
輕量化卷積神經網路:SqueezeNet、MobileNet、ShuffleNet、Xception
一 引言
自2012年AlexNet以來,卷積神經網路(簡稱CNN)在影象分類、影象分割、目標檢測等領域獲得廣泛應用。隨著效能的要求越來越高,AlexNet已經無法滿足大家的需求,於是乎各路大牛紛紛提出效能更優越的CNN網路,如VGG,GoogLeNet,ResNet,DenseNet等。由於神經網路的性質,為了獲得更好的效能,網路層數不斷增加,從7層AlexNet到16層VGG,再從16層VGG到GoogLeNet的22層,再從22層到152層ResNet,更有上千層的ResNet和DenseNet。雖然網路效能得到了提高,但隨之而來的就是效率問題。
效率問題主要是模型的儲存問題和模型進行預測的速度問題
第一,儲存問題。數百層網路有著大量的權值引數,儲存大量權值引數對裝置的記憶體要求很高;
第二,速度問題。在實際應用中,往往是毫秒級別,為了達到實際應用標準,要麼提高處理器效能(看英特爾的提高速度就知道了,這點暫時不指望),要麼就減少計算量。
只有解決CNN效率問題,才能讓CNN走出實驗室,更廣泛的應用於移動端。對於效率問題,通常的方法是進行模型壓縮(Model Compression),即在已經訓練好的模型上進行壓縮,使得網路攜帶更少的網路引數,從而解決記憶體問題,同時可以解決速度問題。
相比於在已經訓練好的模型上進行處理,輕量化模型模型設計則是另闢蹊徑。輕量化模型模型設計,主要思想在於設計更高效的“網路計算方式”(主要針對卷積方式),從而使網路引數減少的同時,不損失網路效能。
本文就近年提出的四個輕量化模型進行學習和對比,四個模型分別是:SqueezeNet, MobileNet, ShuffleNet, Xception
(PS: 以上四種模型都不是模型壓縮方法!!)
以下是4個模型的作者團隊及發表時間
其中ShuffleNet論文中引用了SqueezeNet、Xception、MobileNet;Xception 論文中引用了MobileNet
二 輕量化模型
由於這四種輕量化模型僅是在卷積方式上提出創新,因此本文僅對輕量化模型的創新點進行詳細描述,對模型實驗以及實現的細節感興趣的朋友,請到論文中詳細閱讀。
2.1 SqueezeNet
SqueezeNet由伯克利&斯坦福的研究人員合作發表於ICLR-2017,論文標題:
《SQUEEZENET: ALEXNET-LEVEL ACCURACY WITH 50X FEWER PARAMETERS AND <0.5MB MODEL SIZE》
(http://blog.csdn.net/u011995719/article/details/78908755)
命名
從名字SqueezeNet就知道,本文的新意是squeeze,squeeze在SqueezeNet中表示一個squeeze層,該層採用1*1卷積核對上一層feature map進行卷積,主要目的是減少feature map的維數(維數即通道數,就是一個立方體的feature map,切成一片一片的,一共有幾片)。
創新點
1. 採用不同於傳統的卷積方式,提出fire module;fire module包含兩部分:squeeze層+expand層
創新點與inception系列的思想非常接近!首先squeeze層,就是1*1卷積,其卷積核數要少於上一層feature map數,這個操作從inception系列開始就有了,並美其名曰壓縮,個人覺得“壓縮”更為妥當。
Expand層分別用1*1 和3*3 卷積,然後concat,這個操作再inception系列裡面也有。
—————————————-分割線———————————
SqueezeNet的核心在於Fire module,Fire module 由兩層構成,分別是squeeze層+expand層,如下圖1所示,squeeze層是一個1*1卷積核的卷積層,expand層是1*1 和3*3卷積核的卷積層,expand層中,把1*1 和3*3 得到的feature map 進行concat。
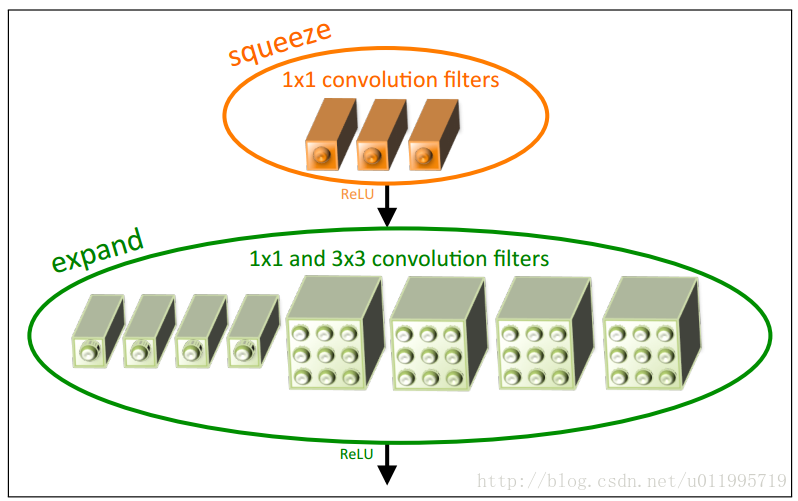
具體操作情況如下圖所示:
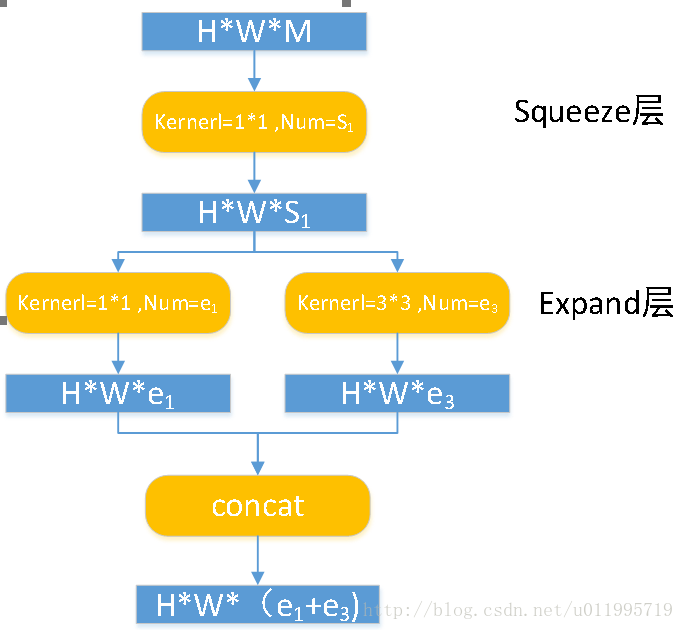
Fire module輸入的feature map為H*W*M的,輸出的feature map為H*M*(e1+e3),可以看到feature map的解析度是不變的,變的僅是維數,也就是通道數,這一點和VGG的思想一致。
首先,H*W*M的feature map經過Squeeze層,得到S1個feature map,這裡的S1均是小於M的,以達到“壓縮”的目的,詳細思想可參考Google的Inception系列。
其次,H*W*S1的特徵圖輸入到Expand層,分別經過1*1卷積層和3*3卷積層進行卷積,再將結果進行concat,得到Fire module的輸出,為 H*M*(e1+e3)的feature map。
fire模組有三個可調引數:S1,e1,e3,分別代表卷積核的個數,同時也表示對應輸出feature map的維數,在本文提出的SqueezeNet結構中,e1=e3=4s1 。
講完SqueezeNet的核心——Fire module,看看SqueezeNet的網路結構,如下圖所示:
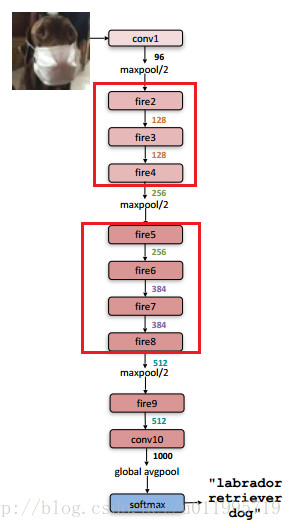
網路結構設計思想,同樣與VGG的類似,堆疊的使用卷積操作,只不過這裡堆疊的使用本文提出的Fire module(圖中用紅框部分)
看看Squezeenet的引數數量以及效能:
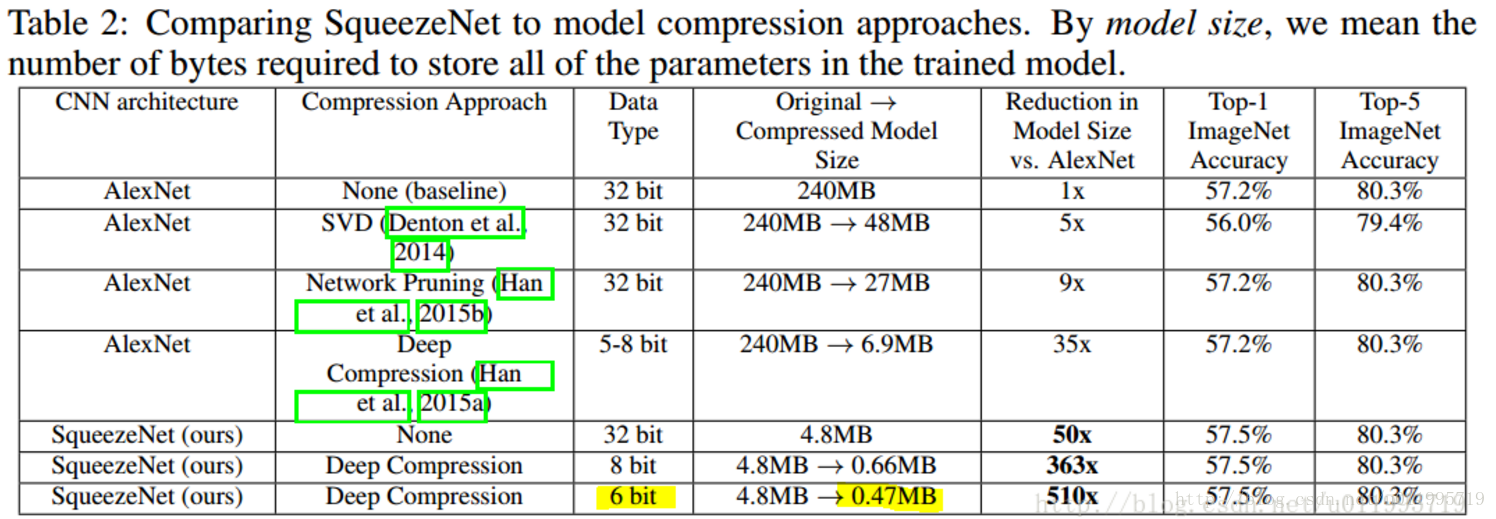
在這裡可以看到,論文題目中提到的小於0.5M,是採用了Deep Compression進行模型壓縮之後的結果!!
看了上圖再回頭看一看論文題目:
SqueezeNet :AlexNet-level accuracy with 50x fewer parameters and <0.5MB
標!題!黨! SqueezeNet < 0.5MB, 這個是用了別的模型壓縮技術獲得的,很容易讓人誤以為SqueezeNet可以壓縮模型!!
SqueezeNet小結:
1 Fire module 與GoogLeNet思想類似,採用1*1卷積對feature map的維數進行“壓縮”,從而達到減少權值引數的目的;
2 採用與VGG類似的思想——堆疊的使用卷積,這裡堆疊的使用Fire module
SqueezeNet與GoogLeNet和VGG的關係很大!
2.2 MobileNet
MobileNet 由Google團隊提出,發表於CVPR-2017,論文標題:
《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》(http://blog.csdn.net/u011995719/article/details/78850275)
命名
MobileNet的命名是從它的應用場景考慮的,顧名思義就是能夠在移動端使用的網路模型。
創新點
1. 採用名為depth-wise separable convolution 的卷積方式代替傳統卷積方式,以達到減少網路權值引數的目的。
通過採用depth-wise convolution的卷積方式,達到:1.減少引數數量 2.提升運算速度。(這兩點是要區別開的,引數少的不一定運算速度快!)
depth-wise convolution不是MobileNet提出來的,也是借鑑,文中給的參考文獻是 2014年的博士論文——《L. Sifre. Rigid-motion scattering for image classification. hD thesis, Ph. D. thesis, 2014》
depth-wise convolution 和 group convolution其實是一樣的,都是一個卷積核負責一部分feature map,每個feature map只被一個卷積核卷積。
———————————–分割線————————————-
MobileNets精華在於卷積方式——depth-wise separable convolution;採用depth-wise separable convolution,會涉及兩個超參:Width Multiplier和Resolution Multiplier這兩個超參只是方便於設定要網路要設計為多小,方便於量化模型大小。
depth-wise convolution是將標準卷積分成兩步:第一步 Depthwise convolution,即逐通道的卷積,一個卷積核負責一個通道,一個通道只被一個卷積核“濾波”;
第二步,Pointwise convolution,將depthwise convolution得到的feature map再“串”起來 ,注意這個“串”是很重要的。“串”作何解?為什麼還需要 pointwise convolution?作者說:However it only filters input channels, it does not combine them to create new features. Soan additional layer that computes a linear combination ofthe output of depthwise convolution via 1 × 1 convolutionis needed in order to generate these new features。
首先要承認一點:輸出的每一個feature map要包含輸入層所有feature map的資訊。僅採用depthwise-convolution,是沒辦法做到這點,因此需要pointwise convolution的輔助。
“輸出的每一個feature map要包含輸入層所有feature map的資訊” 這個是所有采用depth-wise convolution操作的網路都要去解決的問題,ShuffleNet中的命名就和這個有關!詳細請看2.3
Standard convolution、depthwise convolution和pointwiseconvolution示意圖如下:
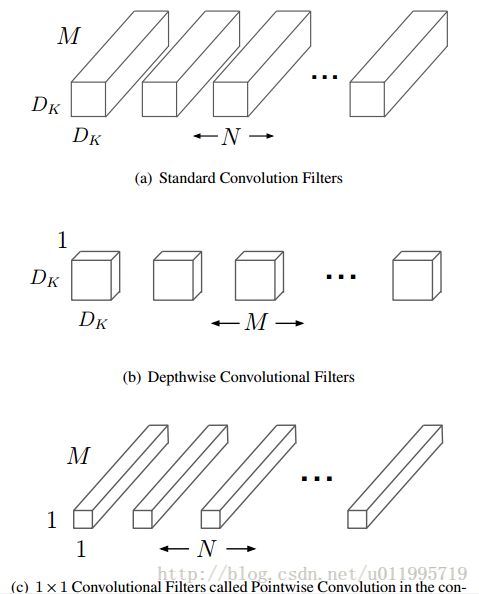
其中輸入的feature map有M個,輸出的feature map有N個。
Standard convolution呢,是採用N個大小為DK*DK的卷積核進行操作(注意卷積核大小是DK*DK, DK*DK*M是具體運算時候的大小!)
而depthwise convolution + pointwise convolution需要的卷積核呢?
Depthwise convolution :一個卷積核負責一個通道,一個通道只被一個卷積核卷積;則這裡有M個DK*DK的卷積核;
Pointwise convolution:為了達到輸出N個feature map的操作,所以採用N個1*1的卷積核進行卷積,這裡的卷積方式和傳統的卷積方式是一樣的,只不過採用了1*1的卷積核;其目的就是讓新的每一個feature map包含有上一層各個feature map的資訊!在此理解為將depthwise convolution的輸出進行“串”起來。
————————————–分割線———————————-
下面舉例講解 Standard convolution、depthwise convolution和pointwise convolution 。
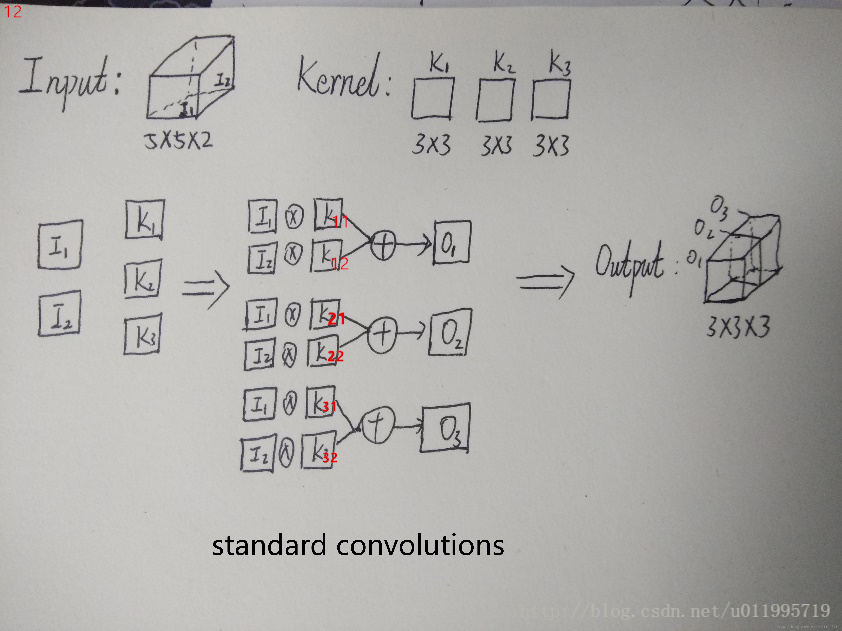
假設輸入的feature map 是兩個5*5的,即5*5*2;輸出feature map數量為3,大小是3*3(因為這裡採用3*3卷積核)即3*3*3。
標準卷積,是將一個卷積核(3*3)複製M份(M=2), 是讓二維的卷積核(麵包片)拓展到與輸入feature map一樣的麵包塊形狀。例如,我們設定3個 3*3的卷積核,如下圖Kernel所示,但是在實際計算當中,卷積核並不是3*3*3這麼多,而是3*3*2*3 ( w*h*c_in*c_out) 。也就是上面所說的把二維的卷積核拓展到與feature map一樣的麵包塊形狀,如下圖的K1 擴充套件成 K11,K12 。
(注:不是複製M份,因為每個二維卷積核的引數是不一樣的,因此不是複製!感謝DSQ_17這位朋友指出錯誤。)
2018年3月15日補充:實際上,卷積核實際的尺寸應該是 w*h*c_in*c_out。往往,我們忽略掉c_in這個數,在設定卷積核數量時,也不會涉及到這個引數,但是在計算過程中是不能忽略的。
其中,w*h就是通常我們所說的卷積核大小,例如3*3,5*5,7*7等;c_out是平時我們講的卷積核個數,例如該卷積層設定了64個卷積核,則c_out = 64;而c_in則是等於上一層的feature map的數量。
Standard過程如下圖,X表示卷積,+表示對應畫素點相加,可以看到對於O1來說,其與輸入的每一個feature map都“發生關係”,包含輸入的各個feature map的資訊。
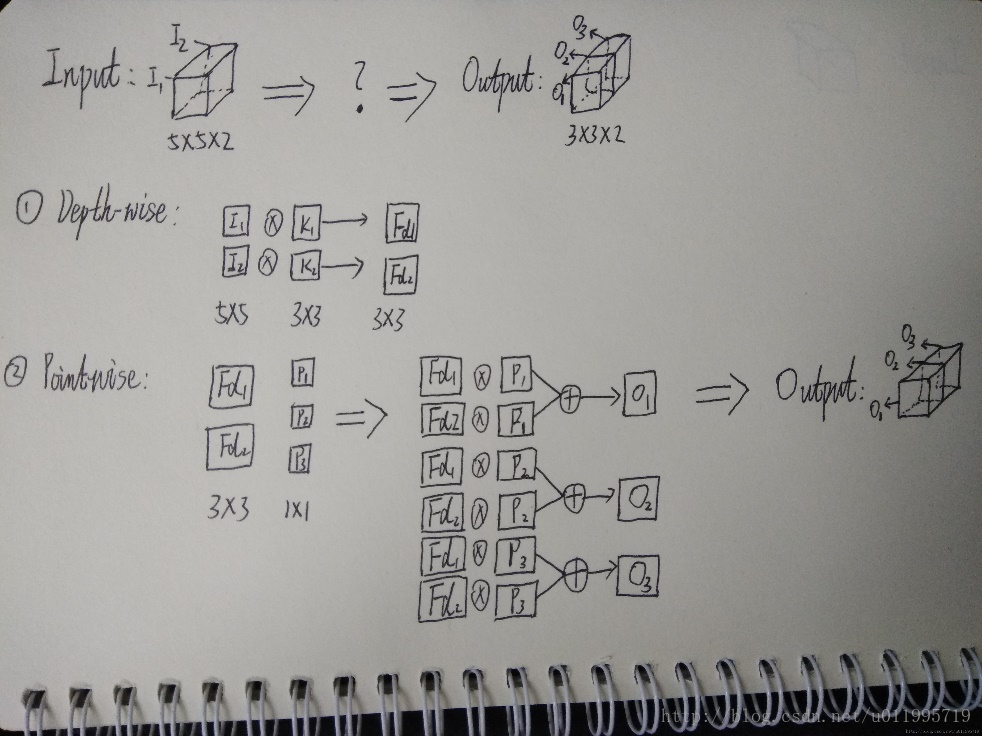
Depth-wise 過程如下圖,而Depthwise並沒有,可以看到depthwise convolution 得出的兩個feature map——fd1 和fd2分別只與i1和i2 “發生關係” ,這就導致違背上面所承認的觀點“輸出的每一個feature map要包含輸入層所有feature map的資訊”,因而要引入pointwise convolution
那麼計算量減少了多少呢?通過如下公式計算:
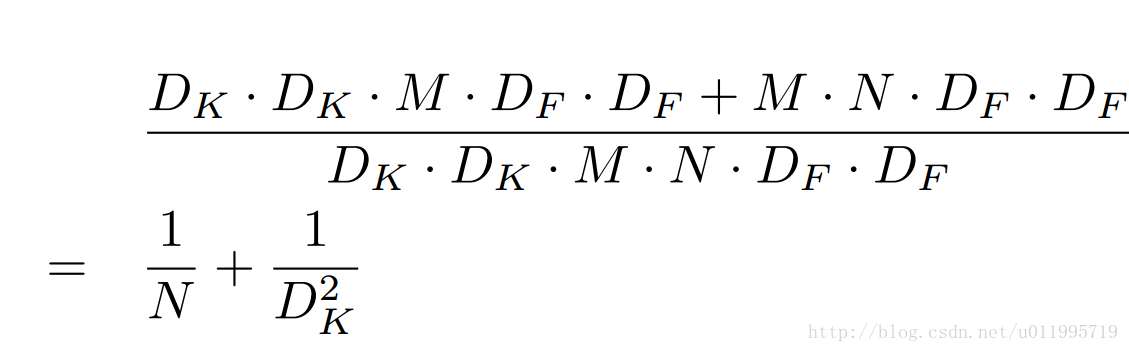
其中DK為標準卷積核大小,M是輸入feature map通道數,DF為輸入feature map大小,N是輸出feature map大小。本例中,DK=3,M=2,DF=5,N=3 , 引數的減少量主要就與卷積核大小DK有關。在本文MobileNet的卷積核採用DK=3,則大約減少了8~9倍計算量。
看看MobileNet的網路結構,MobileNet共28層,可以發現這裡下采樣的方式沒有采用池化層,而是利用depth-wise convolution的時候將步長設定為2,達到下采樣的目的。
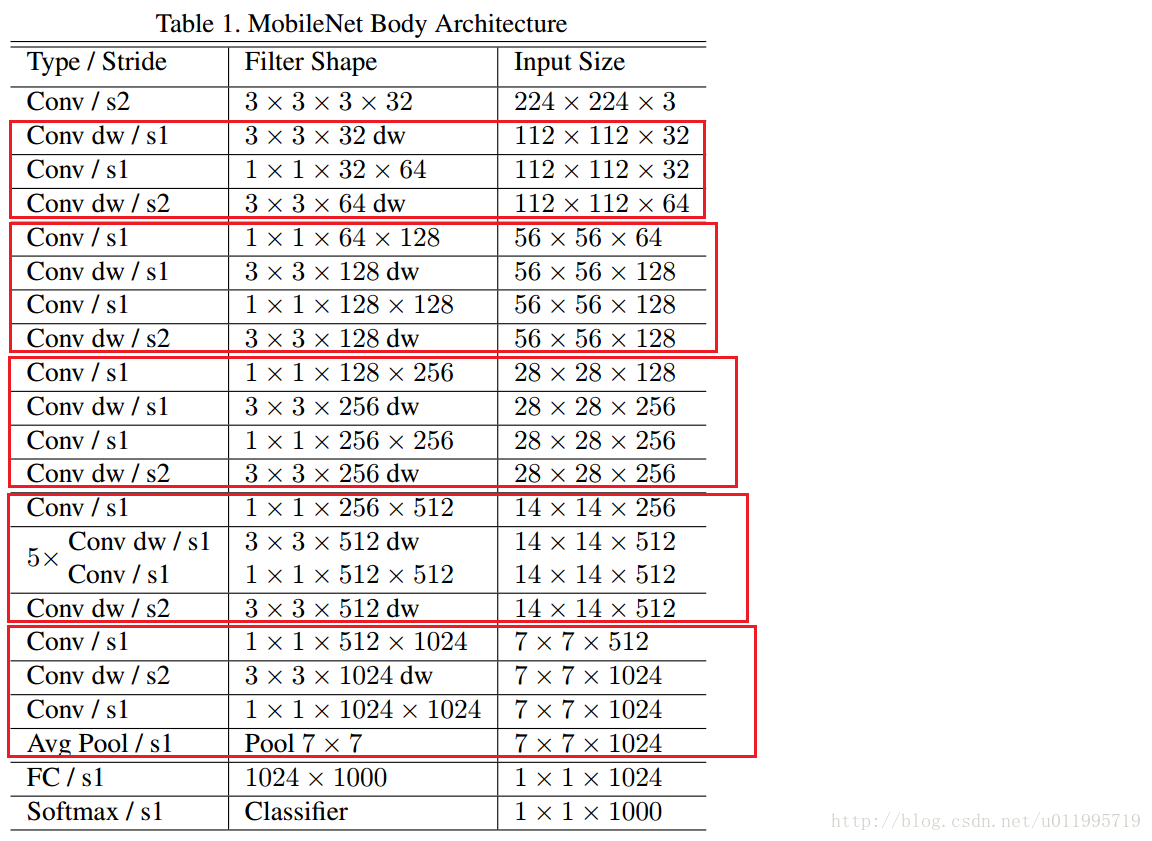
1.0 MobileNet-224 與GoogLeNet及VGG-16的對比:

可以發現,相較於GoogLeNet,雖然引數差不多,都是一個量級的,但是在運算量上卻小於GoogLeNet一個量級,這就得益於 depth-wise convolution !
MobileNet小結:
1. 核心思想是採用depth-wise convolution操作,在相同的權值引數數量的情況下,相較於standard convolution操作,可以減少數倍的計算量,從而達到提升網路運算速度的目的。
depth-wise convolution的思想非首創,借鑑於 2014年一篇博士論文:《L. Sifre. Rigid-motion scattering for image classification. hD thesis, Ph. D. thesis, 2014》
採用depth-wise convolution 會有一個問題,就是導致“資訊流通不暢”,即輸出的feature map僅包含輸入的feature map的一部分,在這裡,MobileNet採用了point-wise convolution解決這個問題。在後來,ShuffleNet採用同樣的思想對網路進行改進,只不過把point-wise convolution換成了 channel shuffle,然後給網路美其名曰 ShuffleNet~ 欲知後事如何,請看 2.3 ShuffleNet
2.3 ShuffleNet
ShuffleNet 是Face++團隊提出的,晚於MobileNet兩個月在arXiv上公開。論文標題:
《ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices 》
命名
一看名字ShuffleNet,就知道shuffle是本文的重點,那麼shuffle是什麼?為什麼要進行shuffle?
shuffle具體來說是channel shuffle,是將各部分的feature map的channel進行有序的打亂,構成新的feature map,以解決group convolution帶來的“資訊流通不暢”問題。(MobileNet是用point-wise convolution解決的這個問題)
因此可知道shuffle不是什麼網路都需要用的,是有一個前提,就是採用了group convolution,才有可能需要shuffle!! 為什麼說是有可能呢?因為可以用point-wise convolution 來解決這個問題。
創新點
1. 利用group convolution 和 channel shuffle 這兩個操作來設計卷積神經網路模型, 以減少模型使用的引數數量。
group convolutiosn非原創,而channel shuffle是原創。 channel shuffle因group convolution 而起,正如論文中3.1標題: . Channel Shuffle for Group Convolution;
採用group convolution 會導致資訊流通不當,因此提出channel shuffle,所以channel shuffle是有前提的,使用的話要注意!
對比一下MobileNet,採用shuffle替換掉1*1卷積(注意!是1*1 Conv,也就是point-wise convolution;特別注意,point-wise convolution和 1*1 GConv是不同的),這樣可以減少權值引數,而且是減少大量權值引數 ,因為在MobileNet中,1*1卷積層有較多的卷積核,並且計算量巨大,MobileNet每層的引數量和運算量如下圖所示:
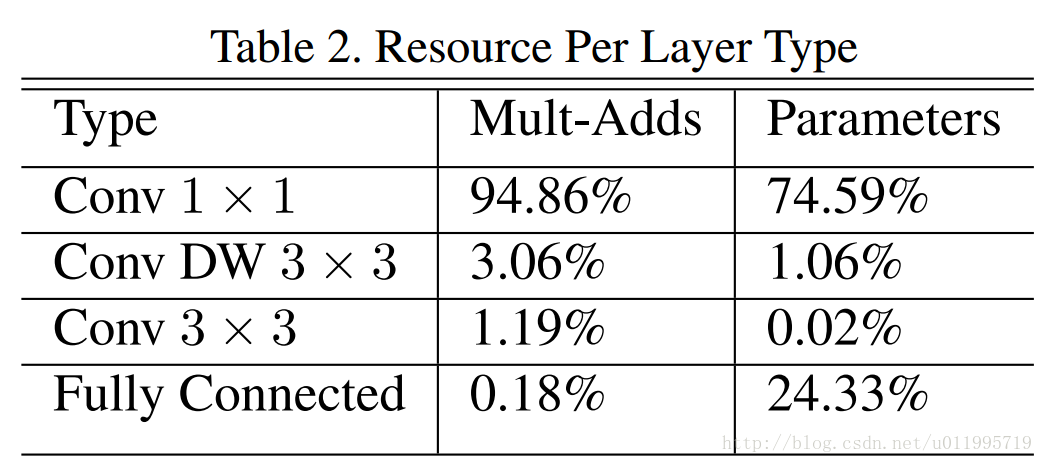
————————————–分割線———————————–
ShuffleNet的創新點在於利用了group convolution 和 channel shuffle,那麼有必要看看group convolution 和channel shuffle
Group convolution
Group convolution 自Alexnet就有,當時因為硬體限制而採用分組卷積;之後在2016年的ResNeXt中,表明採用group convolution可獲得高效的網路;再有Xception和MobileNet均採用depthwise convolution, 這些都是最近出來的一系列輕量化網路模型。depth-wise convolution具體操作可見2.2 MobileNet裡邊有簡介
如下圖(a)所示, 為了提升模型效率,採用group convolution,但會有一個副作用,即:“outputs from a certain channel are only derived from a small fraction of input channels.”
於是採用channel shuffle來改善各組間“資訊流通不暢”問題,如下圖(b)所示。
具體方法為:把各組的channel平均分為g(下圖g=3)份,然後依次序的重新構成feature map
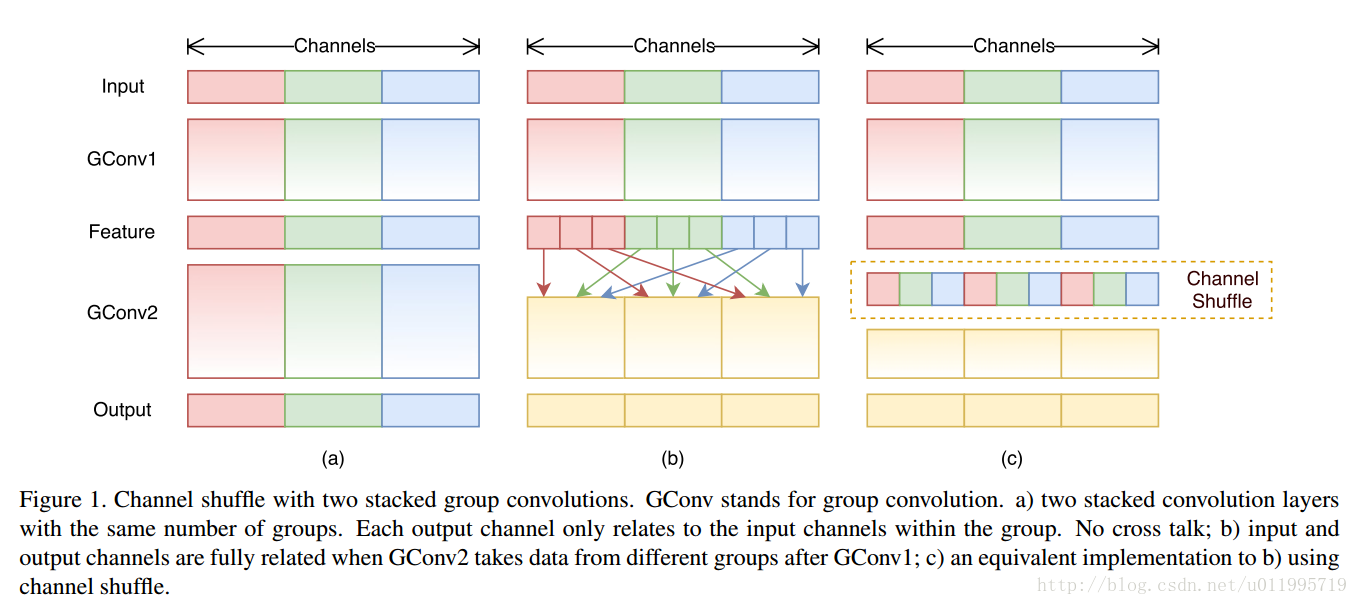
Channel shuffle 的操作非常簡單,接下來看看ShuffleNet,ShuffleNet借鑑了Resnet的思想,從基本的resnet 的bottleneck unit 逐步演變得到 ShuffleNet 的bottleneck unit,然後堆疊的使用ShuffleNet bottleneck unit獲得ShuffleNet;
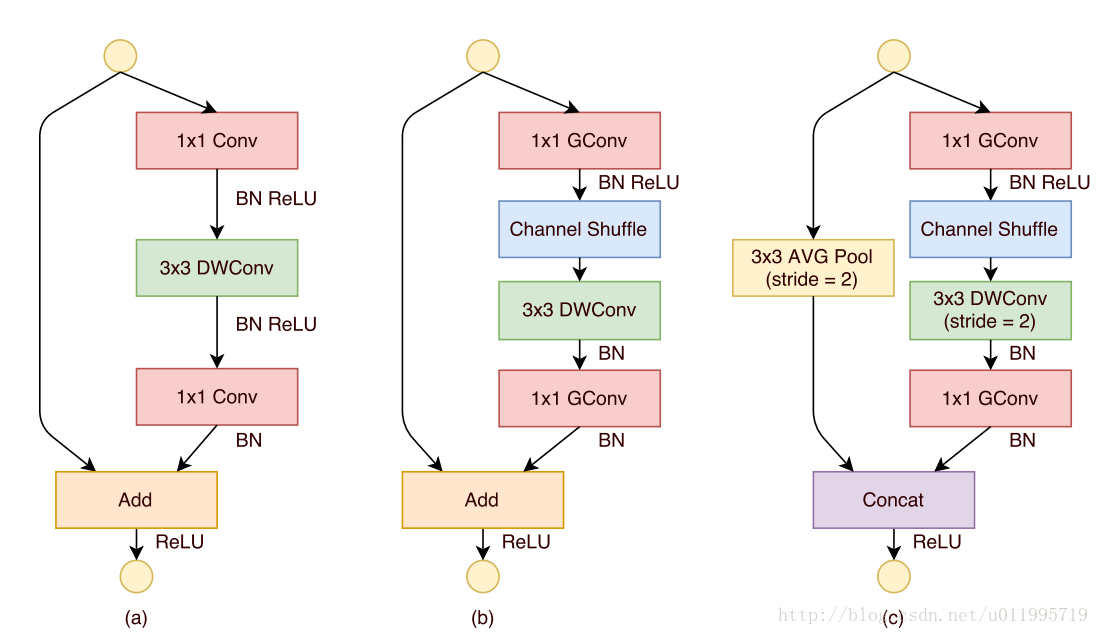
下圖展示了ShuffleNet unit的演化過程
圖(a):是一個帶有depthwise convolution的bottleneck unit;
圖(b):作者在(a)的基礎上進行變化,對1*1 conv 換成 1*1 Gconv,並在第一個1*1 Gconv之後增加一個channel shuffle 操作;
圖(c): 在旁路增加了AVG pool,目的是為了減小feature map的解析度;因為解析度小了,於是乎最後不採用Add,而是concat,從而“彌補”了解析度減小而帶來的資訊損失。
文中提到兩次,對於小型網路,多多使用通道,會比較好。
“this is critical for small networks, as tiny networks usually have an insufficient number of channels to process the information”
所以,以後若涉及小型網路,可考慮如何提升通道使用效率
至於實驗比較,並沒有給出模型引數量的大小比較,而是採用了Complexity (MFLOPs)指標,在相同的Complexity (MFLOPs)下,比較ShuffleNet和各個網路,還專門和MobileNet進行對比,由於ShuffleNet相較於MobileNet少了1*1 Conv(注意!少了1*1 Conv,也就是point-wise convolution),所以效率大大提高了嘛,貼個對比圖隨意感受一下好了
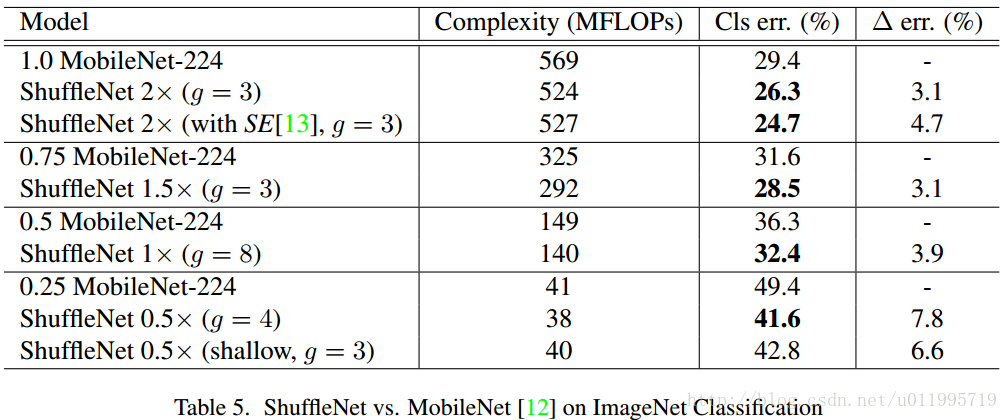
ShuffleNet小結:
1.與MobileNet一樣採用了depth-wise convolution,但是針對 depth-wise convolution帶來的副作用——“資訊流通不暢”,ShuffleNet採用了一個channel shuffle 操作來解決。
- 在網路拓撲方面,ShuffleNet採用的是resnet的思想,而mobielnet採用的是VGG的思想,2.1 SqueezeNet也是採用VGG的堆疊思想
2.4 Xception
Xception並不是真正意義上的輕量化模型,只是其借鑑depth-wise convolution,而depth-wise convolution又是上述幾個輕量化模型的關鍵點,所以在此一併介紹,其思想非常值得借鑑。
Xception是Google提出的,arXiv 的V1 於2016年10月公開。論文標題:
《Xception: Deep Learning with Depthwise Separable Convolutions 》
命名
Xception是基於Inception-V3的,而X表示Extreme,為什麼是Extreme呢?因為Xception做了一個加強的假設,這個假設就是:
we make the following hypothesis: that the mapping of cross-channels correlations and spatial correlations in the feature maps of convolutional neural networks can be entirely decoupled
創新點
1. 借鑑(非採用)depth-wise convolution 改進Inception V3
既然是改進了Inception v3,那就得提一提關於inception的一下假設(思想)了。
“the fundamental hypothesis behind Inception is that cross-channel correlations and spatial correlations are sufficiently decoupled that it is preferable not to map them jointly”
簡單理解就是說,卷積的時候要將通道的卷積與空間的卷積進行分離,這樣會比較好。(沒有理論證明,只有實驗證明,就當它是定理,接受就好了,現在大多數神經網路的論文都這樣。
———————————-分割線—————————————
既然是在Inception V3上進行改進的,那麼Xception是如何一步一步的從Inception V3演變而來。
下圖1 是Inception module,圖2是作者簡化了的 inception module(就是隻保留1*1的那條“路”,如果帶著avg pool,後面怎麼進一步假設嘛~~~)
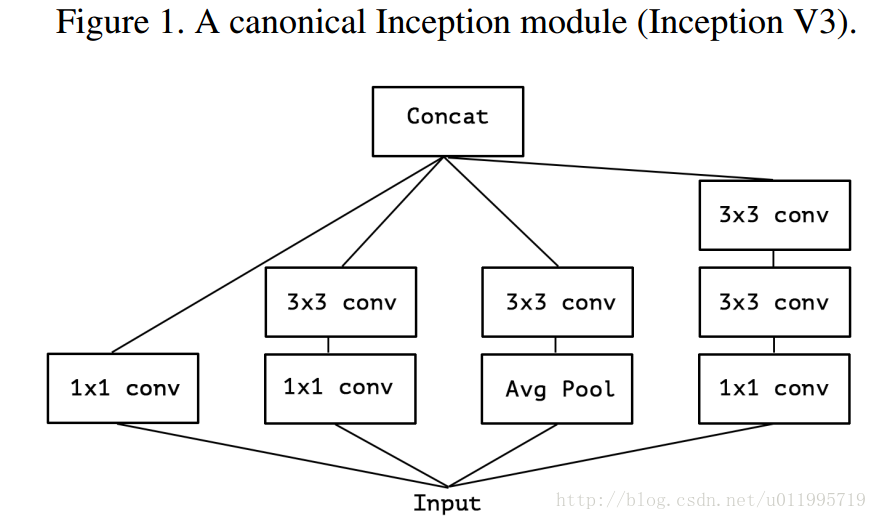
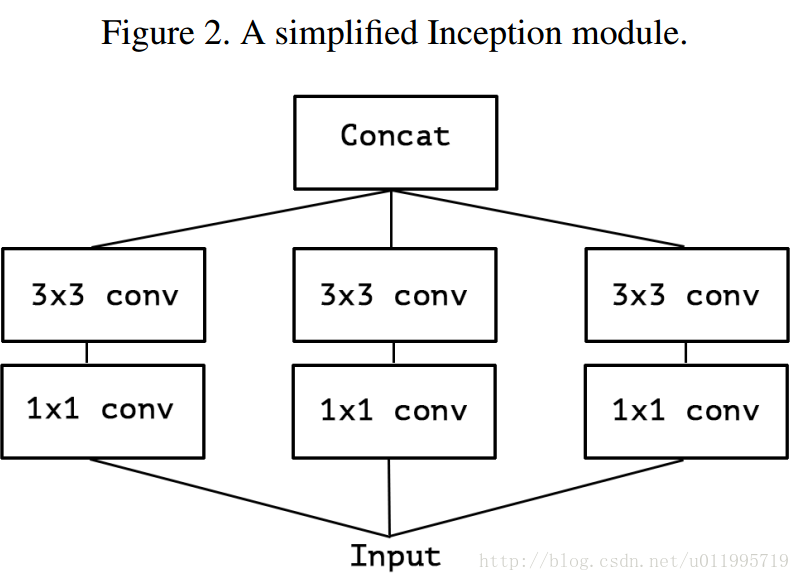
假設出一個簡化版inception module之後,再進一步假設,把第一部分的3個1*1卷積核統一起來,變成一個1*1的,後面的3個3*3的分別“負責”一部分通道,如圖3所示; 最後提出“extreme” version of an Inception ,module Xception登場,, 先用1*1卷積核對各通道之間(cross-channel)進行卷積,如圖4所示,
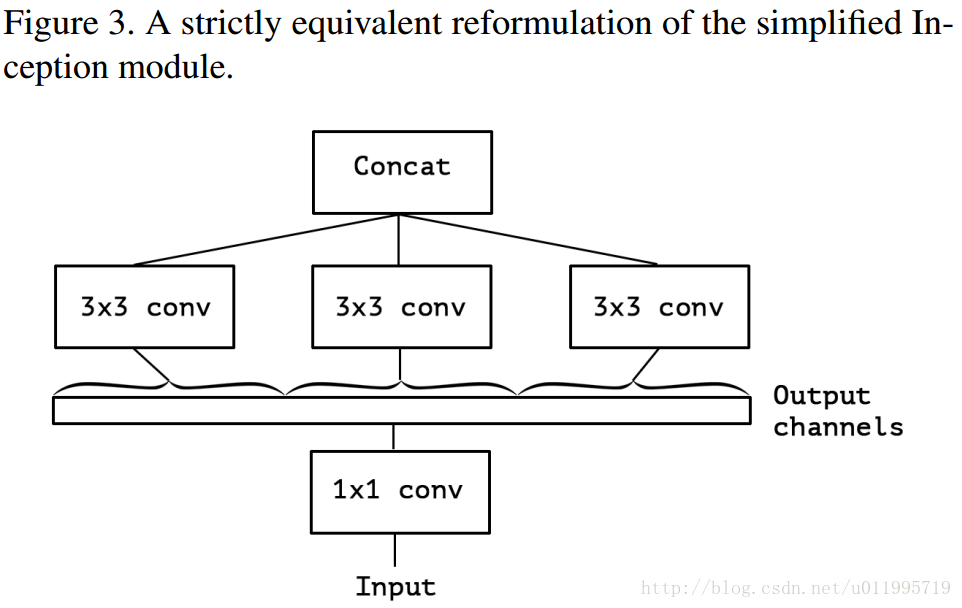
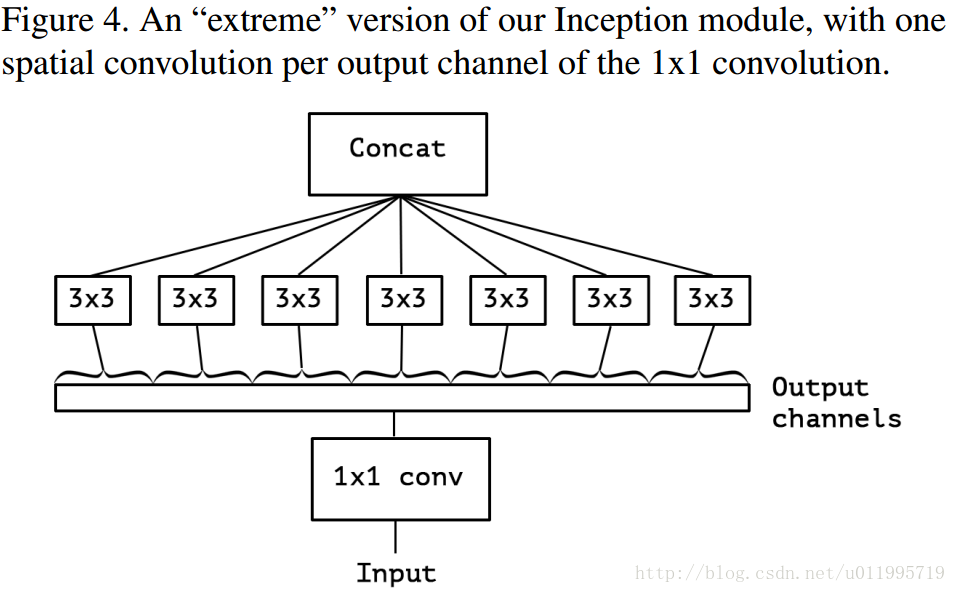
作者說了,這種卷積方式和depth-wise convolution 幾乎一樣。Depth-wise convolution 較早用於網路設計是來自:Rigid-Motion Scatteringfor Image Classification,但是具體是哪一年提出,不得而知;至少2012年就有相關研究,再比如說AlexNet,由於記憶體原因,AlexNet分成兩組卷積 ;想深入瞭解Depth-wise convolution的可以查閱本論文2.Prior work,裡面有詳細介紹。
Xception是借鑑Rigid-Motion Scatteringfor Image Classification 的Depth-wise convolution,是因為Xception與原版的Depth-wise convolution有兩個不同之處
第一個:原版Depth-wise convolution,先逐通道卷積,再1*1卷積; 而Xception是反過來,先1*1卷積,再逐通道卷積;
第二個:原版Depth-wise convolution的兩個卷積之間是不帶啟用函式的,而Xception在經過1*1卷積之後會帶上一個Relu的非線性啟用函式;
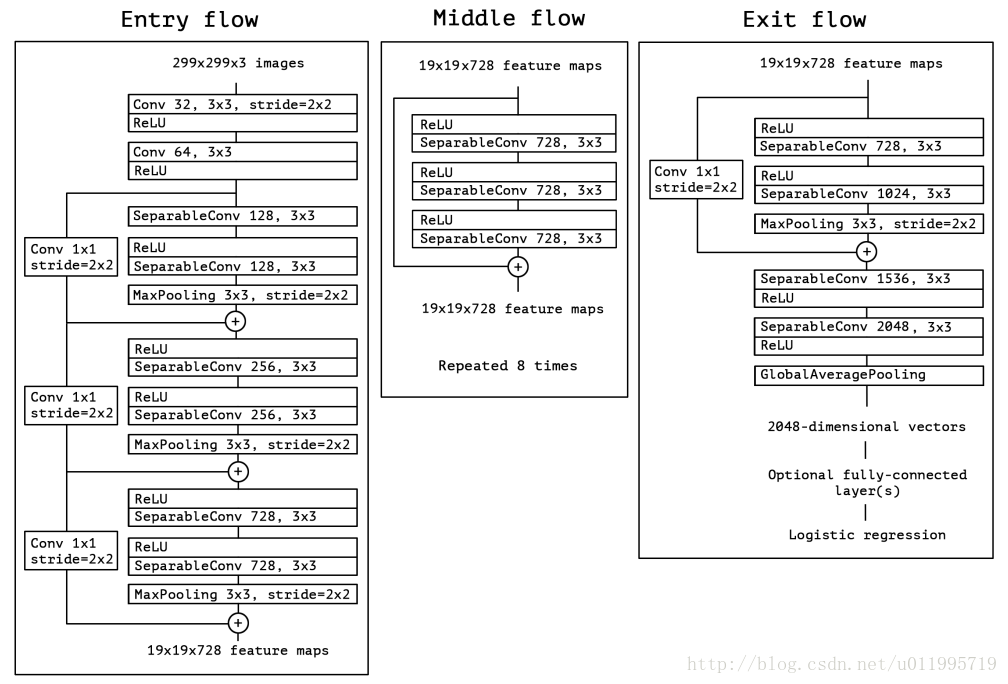
Xception 結構如上圖所示,共計36層分為Entry flow; Middle flow; Exit flow;
Entry flow 包含 8個conv;Middle flow 包含 3*8 =24個conv;Exit flow包含4個conv,所以Xception共計36層
文中Xception實驗部分是非常詳細的,實現細節可參見論文。

Xception小結:
Xception是基於Inception-V3,並結合了depth-wise convolution,這樣做的好處是提高網路效率,以及在同等引數量的情況下,在大規模資料集上,效果要優於Inception-V3。這也提供了另外一種“輕量化”的思路:在硬體資源給定的情況下,儘可能的增加網路效率和效能,也可以理解為充分利用硬體資源。
三 網路對比
本文簡單介紹了四個輕量化網路模型,分別是SqueezeNet、 MobileNet、 ShuffleNet和Xception,前三個是真正意義上的輕量化網路,而Xception是為提升網路效率,在同等引數數量條件下獲得更高的效能。
在此列出表格,對比四種網路是如何達到網路輕量化的。
| 網路 | 實現輕量化技巧 |
|---|---|
| SqueezeNet | 1*1卷積核“壓縮”feature map數量 |
| MobileNet | Depth-wise convolution |
| ShuffleNet | Depth-wise convolution |
| Xception | 修改的Depth-wise convolution |
這麼一看就發現,輕量化主要得益於depth-wise convolution,因此大家可以考慮採用depth-wise convolution 來設計自己的輕量化網路, 但是要注意“資訊流通不暢問題”
解決“資訊流通不暢”的問題,MobileNet採用了point-wise convolution,ShuffleNet採用的是channel shuffle。MobileNet相較於ShuffleNet使用了更多的卷積,計算量和引數量上是劣勢,但是增加了非線性層數,理論上特徵更抽象,更高階了;ShuffleNet則省去point-wise convolution,採用channel shuffle,簡單明瞭,省去卷積步驟,減少了引數量。
學習了幾個輕量化網路的設計思想,可以看到,並沒有突破性的進展,都是借鑑或直接使用前幾年的研究成果。希望廣大研究人員可以設計出更實在的輕量化網路。
最後講一下讀後感,也可以認為是發(Shui)論文的idea:
1.繼續採用depth-wise convolution,主要設計一個方法解決“資訊流通不暢”問題, 然後冠以美名XX-Net。(看看ShuffleNet就是)
2.針對depth-wise convolution作文章,卷積方式不是千奇百怪麼?各種卷積方式可參考Github(https://github.com/vdumoulin/conv_arithmetic),挑一個或者幾個,結合起來,只要引數量少,實驗效果好,就可以發(Shui)論文。
3.接著第2,如果設計出來一個新的卷積方式,如果也存在一些“副作用”,再想一個方法解決這個副作用,再美其名曰XX-Net。就是自己“挖”個坑,自己再填上去。
以上純屬讀後感,寫得比較“隨意”,如果有什麼地方描述有誤,請大家指出來,歡迎大家前來討論~