
R語言--關聯分析(問卷調查)
在R中用最經典的Apriori關聯演算法對問卷調查結果進行簡單的關聯分析,包括對規則的篩選,輸出以及視覺化。
主流程
主流程包括4個部分,資料介紹,關聯分析主流程程式碼,主流程子程式碼,視覺化。
資料介紹
資料包含360份問卷對14個問題的答案,類似下表:
| 問卷編號 | Q1 | Q2 | Q3 | Q4 | ··· |
|---|---|---|---|---|---|
| 1 | 大三 | 一線城市 | 安全 | 收費情況 | ··· |
| 2 | 大三 | 一線城市 | 相對安全 | 安全係數 | ··· |
| 3 | 大三 | 一線城市 | 安全 | 使用方便 | ··· |
關聯分析主流程
##讀取資料,轉換成transaction格式 主流程中的子函式
上述的主流程裡包含3個子函式:
- 資料處理:as.transaction;
- Rhs的提取函式:Rhs_Selecet;
- 將規則轉換成資料框格式輸出:inspect.frame。
##資料轉換,先轉換成List格式,再轉換成transaction格式。
as.transaction <- function(data, f){
dataList <- split(data, f)
dataList <- lapply(dataList, function(x){
rst <- unlist(x)
names(rst) <- NULL
rst <- unique(rst)
rst <- rst[-which(rst=="")]
rst
})
transaction <- as(dataList, "transactions")
transaction
}
##右提取規則
Rhs_Selecet <- function(rules.pruned, char){
rhs <- [email protected]@itemInfo[([email protected]@[email protected])+1,]
loc <- which(rhs == char)
rules.pruned[loc]
}
##轉換成data.frame格式,先提取Lhs,並連線成一個字串
##再提取Rhs,quality,組成一個數據框
inspect.frame <- function(rules.pruned, itemSep = ","){
##Lhs處理
#提取Lhs長度
lhsNum <- diff([email protected]@[email protected])
#產生標籤
lhsRuleItemsLOC <- NULL
for(i in 1:length(lhsNum)){
lhsRuleItemsLOC <- c(lhsRuleItemsLOC, rep(i, lhsNum[i]))
}
#提取Rhs,組合成字串, 連結符號預設“,”
lhsRuleItems <- [email protected]@itemInfo[[email protected]@[email protected]+1,]
lhsRuleItemsList <- split(lhsRuleItems, lhsRuleItemsLOC)
lhs <- sapply(lhsRuleItemsList, function(x){
lhs <- x[1]
if(length(x)>1){
for(i in 2:length(x)){
lhs <- paste(lhs, x[i], sep=itemSep)
}
}
lhs
})
##lhs處理
rhs <- [email protected]@itemInfo[([email protected]@[email protected])+1,]
##整理結果成資料框
csq <- data.frame(lhs, rhs, [email protected])
csq
}視覺化
全部規則的視覺化,以及預分析Rhs項的視覺化
###全部規則,氣泡圖,大小表示support,顏色表示Lift
library(arulesViz)
plot(rules.pruned, method = "grouped")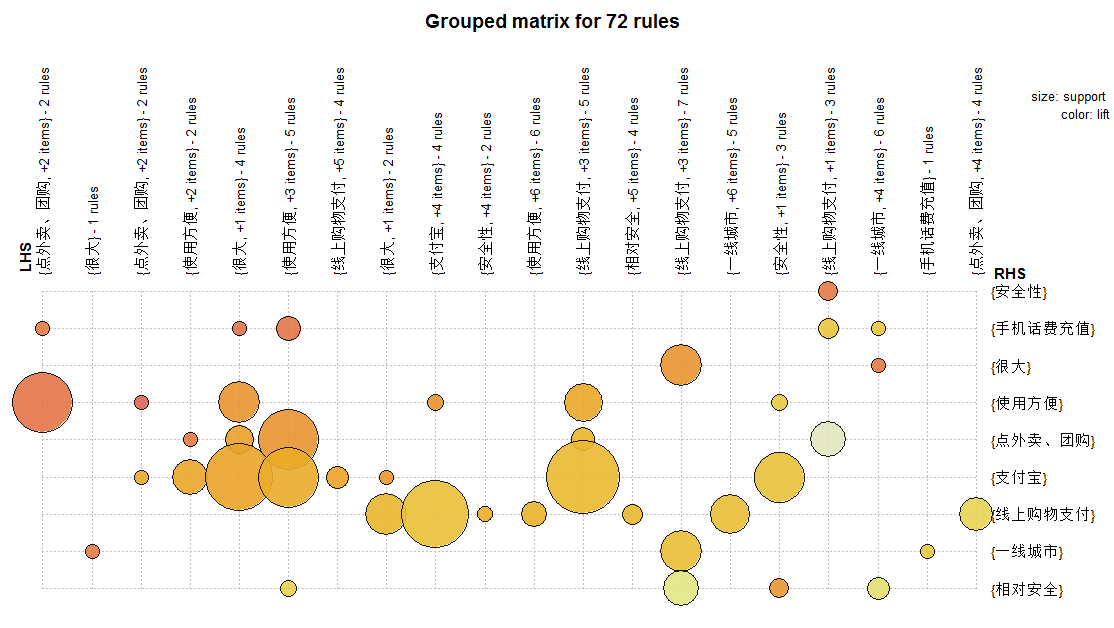
###部分規則,項集有向圖,大小表示support,顏色表示Lift
plot(rstRule, method = "graph",control =
list(edgeCol="black", main="rhs=`相對安全`")) 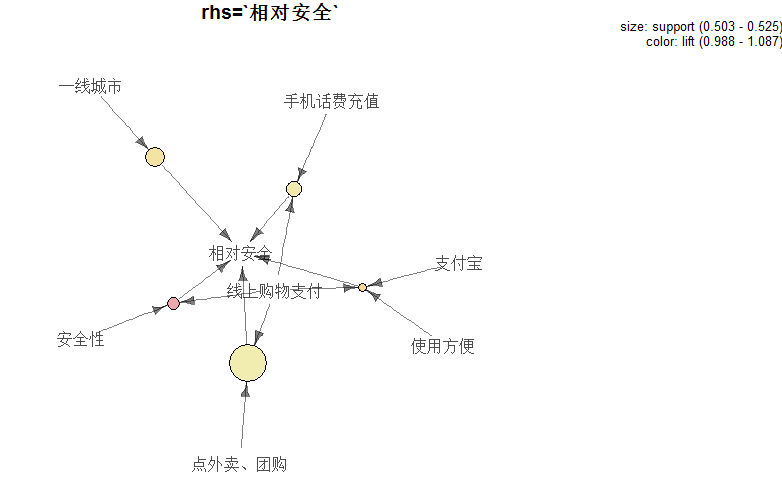
相關推薦
R語言--關聯分析(問卷調查)
在R中用最經典的Apriori關聯演算法對問卷調查結果進行簡單的關聯分析,包括對規則的篩選,輸出以及視覺化。 主流程 主流程包括4個部分,資料介紹,關聯分析主流程程式碼,主流程子程式碼,視覺化。 資料介紹 資料包含360份問卷對14個問題的答案,
R語言bootstrap分析(boot)
//## bootstrap分析資料,package = "boot" > library(boot) > city u x 1 138 143 2 93 104 3 61 69 4 179 260 5 48 75 6 37 63 7
資料分析--用R語言預測離職(下)
資料分析–用R語言預測離職(下) 接上一篇~ 接下來我們探索離職和其他分類變數的關係~ > library(scales) > k1 <- ggplot(attr.df, aes(x=Gender,fill=Attrition))+
資料分析--用R語言預測離職(上)
資料分析–用R語言預測離職(上) 資料可以直接下載,欄位都是英文的,部分欄位描述如下: 變數型別 變數名 描述 取值範圍 結果變數 Attrition 員工是否流失 Yes, No 自變數 Ag
商務數據分析報告--R語言--學習筆記(1)-- ggplot2畫圖
商務 分享 數據分析 開始 lib r語言 都市 生存 pla 如今是只大三狗,做事3分鐘熱度。可以讀書的時間就僅剩下不到4個月的時間。不想落到無書可讀可的地步,還沒有一門生存下去的手段。故開始記錄學習筆記,希望能在都市存活,繁衍。 語言可視化是讓人理解的一個重要手段,也
使用Apriori進行關聯分析(一)
不一定 再計算 add 在一起 num create images loaddata scan 大型超市有海量交易數據,我們可以通過聚類算法尋找購買相似物品的人群,從而為特定人群提供更具個性化的服務。但是對於超市來講,更有價值的是如何找出商品的隱藏關聯,從而打包促銷,以
使用Apriori進行關聯分析(二)
lis 過程 pre alt lock 不一定 根據 返回 req 書接上文(使用Apriori進行關聯分析(一)),介紹如何挖掘關聯規則。 發現關聯規則 我們的目標是通過頻繁項集挖掘到隱藏的關聯規則,換句話說就是關聯規則。 所謂關聯規則,指通過某個元素集推導出
R語言學習筆記(十三):時間序列
abs 以及 stat max 時間 aic air ror imp #生成時間序列對象 sales<-c(18,33,41,7,34,35,24,25,24,21,25,20,22,31,40,29,25,21,22,54,31,25,26,35) tsal
R語言關聯分析之啤酒和尿布
mea mar 簡單 active 兩個 mark 情況 rgb efault 關聯分析概述啤酒和尿布的故事,我估計大家都聽過,這是數據挖掘裏面最經典的案例之一。它分析的方法就關聯分析。關聯分析,顧名思義,就是研究不同商品之前的關系。這裏就發現了啤酒和尿布這兩個看起來毫不相
斯坦福大學-自然語言處理入門 筆記 第十三課 統計語言句法分析(prasing)
課程來源:Introduction to NLP by Chris Manning & Dan jurafsky 關於專用名詞和概念:剛接觸NLP領域,所以有些專有名詞的翻譯和專有概念可能會存在一定的偏誤,隨著學習的深入,我會隨時更新改正。 一、關於句法結構的兩種看法
R語言-線圖(二)
1.線圖示例 plot()為高水平作圖命令,axis()、lines()、legend()都為低水平作圖命令 > rain<-read.csv("cityrain.csv") > plot(rain$Tokyo,type="b",lwd=2,
R語言初學指南(筆記)
R語言的下載地址(Windows版本):http://ftp.ctex.org/mirrors/CRAN/ R語言的安裝,需要額外安裝mikTex,Rtools,htmlhelp: R:D:\Program Files\R\R-3.0.3 mikTex:D:\Program Files\Mi
R語言——學習筆記(一)
1.“>”符號後輸入指令。 2.1:100 指輸入1—100連續數值 3.sum() 函式,計算總和 4.sample() 函式,隨機取出 例1:>sample(1:6,1) 從1—6的整數中取出1個 例2:&g
R語言——學習筆記(二)
1.用R語言匯入Excel檔案中“xlsx”和“xls”格式的資料。 (1)安裝“readxl”包: >install.packages("readxl") (2)將Excel資料匯入R中,檔案位於“C:\Users\Celin\Desktop”路徑的
R語言——學習筆記(三)
1.table() 函式,生成表 2.管道處理 %>% 管道運算子 >install.packages("dplyr") >library(dplyr) >dat %>% table #用左
全基因組關聯分析(GWAS)掃不出訊號怎麼辦(文獻解讀)
假如你的GWAS結果出現如下圖的時候,怎麼辦呢?GWAS沒有如預期般的掃出完美的顯著訊號,也就沒法繼續發揮後續研究的套路了。 最近,nature發表了一篇文獻“Common genetic variants contribute to risk of rare severe neurodevelopme
R語言學習筆記(三)資料處理
本文的示例資料框集(egData)如下: 值標籤: if(FALSE){值標籤,levels代表變數實際值,labels代表標籤值} egData$sex <- factor(egDa
R語言入門——筆記(三)建立資料集
第一部分:資料結構 1.建立向量:c() c(…, recursive = FALSE, use.names = TRUE) 根據元素座標訪問 2.建立矩陣:matrix() matrix(data = NA, nrow = 1, ncol
R語言--資料介面(五)
1. CSV檔案 獲取和設定工作目錄 # 獲取和設定工作目錄 print(getwd()) # 設定當前工作目錄 setwd("E:/R") print(getwd()) 列印結果:
資料探勘——基於R文字情感分析(2)
姑且算是搞定了這個。 最後使用的是在twitter中搜索。因為callback url的關係,之前一直無法直接搜尋twitter內容,今天直接把callback url刪除了就成功了。 推薦兩個很好的