
Python爬蟲-程序池方式爬取頭條視訊
阿新 • • 發佈:2019-02-15
首先進入今日頭條視訊首頁。
分析網頁
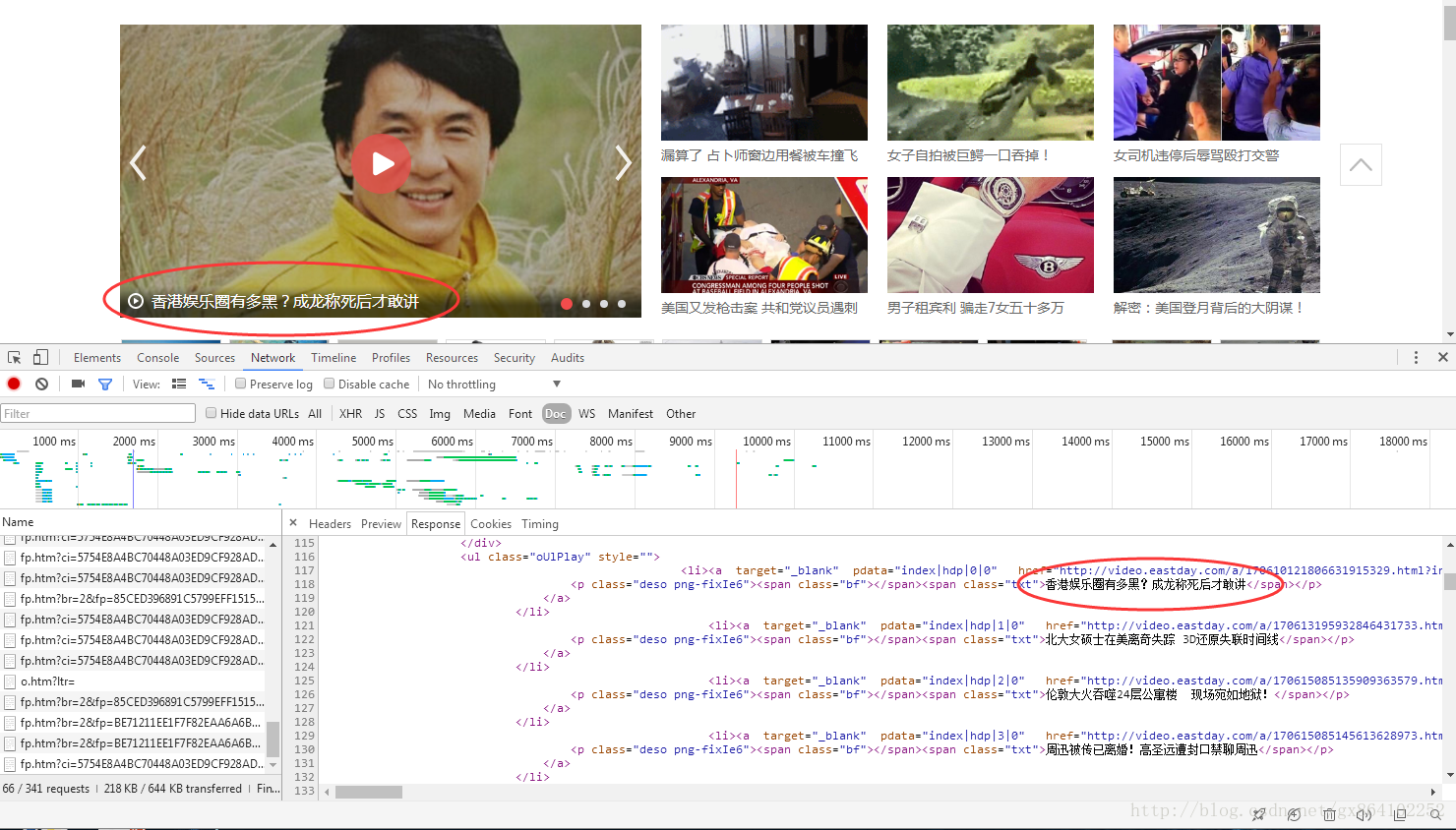
其中href屬性下的連線就是我們需要下載的視訊。
在下載全部視訊之前應該分析一下單視訊下載的方法。
下載一個視訊
首先檢視單個視訊的網頁頁面
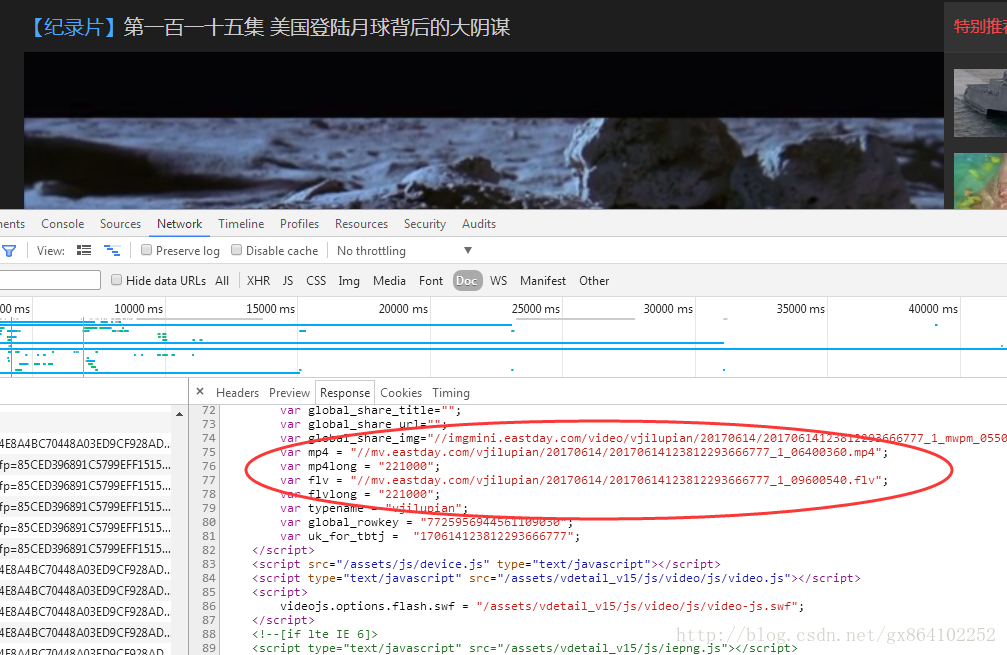
我們需要獲取var mp4下的視訊。但是這個語句應該是JS的?可以使用正則匹配到連線。
def get_video_url(url):
try:
res = requests.get(url)
if res.status_code != 200:
print('視訊詳情頁請求失敗')
return None 這個函式的返回值就是需要下載的視訊連線。
file_path = '{0}/{1}.{2}' 這樣就可以下載單個視訊了。
下載首頁全部視訊
具體正則方式,詳見網頁html格式。
#單程序使用
def get_urls():
try:
res = requests.get('http://video.eastday.com/')
if res.status_code != 200:
print('視訊主頁請求失敗' 這樣下載的方式比較慢,按順序下載。
為了提高效率,可以考慮程序池方式。
程序池方式下載視訊
假如直接加上程序池,相當於每個程序都同時開始下載同一個。。我們應該根據pool.map傳入不同引數讓不同的程序下載不同的部分。
我們觀察可以知道視訊主頁分為:主題部分、娛樂、記錄片等等。
比如這個輕鬆一刻的程式碼部分:
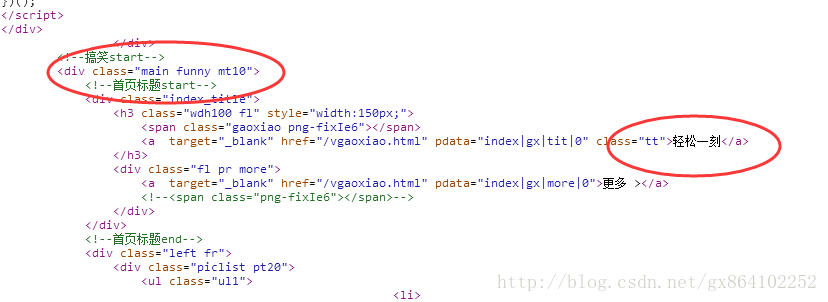
我們可以定義一個字典型別,根據引數讓不同程序完成不同部分下載。
還有一個比較重要的是。我們對於不同板塊需要重新獲取該板塊的所有url。
具體程式碼如下:
#程序池使用
def get_urls_(item_index):
try:
res = requests.get('http://video.eastday.com/')
if res.status_code != 200:
print('視訊主頁請求失敗')
return None
print('獲取視訊主頁')
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
item_dict = {
'1' : 'w100 clr pt25', #6個板塊
'2' : 'main funny mt10',
'3' : 'main mt10 consult',
'4' : 'main mt10 entertainment',
'5' : 'main mt10 Blog',
'6' : 'main mt10 record',
}
#這裡就相當於不同程序(1-6號程序) 執行不同板塊的url下載工作
html_all = soup.find_all('div', class_=re.compile(item_dict[str(item_index)]))
soup_items = BeautifulSoup(str(html_all[0]), 'html.parser') # 加上str!!! 還有它是列表!!!
soup_items = soup_items.find_all('a', pdata=re.compile("index.*"))
for item in soup_items:
if not re.findall('.*/a/.*', item['href']):
continue
if not re.findall('http://video.eastday.com/', item['href']):
item['href'] = 'http://video.eastday.com/' + item['href']
get_video_url(item['href'], item['title'])
except Exception:
print('視訊主頁請求失敗')
return None
if __name__=='__main__':
groups = [x for x in range(0, 6)]
pool = Pool()
pool.map(get_urls_, groups) #需要執行的 加上條件
除錯程式碼

可以看到是同時執行,而不是順序執行。提高效率。