
轉:生成對抗網路GANs理解(附程式碼)
from:http://blog.csdn.net/sxf1061926959/article/details/54630462
author:DivinerShi
生成模型和判別模型
理解對抗網路,首先要了解生成模型和判別模型。判別模型比較好理解,就像分類一樣,有一個判別界限,通過這個判別界限去區分樣本。從概率角度分析就是獲得樣本x屬於類別y的概率,是一個條件概率P(y|x).而生成模型是需要在整個條件內去產生資料的分佈,就像高斯分佈一樣,他需要去擬合整個分佈,從概率角度分析就是樣本x在整個分佈中的產生的概率,即聯合概率P(xy)。具體可以參考博文http://blog.csdn.net/zouxy09/article/details/8195017
對抗網路思想
理解了生成模型和判別模型後,再來理解對抗網路就很直接了,對抗網路只是提出了一種網路結構,總體來說,整個框架還是很簡單的。GANs簡單的想法就是用兩個模型,一個生成模型,一個判別模型。判別模型用於判斷一個給定的圖片是不是真實的圖片(從資料集裡獲取的圖片),生成模型的任務是去創造一個看起來像真的圖片一樣的圖片,有點拗口,就是說模型自己去產生一個圖片,可以和你想要的圖片很像。而在開始的時候這兩個模型都是沒有經過訓練的,這兩個模型一起對抗訓練,生成模型產生一張圖片去欺騙判別模型,然後判別模型去判斷這張圖片是真是假,最終在這兩個模型訓練的過程中,兩個模型的能力越來越強,最終達到穩態。(這裡用圖片舉例,但是GANs的用途很廣,不單單是圖片,其他資料,或者就是簡單的二維高斯也是可以的,用於擬合生成高斯分佈。)
詳細實現過程
下面我詳細講講:
假設我們現在的資料集是手寫體數字的資料集minst。
初始化生成模型G、判別模型D(假設生成模型是一個簡單的RBF,判別模型是一個簡單的全連線網路,後面連線一層softmax)這些都是假設,對抗網路的生成模型和判別模型沒有任何限制。
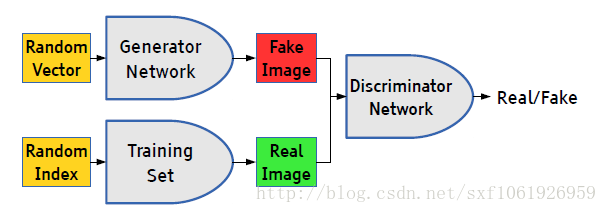
前向傳播階段
一、可以有兩種輸入
1、我們隨機產生一個隨機向量作為生成模型的資料,然後經過生成模型後產生一個新的向量,作為Fake Image,記作D(z)。
2、從資料集中隨機選擇一張圖片,將圖片轉化成向量,作為Real Image,記作x。
二、將由1或者2產生的輸出,作為判別網路的輸入,經過判別網路後輸入值為一個0到1之間的數,用於表示輸入圖片為Real Image的概率,real為1,fake為0。
使用得到的概率值計算損失函式,解釋損失函式之前,我們先解釋下判別模型的輸入。根據輸入的圖片型別是Fake Image或Real Image將判別模型的輸入資料的label標記為0或者1。即判別模型的輸入型別為
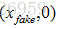
 。
。
判別模型的損失函式:
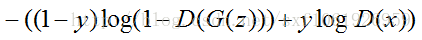
當輸入的是從資料集中取出的real Iamge 資料時,我們只需要考慮第二部分,D(x)為判別模型的輸出,表示輸入x為real 資料的概率,我們的目的是讓判別模型的輸出D(x)的輸出儘量靠近1。
當輸入的為fake資料時,我們只計算第一部分,G(z)是生成模型的輸出,輸出的是一張Fake Image。我們要做的是讓D(G(z))的輸出儘可能趨向於0。這樣才能表示判別模型是有區分力的。
相對判別模型來說,這個損失函式其實就是交叉熵損失函式。計算loss,進行梯度反傳。這裡的梯度反傳可以使用任何一種梯度修正的方法。
當更新完判別模型的引數後,我們再去更新生成模型的引數。
給出生成模型的損失函式:
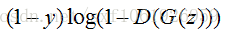
對於生成模型來說,我們要做的是讓G(z)產生的資料儘可能的和資料集中的資料一樣。就是所謂的同樣的資料分佈。那麼我們要做的就是最小化生成模型的誤差,即只將由G(z)產生的誤差傳給生成模型。
但是針對判別模型的預測結果,要對梯度變化的方向進行改變。當判別模型認為G(z)輸出為真實資料集的時候和認為輸出為噪聲資料的時候,梯度更新方向要進行改變。
即最終的損失函式為: 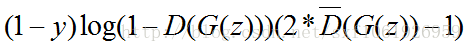
其中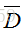
反向傳播
我們已經得到了生成模型和判別模型的損失函式,這樣分開看其實就是兩個單獨的模型,針對不同的模型可以按照自己的需要去是實現不同的誤差修正,我們也可以選擇最常用的BP做為誤差修正演算法,更新模型引數。
其實說了這麼多,生成對抗網路的生成模型和判別模型是沒有任何限制,生成對抗網路提出的只是一種網路結構,我們可以使用任何的生成模型和判別模型去實現一個生成對抗網路。當得到損失函式後就安裝單個模型的更新方法進行修正即可。
原文給了這麼一個優化函式: 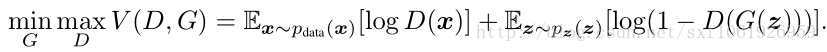
演算法流程圖
下圖是原文給的演算法流程,noise 就是隨機輸入生成模型的值。上面的解釋加上這個圖應該就能理解的差不多了。

noise輸入的解釋
上面那個noise也很好理解。如下圖所示,假設我們現在的資料集是一個二維的高斯混合模型,那麼這麼noise就是x軸上我們隨機輸入的點,經過生成模型對映可以將x軸上的點對映到高斯混合模型上的點。當我們的資料集是圖片的時候,那麼我們輸入的隨機噪聲其實就是相當於低維的資料,經過生成模型G的對映就變成了一張生成的圖片G(x)。 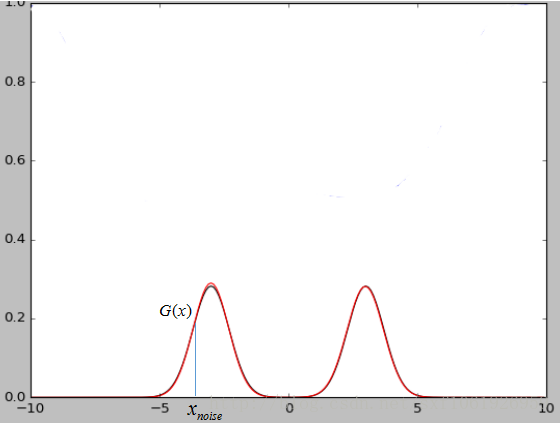
原文中也指出,最終兩個模型達到穩態的時候判別模型D的輸出接近1/2,也就是說判別器很難判斷出圖片是真是假,這也說明了網路是會達到收斂的。
GANs review
*####################################################
比如使用拉普拉斯金字塔做圖片細化,將之前的單個輸入,改成金字塔型別的多層序列輸入,後一層在前一層的基礎上進行上取樣,使得圖片的精細程度越來越高
*#####################################################
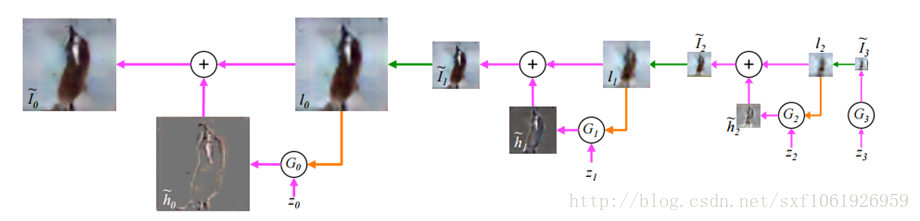
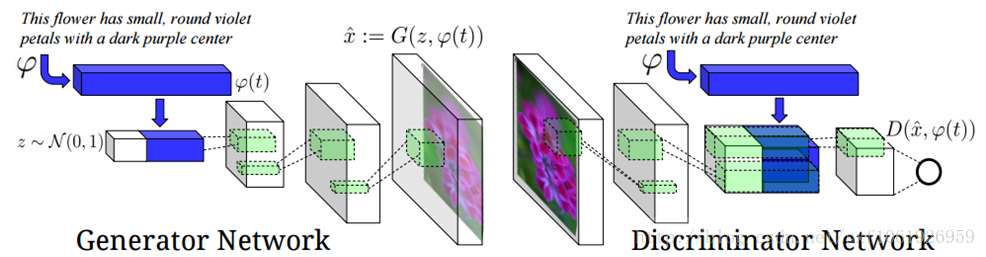
使用GANs實現將描述文字轉化成圖片,在模型中輸入一段文字,用於表示一張圖片,引入了一些NPL的概念,特別有意思的idea。網路結構如下圖所示:
*#####################################################

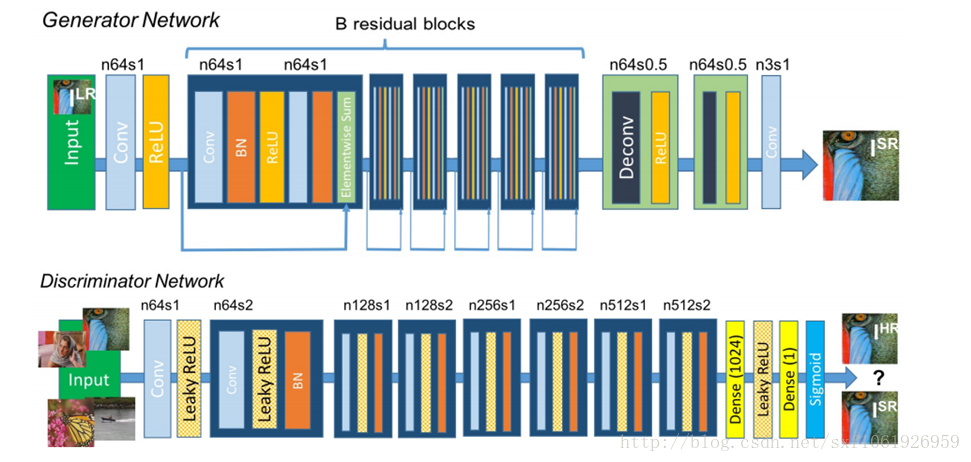
GANs做超畫素,對模糊圖片做去噪,和resnet做了結合,結構入選圖
實驗效果如下圖所示:
*#####################################################

demo 程式碼
參考文獻:
[3]Goodfellow Ian, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[C]//Advances in Neural Information Processing Systems. 2014: 2672-2680.
感謝葉博的細心指導
-
完