEXT索引並重啟Server。
用於停止字列表的配置選項對於InnoDB為:innodb_ft_enable_stopword、innodb_ft_server_stopword_table和innodb_ft_user_stopword_table,對於MyISAM為:ft_stopword_file。可以通過改變這些選項的值來開啟/關閉停止字過濾並指定停止字列表。修改了這些選項後需重建索引並在必要的時候重啟Server。
ft_stopword_file指定了包含停止字列表的檔案,Server預設在資料目錄搜尋該檔案除非用絕對路徑指定了檔案位置,若檔案內容為空,則會關閉MyISAM的停止字過濾功能。停止字檔案格式很靈活,可以使用任何非字母或數字的字元來界定停止字,但“_”和“’”例外,它們會被當作字的一部分處理。停止字列表使用Server預設的字符集。
MyISAM全文搜尋的50%閾值特性可通過修改原始碼來關閉,將原始碼storage/myisam/ftdefs.h中的巨集#define GWS_IN_USEGWS_PROB替換為#define GWS_IN_USE GWS_FREQ後重新編譯MySQL即可。同樣,不推薦上述方式,如果確實需要搜尋一些通用的詞,可以用布林模式的全文搜獲,此種情況下50%閾值特性不生效。
可以通過修改ft_boolean_syntax選項的值來更改MyISAM布林全文搜做中預設使用的操作符(InnoDB無此選項)。該選項可動態改變但須超級使用者許可權,另外,改變了改制後無需重建FULLTEXT索引。
可以通過多種方式更改期望被認作是單詞字元成分的字元集合。預設情況下“_”和“’”以及字母和數字被認為是組成單詞的字元,其他的被預設為定界符。例如,我們現在想把連字元“-”也作為組成單詞的字元處理,那麼可以通過如下方式完成:
? 修改MySQL原始碼,在storage/myisam/ftdefs.h檔案中找到true_word_char()和misc_word_char()兩個巨集,在任一個巨集定義裡新增“-”,重新編譯MySQL。
? 修改字符集檔案,true_word_char()巨集實際上利用“character type”表來從其他字元中區分出字母和數字。可以通過編輯字符集對應的XML檔案中<ctype><map>節點中的內容來將“-”指定為“字母“,然後將該字符集用於FULLTEXT索引。此種方式無需重新編譯MySQL。對於編輯字符集XML檔案,可參閱MySQL參考手冊CharacterDefinition Arrays部分。
http://dev.mysql.com/doc/refman/5.6/en/character-arrays.html
為InnoDB表重建FULLTEXT索引可以通過帶DROP INDEX和ADD INDEX從句的ALTER TABLE語句完成,先刪除舊的再建立新的。為MyISAM表重建FULLTEXT索引同樣可通過上述語句完成,也可以通過QUICK repair操作來重建(但通常第一種方式會更快),如:
mysql> REPAIR TABLE tbl_name QUICK;
需要特別說明的是,若通過repair表的方式來為MyISAM表重建FULLTEXT索引,則通過上述語句進行即可。用myisamchk工具也可以為MyISAM表重建索引,但是容易導致查詢產生錯誤的結果,對錶的修改可能使Server認為該表被損壞了。究其原因是因為通過myisamchk工具執行修改MyISAM表的索引的操作時,除非明確指定了要使用的引數值否則使用預設的全文索引引數值(如最小最大詞長等)重建FULLTEXT索引。導致這種情況是因為只有Server才知道這些全文索引引數值,MyISAM索引檔案中不儲存這些值。若更改過了這些值,如設定了ft_min_word_len=2,則在通過myisamchk工具修復表時要明確指定該修改過的引數值如:
shell> myisamchk --recover--ft_min_word_len=3 tbl_name.MYI
當然也可以通過在MySQL配置檔案[myisamchk]節中加入同[mysqld]節中與全文搜尋相關引數一致的引數來確保myisamchk使用最新的引數值來重建表的FULLTEXT索引。
用myisamchk為MyISAM表修改索引的替代方式是使用REPAIR TABLE、ANALYZE TABLE、 OPTIMIZE TABLE、ALTER TABLE,這些語句是由Server執行的因此可以讀取到正確的全文索引引數值,不會引起問題。
4.7為全文搜尋新增校對字符集
參考
10.4. Adding a Collation to a Character Set
12.9.7. Adding a Collation for Full-Text Indexing
5.效能對比測試
5.1測試環境
測試機:SVR644HP380
記憶體容量:8G
MySQL Server版本:5.6.12
5.2測試設計
詞彙量:6個等級,分別用vocab01k、vocab05k、vocab10k、vocab15k,vocab25k、vocab35k標記,每個等級的詞彙數如下,1000、5000、10000、15000、25000、35000。(取牛津詞典單詞部分,去重複後隨機打亂順序,分別擷取前1000、5000、10000……作為對應的詞彙量)
記錄數:20個等級,分別用rec005k、rec010k、rec015k、rec020k、……rec095k、rec100k標記,每個等級的記錄數如下,5000、10000、15000、20000、25000、30000、……、95000、100000。
根據詞彙量等級和記錄數等級分別生成含不同記錄數且表中文字列是由對應的詞彙量生成的隨機文字的表,共6*20=120個。表的儲存引擎使用InnoDB。表由id和body兩個欄位組成,分別為整型和文字型,且在body列建立了FULLTEXT索引。表名的命名規則為vocab01k_rec005k,表示該表中共含有5千條記錄,每條記錄中的body列由vocab01k對應的詞彙量生成的隨機單片語成,以此類推。每行記錄中的body列定為由50個隨機單片語成。
比較兩類查詢:LIKE從句查詢以及使用FULLTEXT索引的MATCH()AGAINST()查詢。在每個表上分別執行LIKE查詢和MATCH() AGAINST()全文查詢,每個表上的每個查詢分別執行50次,記錄每次所耗費的時間。對於每50個消耗的時間,刪除其最大兩個值和最小兩個值,取剩餘值的均值作為查詢耗時的最終結果。這樣一共可獲得120*2 = 240個時間資料,根據這些資料繪圖。在每個表上執行的查詢如下(其中random_word1、random_word2、random_word3是根據查詢時表對應的詞彙量生成的隨機單詞。):
LIKE搜尋:
SELECT body FROM table_name WHERE body LIKE "%random_word1%" AND bodyLIKE "% random_word2%" AND body LIKE "% random_word3%";
FULLTEXT搜尋:
SELECT body FROM table_name WHERE MATCH(body) AGAINST("+random_word3 + random_word3+ random_word3" IN BOOLEAN MODE)
5.3測試結果
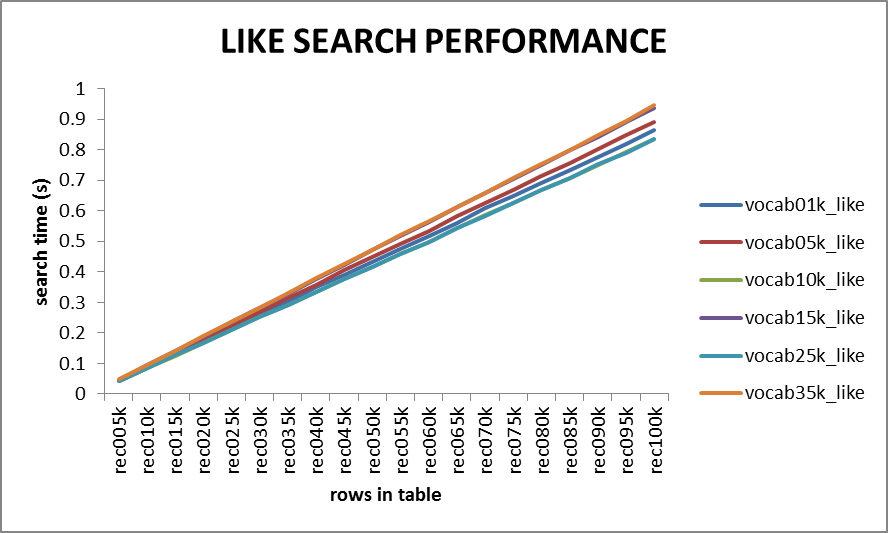
圖示
LIKE搜尋:
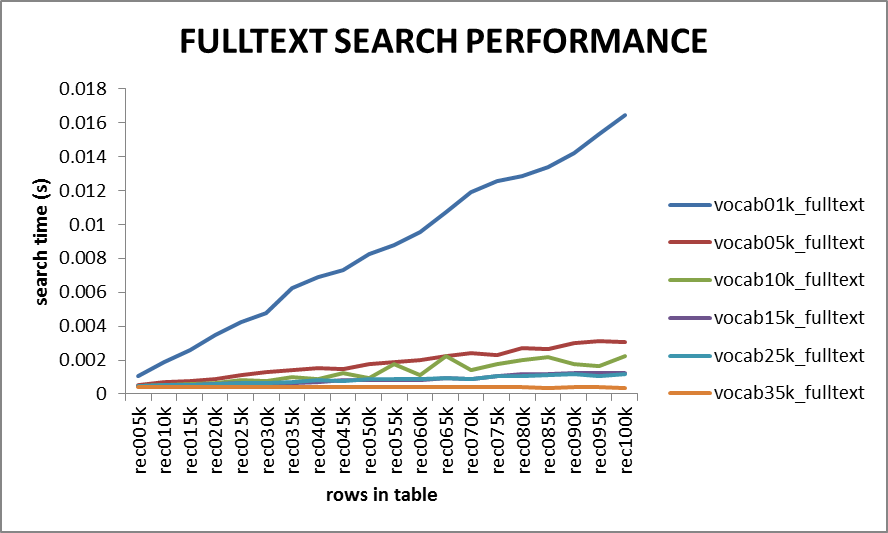
FULLTEXT搜尋:
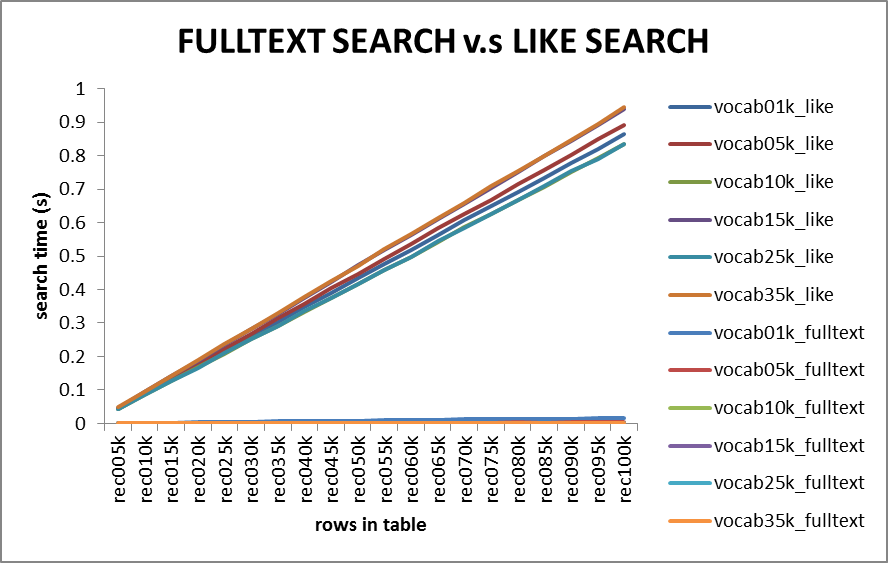
FULLTEXT搜尋與LIKE搜尋對比:
結果討論
LIKE搜尋的耗時隨著記錄數的增加而線性增長,但對於10萬行記錄以下的表(這裡共100000*50個單詞)搜尋時間基本上能保持在1秒以內,所以like搜尋的效能也不是特別差。由不同詞彙量生成的文字對LIKE搜尋的效能影響不大,不同詞彙量對應的搜尋時間基本上在一個很小的時間範圍內變化。
FULLTEXT搜尋耗時也隨表中記錄數的增長而線性增加。對於10萬行記錄以下的表(這裡共100000*50個單詞)搜尋時間基本上能保持在0.01秒以內。由不同詞彙量生成的隨機文字對FULLTEXT搜尋效能有相對來說比較顯著的影響。每行記錄中含同樣的單詞數,這樣,較大的詞彙量傾向於生成冗餘度更低的文字,相應的搜尋耗時傾向於更少。這可能與FULLTEXT索引建立單詞索引的機制有關,較大的詞彙量傾向於生成範圍廣但相對較淺的索引,因而能快速確定文字是否匹配。
與LIKE搜尋相比,FULLTEXT全文搜尋的效能要強很多,對於10萬行記錄的表,搜尋時間都在0.02秒以下。因此可以將基於FULLTEXT索引的文字搜尋部署於網站專案中的文字搜尋功能中。但是,正如上述提到的,無論是LIKE搜尋還是FULLTEXT搜尋,其效能都會隨著記錄數的增長而下降,因此,若網站專案中的文字搜尋資料庫記錄數龐大的一定規模後,可能需要考慮使用MySQL資料庫全文搜尋以外的文字搜尋解決方案了。