
yolo v2之車牌檢測後續識別字符(一)
一、前言
本篇續接前一篇 yolo v2 之車牌檢測 ,前一篇使用yolo v2已經可以很準確地框出車牌圖片了,這裡完成後續的車牌字元號碼的識別,從車牌框框中要識別出車牌字元,筆者能想到3種思路,1種是同樣yolo、SSD等深度學習目標檢測的方法直接對車牌內的字元識別;第2種是傳統方法從框裡切分字元,再訓練深度學習的模型對各個字元做識別;第3種方法就是端到端的車牌圖片識別。在車牌影象的解析度比較高,而且清晰的情況下,第1種方法的成功率理論上會比較高的,而且能夠針對多種車牌,第2種方法則車牌字元傾斜的情況下效果不好,故這裡嘗試第3種方法,這種做法實際上也與驗證碼識別類似,缺點就是隻能識別固定位數的車牌圖片,用基於迴圈神經網路的方法可能可以解決這個問題。
二、修改caffe原始碼使適合多標籤分類
三、訓練集和驗證集製作
首先需要採集資料,端到端的識別需要用到大量樣本,上一篇中,修改yolo v2的原始碼src/detector.c中的draw_detections函式,將訓練集和測試集的所檢測的僅包含車牌的圖片儲存下來。為了能夠得到更多的樣本,爬蟲更多網上的圖片來檢測,我這裡共儲存了3922張僅含車牌圖片
其次上述採集到的圖片遠遠不夠,發現使用者 szad670401在 Github 上開源的一個車牌生成器,當然也提供了相應的端到端識別模型。但是還是感覺生成的圖片和真實的圖片有所差距,故借鑑其程式碼中的新增高斯噪聲、旋轉、仿射變換、調整HSV、新增背景影象等操作對3922張圖片做樣本增強,先將圖片resize至272*72,這個解析度大小是為了之後符合模型的輸入,再做樣本增強,以下為一張圖片的變換示例:



附上資料增強的python程式碼
#!/usr/bin/env python #coding=utf-8 import os import cv2 import numpy as np from math import * import random index = {"京": 0, "滬": 1, "津": 2, "渝": 3, "冀": 4, "晉": 5, "蒙": 6, "遼": 7, "吉": 8, "黑": 9, "蘇": 10, "浙": 11, "皖": 12, "閩": 13, "贛": 14, "魯": 15, "豫": 16, "鄂": 17, "湘": 18, "粵": 19, "桂": 20, "瓊": 21, "川": 22, "貴": 23, "雲": 24, "藏": 25, "陝": 26, "甘": 27, "青": 28, "寧": 29, "新": 30, "0": 31, "1": 32, "2": 33, "3": 34, "4": 35, "5": 36, "6": 37, "7": 38, "8": 39, "9": 40, "A": 41, "B": 42, "C": 43, "D": 44, "E": 45, "F": 46, "G": 47, "H": 48, "J": 49, "K": 50, "L": 51, "M": 52, "N": 53, "P": 54, "Q": 55, "R": 56, "S": 57, "T": 58, "U": 59, "V": 60, "W": 61, "X": 62, "Y": 63, "Z": 64}; def GetFileList(dir, fileList): if os.path.isfile(dir): fileList.append(dir) elif os.path.isdir(dir): for s in os.listdir(dir): #如果需要忽略某些資料夾,使用以下程式碼 #if s == "xxx": #continue newDir=os.path.join(dir,s) GetFileList(newDir, fileList) return fileList # create random value between 0 and val-1 def r(val): return int(np.random.random() * val) def AddGauss(img, level): return cv2.blur(img, (level * 2 + 1, level * 2 + 1)); def rot(img,angel,shape,max_angel): """ 使影象輕微的畸變 img 輸入影象 factor 畸變的引數 size 為圖片的目標尺寸 """ size_o = [shape[1],shape[0]] size = (shape[1]+ int(shape[0]*cos((float(max_angel )/180) * 3.14)),shape[0]) interval = abs( int( sin((float(angel) /180) * 3.14)* shape[0])); pts1 = np.float32([[0,0] ,[0,size_o[1]],[size_o[0],0],[size_o[0],size_o[1]]]) if(angel>0): pts2 = np.float32([[interval,0],[0,size[1] ],[size[0],0 ],[size[0]-interval,size_o[1]]]) else: pts2 = np.float32([[0,0],[interval,size[1] ],[size[0]-interval,0 ],[size[0],size_o[1]]]) M = cv2.getPerspectiveTransform(pts1,pts2); dst = cv2.warpPerspective(img,M,size); return dst; def rotRandrom(img, factor, size): shape = size; pts1 = np.float32([[0, 0], [0, shape[0]], [shape[1], 0], [shape[1], shape[0]]]) pts2 = np.float32([[r(factor), r(factor)], [ r(factor), shape[0] - r(factor)], [shape[1] - r(factor), r(factor)], [shape[1] - r(factor), shape[0] - r(factor)]]) M = cv2.getPerspectiveTransform(pts1, pts2); dst = cv2.warpPerspective(img, M, size); return dst; def cropFill(img , bot): leftIdx = 0 rightIdx = 0 for col in range(img.shape[1]): if sum( sum( img[0: , col ] ) ) !=0: leftIdx = col break for col in range( img.shape[1] ): if sum( sum( img[0: ,img.shape[1]-col-1 ] ) ) !=0: rightIdx = img.shape[1] - col break imgRoi = img[0: , leftIdx: rightIdx] envPath = './env/'+str(r(28))+'.png' #env資料夾下儲存了28張背景圖片,從0.png到27.png env = cv2.imread(envPath) env = cv2.resize( env , ( imgRoi.shape[1] , imgRoi.shape[0])) img2gray = cv2.cvtColor(imgRoi, cv2.COLOR_BGR2GRAY) ret,mask = cv2.threshold(img2gray,10,255,cv2.THRESH_BINARY) mask_inv = cv2.bitwise_not(mask) bak = (imgRoi==0); bak = bak.astype(np.uint8)*255; inv = cv2.bitwise_and(bak,env) img_temp = cv2.bitwise_or(inv,imgRoi, mask = mask_inv) imgRoi = cv2.bitwise_or(imgRoi , img_temp) return imgRoi def tfactor(img): hsv = cv2.cvtColor(img,cv2.COLOR_BGR2HSV); hsv[:,:,1] = hsv[:,:,1]*(0.7+ np.random.random()*0.3); hsv[:,:,1] = hsv[:,:,1]*(0.4+ np.random.random()*0.6); hsv[:,:,2] = hsv[:,:,2]*(0.4+ np.random.random()*0.6); img = cv2.cvtColor(hsv,cv2.COLOR_HSV2BGR); return img if __name__ == '__main__': lists = GetFileList( './licence_img' ,[]) for imgPath in lists: #遍歷所有圖片 img = cv2.imread(imgPath) img = cv2.resize(img , (272,72) ) cv2.imshow('src', img) cv2.waitKey(0) for times in range(20): #20次變換可得到20張增強的圖片 src = img dst = AddGauss( src, r(3 ) ) dst = rot(dst,r(60)-30,dst.shape,20); dst = rotRandrom(dst,5,(dst.shape[1],dst.shape[0])); dst = cropFill( dst, 3 ) dst = tfactor( dst ) cv2.imshow('dst' , dst) cv2.waitKey(0)
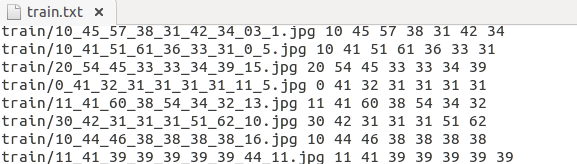
在caffe下新建資料夾 LPR,在當中新建資料夾train和val,用於儲存訓練集和驗證集圖片,3922張圖片每張圖片均做20次上述影象處理,共80000多張圖片,將71547張圖片保存於train,10815張保存於val,每張圖片的名字已經被修改為諸如0_41_31_31_31_31_31_6_4.jpg的名字,前7位數字即為該車牌號的對應label,在LPR下新建python檔案genText.py,輸入以下內容
#!/usr/bin/env python
#-*- coding:utf-8 -*-
import os,sys
trainFile = 'train/'
valFile = 'val/'
if __name__ == '__main__':
tf = open('train.txt' , 'w')
vf = open('val.txt' , 'w' )
for filename in os.listdir( trainFile ):
lists = filename.split('_')
imgPath = trainFile +filename
tf.write(imgPath)
for k in range(7):
tf.write(' '+lists[k])
tf.write('\n')
tf.close()
for filename in os.listdir( valFile ):
lists = filename.split('_')
imgPath = valFile +filename
vf.write(imgPath)
for k in range(7):
vf.write(' '+lists[k])
vf.write('\n')
vf.close()
四、生成lmdb
這裡生成lmdb,還是用到了create_imagenet.sh,其內部還是呼叫了convert_imageset,將 examples/imagenet/create_imagenet.sh 複製一份到LPR資料夾下,修改如下:
#!/usr/bin/env sh
# Create the imagenet lmdb inputs
# N.B. set the path to the imagenet train + val data dirs
set -e
EXAMPLE=LPR/Build_lmdb #Build_lmdb儲存生成的lmdb檔案,需要先建立好
DATA=LPR/ #train.txt和val.txt所在位置
TOOLS=build/tools #caffe自帶工具,不用管
LABEL_NUM='7' #label標籤數量
TRAIN_DATA_ROOT=/home/jyang/caffe/LPR/ #訓練圖片所在路徑,和標籤檔案的路徑拼起來為完整路徑
VAL_DATA_ROOT=/home/jyang/caffe/LPR/ #測試圖片所在路徑,同上
# Set RESIZE=true to resize the images to 256x256. Leave as false if images have
# already been resized using another tool.
RESIZE=false #已經做過resize了,所以這裡不做了
if $RESIZE; then
RESIZE_HEIGHT=256
RESIZE_WIDTH=256
else
RESIZE_HEIGHT=0
RESIZE_WIDTH=0
fi
if [ ! -d "$TRAIN_DATA_ROOT" ]; then
echo "Error: TRAIN_DATA_ROOT is not a path to a directory: $TRAIN_DATA_ROOT"
echo "Set the TRAIN_DATA_ROOT variable in create_imagenet.sh to the path" \
"where the ImageNet training data is stored."
exit 1
fi
if [ ! -d "$VAL_DATA_ROOT" ]; then
echo "Error: VAL_DATA_ROOT is not a path to a directory: $VAL_DATA_ROOT"
echo "Set the VAL_DATA_ROOT variable in create_imagenet.sh to the path" \
"where the ImageNet validation data is stored."
exit 1
fi
echo "Creating train lmdb..."
GLOG_logtostderr=1 $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$TRAIN_DATA_ROOT \
$DATA/train.txt \
$EXAMPLE/train_lmdb #lmdb格式訓練集儲存的路徑
echo "Creating val lmdb..."
GLOG_logtostderr=1 $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$VAL_DATA_ROOT \
$DATA/val.txt \
$EXAMPLE/val_lmdb #lmdb格式驗證集儲存的路徑
echo "Done."
五、生成均值檔案
caffe路徑下執行build/tools/compute_image_mean LPR/Build_lmdb/train_lmdb LPR/Mean/mean.binaryproto,在新建的Mean資料夾下儲存均值檔案
結語
這樣已經得到lmdb格式的資料集和均值檔案,以下提供3922張僅含車牌的圖片下載,配置檔案、模型檔案生成及模型訓練、測試參看下一篇。
連結