
模型彙總18 強化學習(Reinforcement Learning)基礎介紹
1、背景介紹
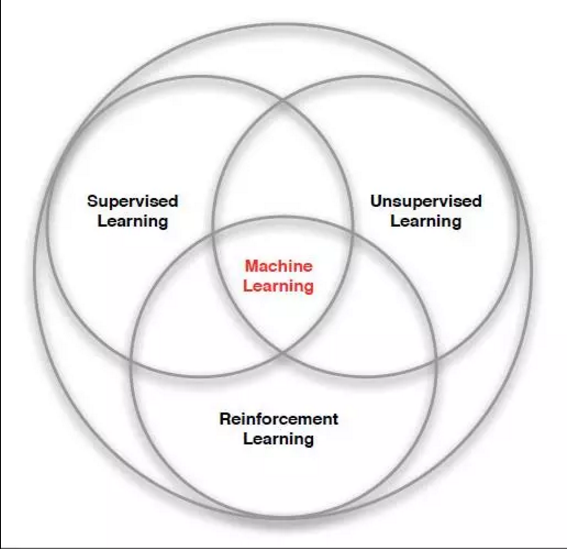
學習和推理是人類智慧最重要的體現,為了使計算機也能夠像人一樣學習和決策,機器學習技術應運而生。機器學習利用計算機來模擬和實現人類學習和解決問題的過程,計算機系統通過不斷自我改進和學習,自動獲取知識並作出相應的決策、判斷或分析。機器學習是人工智慧的一個重要的研究領域,根據是否從系統中獲得反饋,可以把機器學習分為有監督、無監督和強化學習三大類。
監督學習也稱有導師學習,給定系統一組輸入時,需要給定一組對應的輸出,系統在一種已知輸入-輸出資料集的環境習學習。與監督學習相反的是無監督學習,也稱無導師學習。無監督學習中,只需要給定一組輸出,不需要給定對應的輸出,系統自動根據給定輸入的內部結構來進行學習。有監督和無監督的機器學習模式可以解決絕大多數的機器學習問題,但這兩種機器學習模式同人類學習、生物進化的過程有很大的不同。生物的進化是一種主動對環境進行試探,並根據試探後,環境反饋回來的結果進行評價、總結,以改進和調整自身的行為,然後環境會根據新的行為作出新的反饋,持續調整的學習過程。體現這一思想的學習模式在機器學習領域稱為強化學習(Reinforcement Learning, RL),又稱增強學習。因此,強化學習是一種痛有監督學習、無監督學習並列的機器學習模式。
2、強化學習系統
整個強化學習系統由智慧體(Agent)、狀態(State)、獎賞(Reward)、動作(Action)和環境(Environment)五部分組成,系統示意圖如下圖所示。
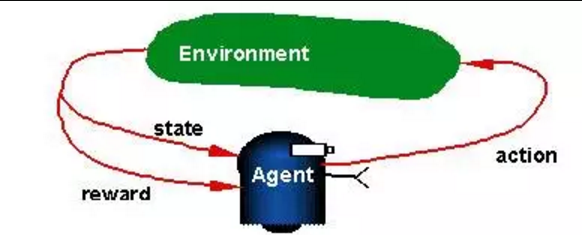
智慧體(Agent):Agent是整個強化學習系統核心。它能夠感知環境的狀態(State),並且根據環境提供的強化訊號(Reward Si),通過學習選擇一個合適的動作(Action),來最大化長期的Reward值。簡而言之,Agent就是根據環境提供的Reward做為反饋,學習一系列的環境狀態(State)到動作(Action)的對映,動作選擇的原則是最大化未來累積的Reward的概率。選擇的動作不僅影響當前時刻的Reward,還會影響下一時刻甚至未來的Reward,因此,Agent在學習過程中的基本規則是:如果某個動作(Action)帶來了環境的正回報(Reward),那麼這一動作會被加強,反之則會逐漸削弱,類似於物理學中條件反射原理。
環境(Environment):環境會接收Agent執行的一系列的動作(Action),並且對這一系列的動作的好壞進行評價,並轉換成一種可量化的(標量訊號)Reward反饋給Agent,而不會告訴Agent應該如何去學習動作。Agent只能靠自己的歷史(History)經歷去學習。同時,環境還像Agent提供它所處的狀態(State)資訊。環境有完全可觀測(Fully Observable)和部分可觀測(Partial Observable)兩種情況。
獎賞(Reward):環境提供給Agent的一個可量化的標量反饋訊號,用於評價Agent在某一個時間步(time Step)所做action的好壞。強化學習就是基於一種最大化累計獎賞假設:強化學習中,Agent進行一系列的動作選擇的目標是最大化未來的累計獎賞(maximization of future expected cumulative Reward)。
歷史(History):歷史就是Agent過去的一些列觀測、動作和reward的序列資訊: Ht = S1,R1,A1,.......At-1,St,Rt。 Agent根據歷史的動作選擇,和選擇動作之後,環境做給出的反饋和狀態,決定如何選擇下一個動作(At)。
狀態(State):狀態指Agent所處的環境資訊,包含了智慧體用於進行Action選擇的所有資訊,它是歷史(History)的一個函式:St = f(Ht)。
可見,強化學習的主體是Agent和環境Environment。Agent為了適應環境,最大化未來累計獎賞,做出的一些列的動作,這個學習過程稱為強化學習。
3、強化學習的基本要素
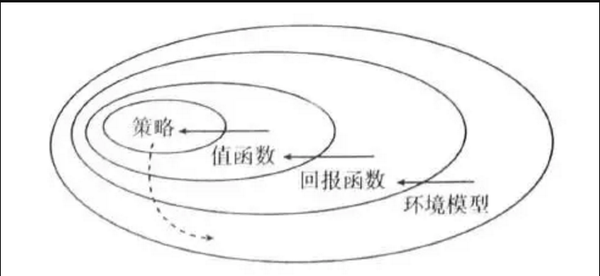
一個強化學習系統,除了Agent和環境(Environment)之外,還包括其他四個要素:策略(Policy,P)、值函式(Value Function,V)、回報函式(Reward Function ,R)和環境模型(Environment Model),其中,環境模型是可以有,也可以沒有(Model Free)。這四個要素之間的關係如下圖所示。
策略(Policy):表示狀態到動作的對映。策略的表示式如下。
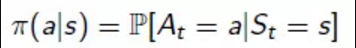
定義Agent在t時刻的行為方式,直接決定Agent的行動,是整個強化學習系統的核心。策略pi : S X A -> [0,1]或者pi: S -> A,表示在狀態S下選擇動作A的概率,其中,S代表Agent所有狀態State的集合(狀態空間),A代表Agent所有動作集合(動作空間)。在任意的狀態(State)下,存在由策略pi組成了策略集合F,任意策略pi屬於F,在策略集合存在一個使問題具有最優效果的策略pi*,稱為最優策略,強化學習的目的尋找最優的策略pi*。
回報函式(Reward Function):定義了強化學習問題的目標,Agent通過一些列的策略(Policy)選擇,最終通過回報函式對映到一個Reward訊號,產生關於一個動作好會的評價。Reward訊號是一個標量,一般採用正數表示獎賞,負數表示懲罰。
值函式(Value Function):回報函式計算當前的策略的好壞,但沒法衡量策略未來的好壞,因此,通過值函式(Value Function)來預測未來的Reward的值,從長遠角度來評價策略的好壞。為什麼需要從未來角度來衡量策略pi的好壞?有兩個原因:1、環境對於策略的給出的評價往往是由延遲的;2、Agent選擇的當前動作或者策略,會對未來的狀態或者策略選擇產生影響,Agent在進行動作選擇時,某些動作產生的當前回報值比較高,但從長遠來看,可能並沒有那麼高。因此,需要採用值函式(Value Function)來評估Agent所處的狀態的好壞,指導Agent進行動作(Action)的選擇。值函式的表示式如下。
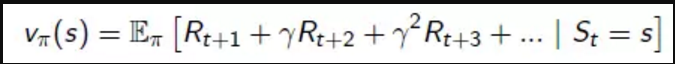
環境模型(Environment Model):它使強化學習系統中可選的部分。將強化學習和動態規劃等方法結合在一起,環境模型用於模擬環境的行為方式,比如,給定一個狀態和動作情況下,環境模型可以預測下一步的狀態和回報。藉助環境模型,Agent可以在進行策略選擇時,考慮未來可能發生的情況,提前進行規劃。用P表示下一步狀態,R表示下一步的回報,環境模型可以表示成如何形式。
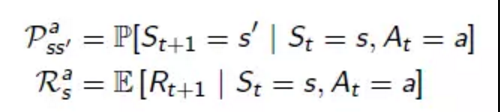
往期內容推薦:
更多深度學習在NLP方面應用的經典論文、實踐經驗和最新訊息,歡迎關注微信公眾號“深度學習與NLP”或“DeepLearning_NLP”或掃描二維碼新增關注。
