
詞法分析之Bi-LSTM-CRF框架
詞法分析是NLP的一項重要的基礎技術,包括分詞、詞性標註、實體識別等,其主要演算法結構為基於Bi-LSTM-CRF演算法體系,下面對Bi-LSTM-CRF演算法體系進行介紹。
引言
首先拋開深層的技術原因,來從巨集觀上看一下為什麼LSTM(Bi-LSTM)後接CRF效果會好。
首先引用一篇英文文獻關於這個問題的介紹:
For sequence labeling (or general structured prediction) tasks, it is beneficial to consider the corelations between labels in neighborhoods and jointly decode the best chain of labels for a given input sentence
. For example, in POS tagging an adjective is more likely to be followed by a noun than a verb, and in NER with standard BIO2 annotation I-ORG cannot follow I-PER. Therefore, we model label sequence jointly using a conditional random field (CRF), instead of decoding each label independently
總結起來就是,用CRF是為獲取全域性最優的輸出序列
另外,引用知乎使用者“穆文”的回答,從網路結構上來講,Bi-LSTM-CRF套用的還是CRF這個大框架,只不過把LSTM在每個
Bi-LSTM-CRF演算法體系架構圖
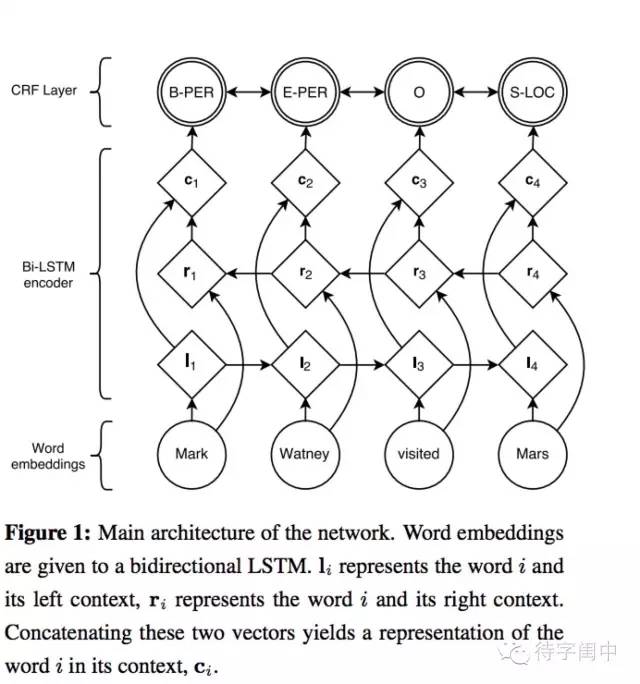
雙向LSTM(Bi-LSTM)
雙向LSTM的架構如下圖所示:
與傳統LSTM不同,雙向LSTM同時考慮了過去的特徵(通過前向過程提取)和未來的特徵(通過後向過程提取)
學習過程
Bi-LSTM layer的輸出維度是tag size,這就相當於是每個詞
對於輸入序列
對輸入序列
可以看出優化目標為
models for segmenting and labeling sequence
data.