
關於詞向量工作原理的理解
在知乎網站上看到一個關於詞向量的問題:詞向量( Distributed Representation)工作原理是什麼,哪位大咖能否舉個通俗的例子說明一下? 恰好最近在學習 word2vec, 嘗試著根據對所讀文獻的理解寫了個回答,供大家參考。
要將自然語言交給機器學習演算法來處理,通常需要首先將語言數學化,詞向量就是用來將語言中的詞進行數學化的一種方式。
一種最簡單的詞向量方式是 one-hot representation,就是用一個很長的向量來表示一個詞,向量的長度為詞典的大小,向量的分量只有一個 1,其他全為 0, 1 的位置對應該詞在詞典中的位置。但這種詞向量表示有兩個缺點:(1)容易受維數災難的困擾,尤其是將其用於 Deep Learning 的一些演算法時;(2)不能很好地刻畫詞與詞之間的相似性(術語好像叫做“詞彙鴻溝”)。
另一種就是你提到的 Distributed Representation 這種表示,它最早是 Hinton 於 1986 年提出的,可以克服 one-hot representation 的上述缺點。其基本想法是:通過訓練將某種語言中的每一個詞對映成一個固定長度的短向量(當然這裡的“短”是相對於 one-hot representation 的“長”而言的),將所有這些向量放在一起形成一個詞向量空間,而每一向量則可視為該空間中的一個點,在這個空間上引入“距離”,則可以根據詞之間的距離來判斷它們之間的(詞法、語義上的)相似性了。
為更好地理解上述思想,我們來舉一個通俗的例子:假設在二維平面上分佈有 N 個不同的點,給定其中的某個點,現在想在平面上找到與這個點最相近的一個點,我們是怎麼做的呢?首先,建立一個直角座標系,基於該座標系,其上的每個點就唯一地對應一個座標 (x,y);接著引入歐氏距離;最後分別計算這個詞與其他 N-1 個詞之間的距離,對應最小距離值的那個詞便是我們要找的詞了。
上面的例子中,座標(x,y) 的地位就相當於詞向量,它用來將平面上一個點的位置在數學上作量化。座標系建立好以後,要得到某個點的座標是很容易的。然而,在 NLP 任務中,要得到詞向量就複雜得多了,而且詞向量並不唯一,其質量依賴於訓練語料、訓練演算法和詞向量長度等因素。
一種生成詞向量的途徑是利用神經網路演算法,當然,詞向量通常和語言模型捆綁在一起,即訓練完後兩者同時得到。用神經網路來訓練語言模型的思想最早由百度 IDL(深度學習研究院)的徐偉提出。這方面最經典的文章要數 Bengio 於 2003 年發表在 JMLR 上的
最近了解到詞向量在機器翻譯領域的一個應用,報道是這樣的:
谷歌的 Tomas Mikolov 團隊開發了一種詞典和術語表的自動生成技術,能夠把一種語言轉變成另一種語言。該技術利用資料探勘來構建兩種語言的結構模型,然後加以對比。每種語言詞語之間的關係集合即“語言空間”,可以被表徵為數學意義上的向量集合。在向量空間內,不同的語言享有許多共性,只要實現一個向量空間向另一個向量空間的對映和轉換,語言翻譯即可實現。該技術效果非常不錯,對英語和西語間的翻譯準確率高達
90%。
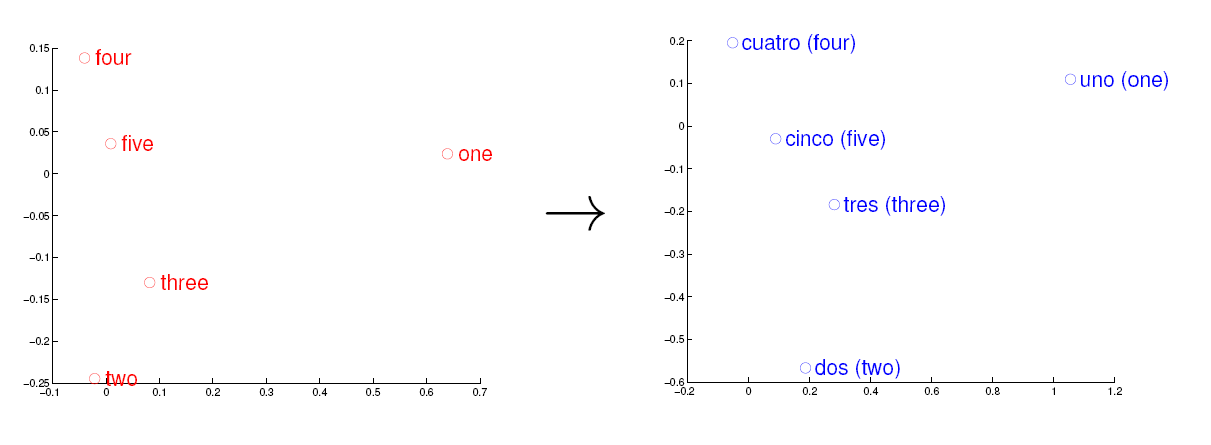
考慮英語和西班牙語兩種語言,通過訓練分別得到它們對應的詞向量空間 E 和 S。從英語中取出五個詞 one,two,three,four,five,設其在 E 中對應的詞向量分別為 v1,v2,v3,v4,v5,為方便作圖,利用主成分分析(PCA)降維,得到相應的二維向量 u1,u2,u3,u4,u5,在二維平面上將這五個點描出來,如下圖左圖所示。類似地,在西班牙語中取出(與 one,two,three,four,five 對應的) uno,dos,tres,cuatro,cinco,設其在 S
中對應的詞向量分別為 s1,s2,s3,s4,s5,用 PCA 降維後的二維向量分別為 t1,t2,t3,t4,t5,將它們在二維平面上描出來(可能還需作適當的旋轉),如下圖右圖所示:
觀察左、右兩幅圖,容易發現:五個詞在兩個向量空間中的相對位置差不多,這說明兩種不同語言對應向量空間的結構之間具有相似性,從而進一步說明了在詞向量空間中利用距離刻畫詞之間相似性的合理性。
作者: peghoty
歡迎轉載/分享, 但請務必宣告文章出處.