97.5%準確率的深度學習中文分詞(字嵌入+Bi-LSTM+CRF)
摘要
深度學習當前在NLP領域發展也相當快,翻譯,問答,摘要等基本都被深度學習佔領了。 本文給出基於深度學習的中文分詞實現,藉助大規模語料,不需要構造額外手工特徵,在2014年人民日報語料上取得97.5%的準確率。模型基本是參考論文:http://www.aclweb.org/anthology/N16-1030
相關方法
中文分詞是個比較經典的問題,各大網際網路公司都會有自己的分詞實現。 考慮到效能,可維護性,詞庫更新,多粒度,以及其他的業務需求,一般工業界中文分詞方案都是基於規則。
1) 基於規則的常見的就是最大正/反向匹配,以及雙向匹配。
2) 規則裡糅合一定的統計規則,會採用動態規劃計算最大的概率路徑的分詞
以上說起來很簡單,其中還有很多細節,比如詞法規則的高效匹配編譯,詞庫的索引結構等。
3) 基於傳統機器學習的方法 ,以CRF為主,也有用svm,nn的實現,這類都是基於模型的,跟本文一樣,都有個缺陷,不方便增加使用者詞典(但可以結合,比如解碼的時候force-decode)。 速度上會有損耗。 另外都需要提取特徵。傳統CRF一般是定義特徵模板,方便性上有所提高。另外傳統CRF訓練演算法(LBFGS)較慢,也有使用sgd的,但多執行緒都支援的不好。代表有crf++, crfsuite, crfsgd, wapiti等。
深度學習方法
深度學習主要是特徵學習,端到端訓練, 適合有大量語料的場景。另外各種工具越來越完善,利用GPU可大幅提高訓練速度。
前文提過,深度學習主要是特徵學習,在NLP裡各種詞嵌入是一種有效的特徵學習。 本文實現的第一步也是對語料進行處理,使用word2vec對語料的字進行嵌入,每個字特徵為50維。
得到字嵌入後,用字嵌入特徵餵給雙向LSTM, 對輸出的隱層加一個線性層,然後加一個CRF就得到本文實現的模型。
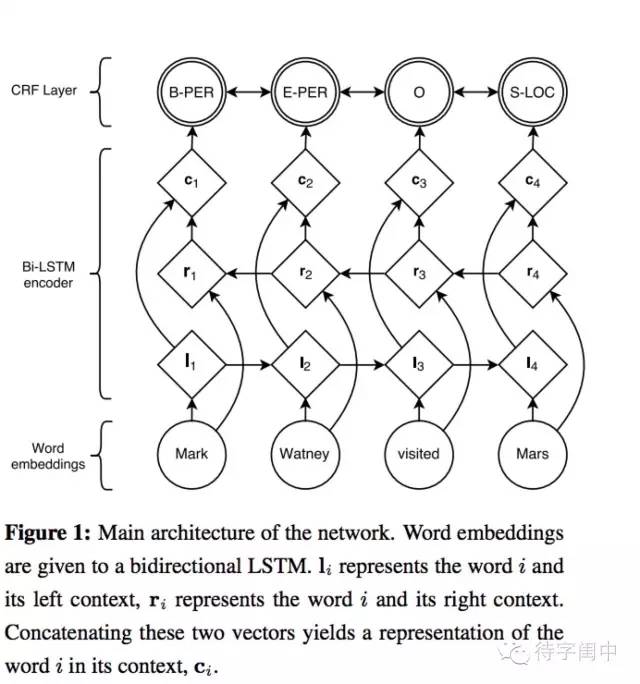
另外,字元嵌入的表示可以是純預訓練的,但也可以在訓練模型的時候再fine-tune,一般而言後者效果更好。
對於fine-tune的情形,可以在字元嵌入後,輸入雙向LSTM之前加入dropout進一步提升模型效果。
最後,對於最優化方法,文字語言模型類的貌似Adam效果更好, 對於分類之類的,貌似AdaDelta效果更好。
語料
本文使用2014人民日報語料,一共50w+ 句子,1千多萬的字元次數 (句子長度超過50的不考慮)
標註示例:
法新社/j 報道/v 說/v ,/w [泰國/nsf 政府/nis]/nt 已經/d 作/v 好/a 簽發/v 緊急狀態/n 令/v的/ude1 準備/vn 。/w (/w 老/a 任/v )/w
預處理
我們首先使用word2vec對字進行嵌入,具體就是把每一句按字元切割,空格隔開,餵給word2vec,指定維度50
然後我們把每一句處理成 :
字索引1 字索引2 … 字索引N 標註1 標註2 … 標註N
對於標註,我們按字分詞的典型套路,
- 對於單獨字元,不跟前後構成詞的,我們標註為S (0)
- 跟後面字元構成詞且自身是第一個字元的,我們標註為B (1)
- 在成詞的中間的字元,標註為M (2)
- 在詞尾的字元,標註為E (3)
這樣處理後使用前面描述模型訓練。
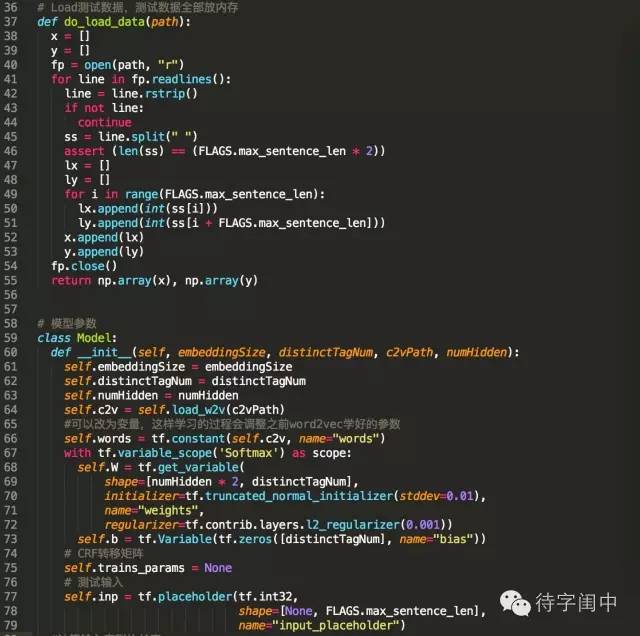
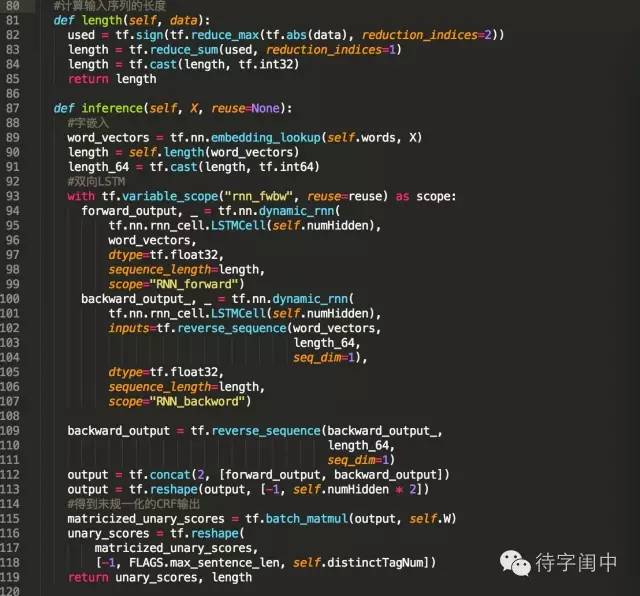
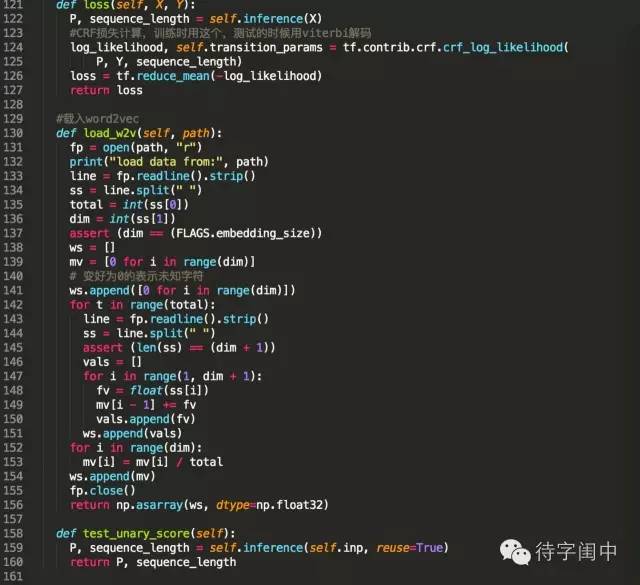
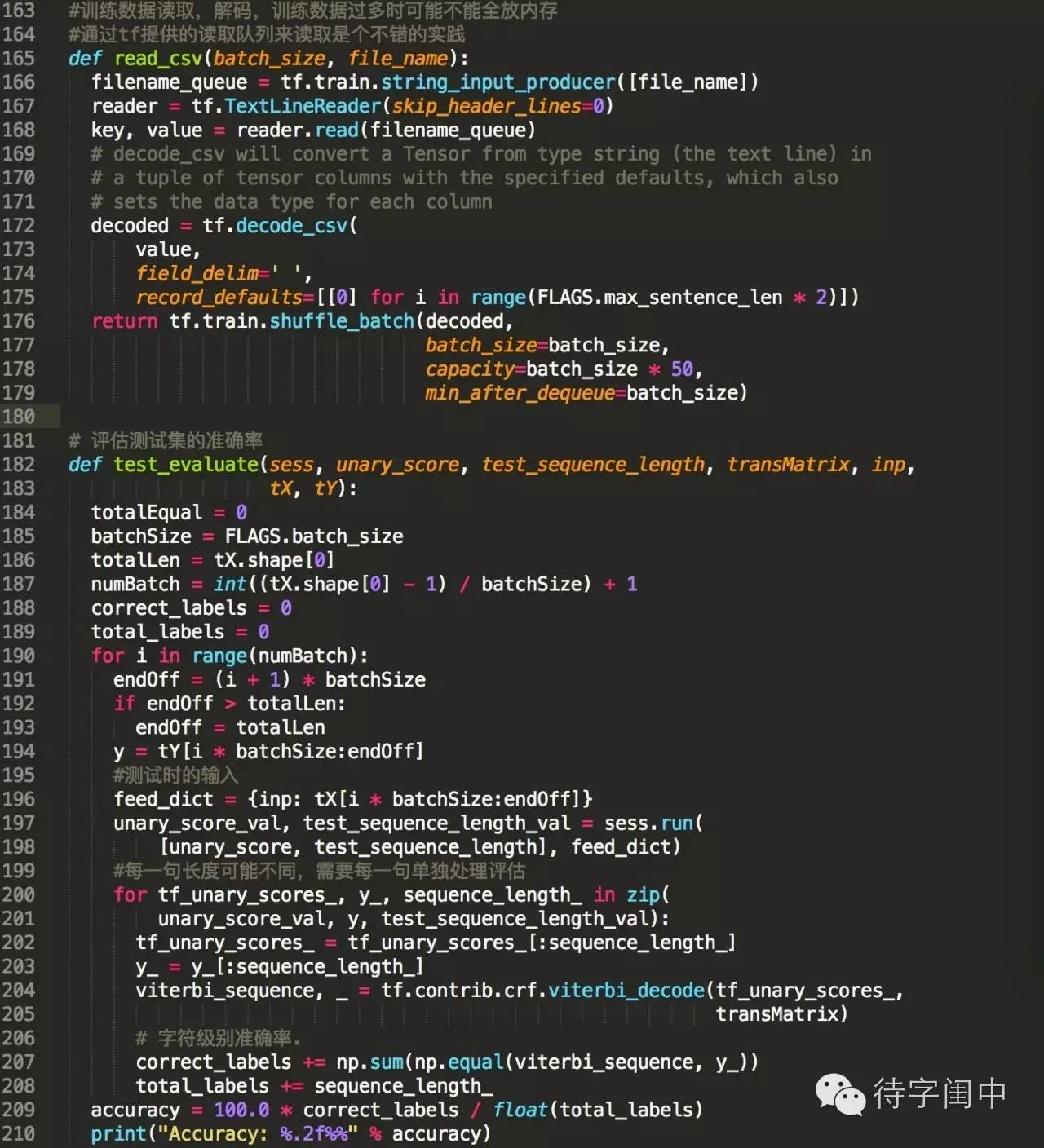
訓練程式碼