
一文入門人工智慧的掌上明珠:生成對抗網路(GAN)
一.簡介
在人工智慧領域內,GAN是目前最為潮流的技術之一,GAN能夠讓人工智慧具備和人類一樣的想象能力。只需要給定計算機一定的資料,它就可以自動聯想出相似的資料。我們學習和使用GAN的原因如下:
1.能夠用GAN進行無監督學習:深度學習需要大量資料的標註才能夠進行監督學習,而使用GAN則不需要使用大量標註的資料,可以直接生成資料進行無監督學習,比如使用GAN進行影象的語義分割,我們甚至根本不需要標註影象,計算機就可以自動對影象進行語義分割,目標檢測等等。
2.使用GAN可以進行影象的風格遷移:我們可以將一段馬的視訊變成斑馬,將一段真實世界裡的視訊變成動漫世界
3.使用GAN可以輸入文字就輸出影象:我們只需要隨便對計算機說一句話,計算機就可以根據這段話想象出所對應的場景。
4.GAN:使用Gan可以恢復影象的解析度,讓影象變得更加清晰,或者去掉馬賽克。比如前幾個月的老北京專案,將100年前的一段北京街頭的黑白視訊變成了高清的彩色視訊。
二.GAN的發展歷史
GAN實際上從2014年才提出來,目前也只走過了6年的時間,當時Yun Lecun(LeNet-5的發明者)在Twitter上評論說GAN是人工智慧領域最有頂尖的技術,但是因為在今年他所提出的去馬賽克技術,因技術還不夠成熟,將奧巴馬(黑人)的打馬賽克之後的影象去掉馬賽克變成了白人,刺激了美國的種族主義者,因此把他罵退了Twitter的賬號,Gan的發展歷程如下:
從DCGANs開始人們第一次在生成對抗網路當中引入了深度神經網路的思想,從而讓GAN的效果得到極大的提升。那麼GAN的基本結構是怎麼的呢?
三.生成式對抗網路的結構
生成對抗網路GAN的結構如下: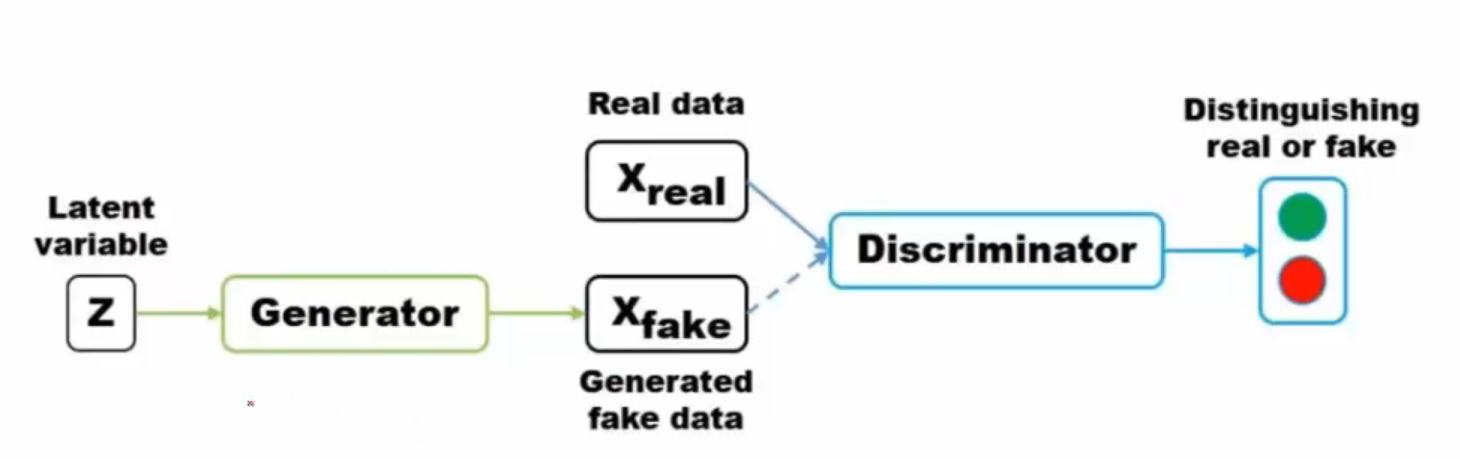
整個結構具有兩個神經網路,一個是Generator神經網路,另一個則是Discriminator神經網路。Generator接受一個隨機噪聲(隨機的一個向量的值)用於生成假的圖片,Discriminator通過判定生成的圖片和真實圖片之間的差異來形成loss,同時在判定的時候更新自己的引數,直到能夠完全分辨出假的圖片和真實的圖片,讓loss變到最大為止。如下圖所示就是一個用於生成二次元妹子頭像的生成式對抗網路:

那麼我們整個訓練的步驟是怎樣的呢?
第一步:
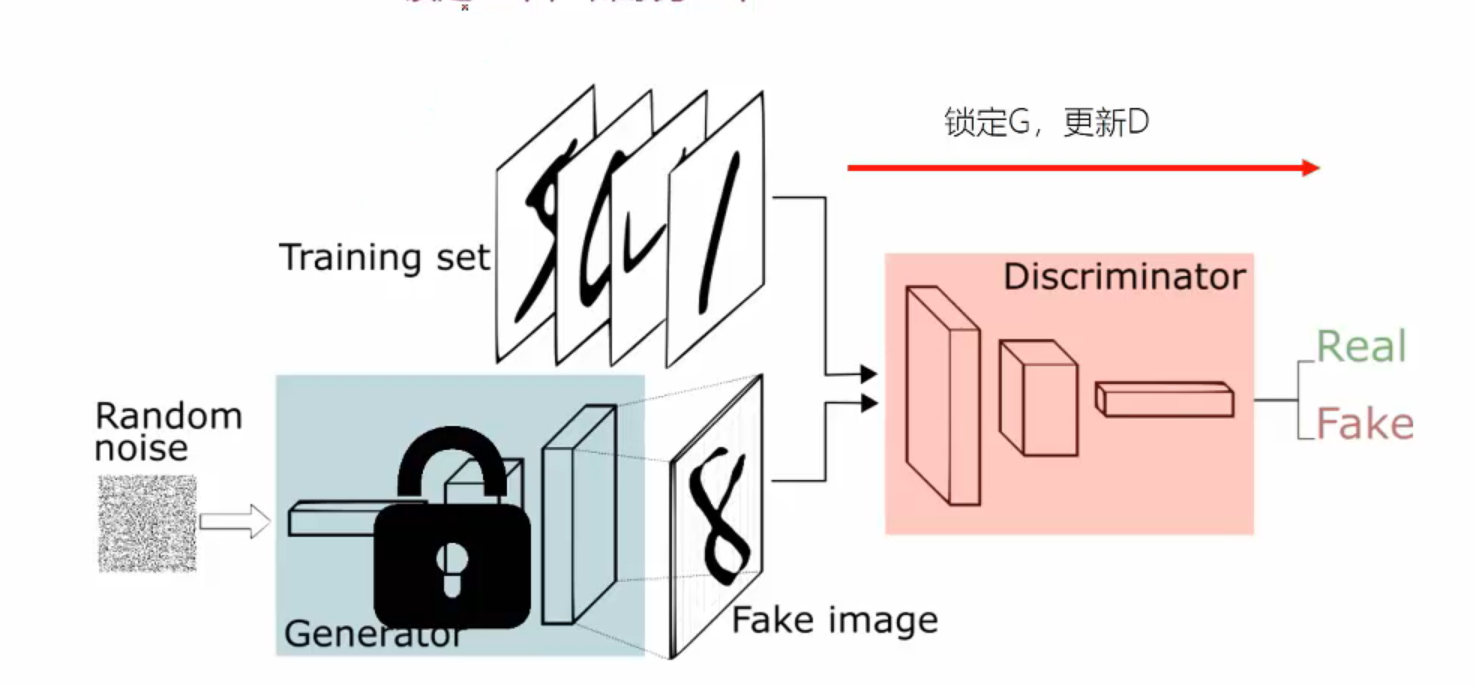
首先生成Fake image,然後固定住Generator,讓其不更新引數,通過更新Discriminator的引數來讓loss更小,這裡的loss衡量的是什麼呢??假設真是的影象的label為1,生成的fake image為0,loss就是衡量的Discriminator是否將真實的圖片label為1以及將假的圖片衡量為0的準確度,loss因此越小越好。從而使Discriminator能夠區分真的圖片和假的圖片。
第二步:

我們直接固定住Discriminator和Trainnig Set,更新Generator的引數,使Discriminator的loss越來越大,讓Discriminator根本無法分辨。這個時候引數更新又重複之間的第一步,固定住Generator,不斷地迭代。最終就可以讓生成的圖片完全讓人類的肉眼無法分辨其真假。
四.GAN的缺點
第一點是:根據實驗可得,生成式對抗網路不容易梯度下降達到全域性最優點,如下所示:
第二點則是容易出現模式坍塌,也就是訓練出來的結果很可能讓計算機喪失生成視訊或者圖片的多樣性。比如說我們使用GAN生成的妹子圖片和真實圖片幾乎像克隆人一般一模一樣,從而喪失了GAN的想象力。
五.常見的對抗生成網路(GAN)
1.DCGAN是一種十分常見的對抗生成網路,如下圖所示:
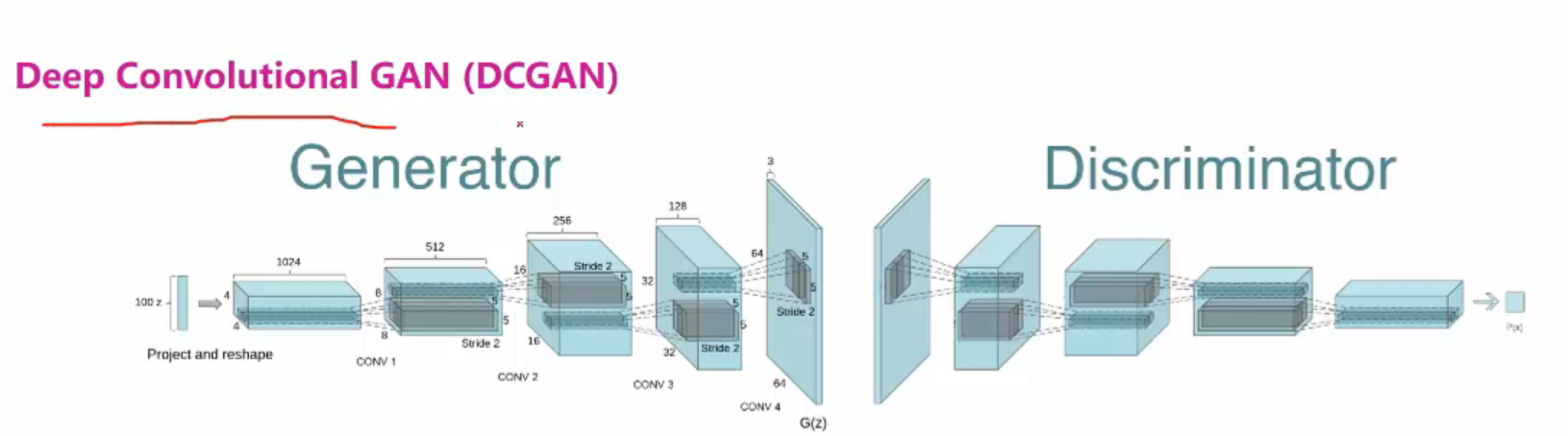
和原始GAN不同的是:
1.原始gan全都使用了全連線神經網路進行訓練,而DCGAN將全連線網路層都替換成了卷積神經網路。
2.並在每一層之後添加了Batch Normilization,從而加速了訓練,提升了訓練的穩定性。
3.Generator的Hidden Layer都使用了Relu作為啟用函式,Generator的最後一層使用了Tanh,Discriminator則使用了leakrelu作為了啟用函式,可以防止梯度稀疏。
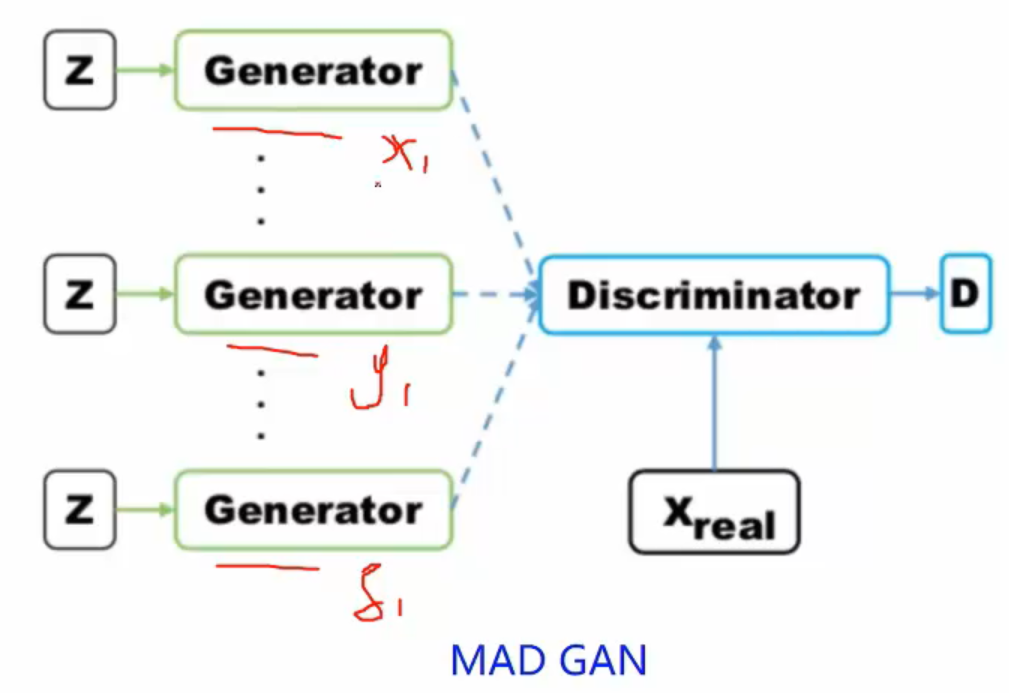
2.Multi agent diverse GAN(MAD-GAN)
通過增加多個生成器,從而讓GAN生成的物件更加豐富:
這就是GAN入門所需要了解的知識啦!希望您看了有所收穫,小編寫得也挺辛苦的,如果覺得還行的話,不要忘了點選右下角的“推薦”呀!
&n