
小白學 Python 爬蟲(34):爬蟲框架 Scrapy 入門基礎(二)

人生苦短,我用 Python
前文傳送門:
小白學 Python 爬蟲(1):開篇
小白學 Python 爬蟲(2):前置準備(一)基本類庫的安裝
小白學 Python 爬蟲(3):前置準備(二)Linux基礎入門
小白學 Python 爬蟲(4):前置準備(三)Docker基礎入門
小白學 Python 爬蟲(5):前置準備(四)資料庫基礎
小白學 Python 爬蟲(6):前置準備(五)爬蟲框架的安裝
小白學 Python 爬蟲(7):HTTP 基礎
小白學 Python 爬蟲(8):網頁基礎
小白學 Python 爬蟲(9):爬蟲基礎
小白學 Python 爬蟲(10):Session 和 Cookies
小白學 Python 爬蟲(11):urllib 基礎使用(一)
小白學 Python 爬蟲(12):urllib 基礎使用(二)
小白學 Python 爬蟲(13):urllib 基礎使用(三)
小白學 Python 爬蟲(14):urllib 基礎使用(四)
小白學 Python 爬蟲(15):urllib 基礎使用(五)
小白學 Python 爬蟲(16):urllib 實戰之爬取妹子圖
小白學 Python 爬蟲(17):Requests 基礎使用
小白學 Python 爬蟲(18):Requests 進階操作
小白學 Python 爬蟲(19):Xpath 基操
小白學 Python 爬蟲(20):Xpath 進階
小白學 Python 爬蟲(21):解析庫 Beautiful Soup(上)
小白學 Python 爬蟲(22):解析庫 Beautiful Soup(下)
小白學 Python 爬蟲(23):解析庫 pyquery 入門
小白學 Python 爬蟲(24):2019 豆瓣電影排行
小白學 Python 爬蟲(25):爬取股票資訊
小白學 Python 爬蟲(26):為啥買不起上海二手房你都買不起
小白學 Python 爬蟲(27):自動化測試框架 Selenium 從入門到放棄(上)
小白學 Python 爬蟲(28):自動化測試框架 Selenium 從入門到放棄(下)
小白學 Python 爬蟲(29):Selenium 獲取某大型電商網站商品資訊
小白學 Python 爬蟲(30):代理基礎
小白學 Python 爬蟲(31):自己構建一個簡單的代理池
小白學 Python 爬蟲(32):非同步請求庫 AIOHTTP 基礎入門
小白學 Python 爬蟲(33):爬蟲框架 Scrapy 入門基礎(一)
引言
在上一篇文章 小白學 Python 爬蟲(33):爬蟲框架 Scrapy 入門基礎(一) 中,我們簡單的使用了 Spider 抓取到了我們需要的資訊,我們簡單的將我所需要的資訊通過 print() 的方式列印了在了控制檯上。
在我們實際使用爬蟲的過程中,我們更多的是需要將資料儲存起來,並不是直接輸出至控制檯,本篇文章接著講我們如何將 Spider 抓取到的資訊儲存起來。
Item
Item 的主要目的是從非結構化源(通常是網頁)中提取結構化資料。
Scrapy Spider可以將提取的資料作為Python字典返回。Python字典雖然方便且熟悉,但缺乏結構:很容易在欄位名稱中輸入錯誤或返回不一致的資料,尤其是在具有許多蜘蛛的大型專案中。
為了定義常見的輸出資料格式, Scrapy 提供了 Item 該類。 Item 物件是用於收集抓取資料的簡單容器。它們提供了類似於字典的 API ,具有方便的語法來宣告其可用欄位。
接下來,我們來建立一個 Item 。
建立 Item 需要繼承 scrapy.Item 類,並且定義型別為 scrapy.Field 的欄位。
在前面一篇文章中,我們的目的想要獲取的欄位有 text 、 author 、 tags 。
那麼,我們定義的 Item 類如下,這裡直接修改 items.py 檔案:
import scrapy
class QuoteItem(scrapy.Item):
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()接下來就是我們如何要在 first_scrapy 專案中使用這個 Item 了,修改之前的 QuotesSpider 如下:
import scrapy
from first_scrapy.items import QuoteItem
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
item = QuoteItem()
item['text'] = quote.css('.text::text').extract_first()
item['author'] = quote.css('.author::text').extract_first()
item['tags'] = quote.css('.tags .tag::text').extract()
yield item接下來,我們可以通過最簡單的命令列將我們剛才獲取到的資料儲存為 json 檔案,命令如下:
scrapy crawl quotes -o quotes.json執行後可以看到在當前目錄下生成了一個名為 quotes.json 的檔案,具體內容如下:
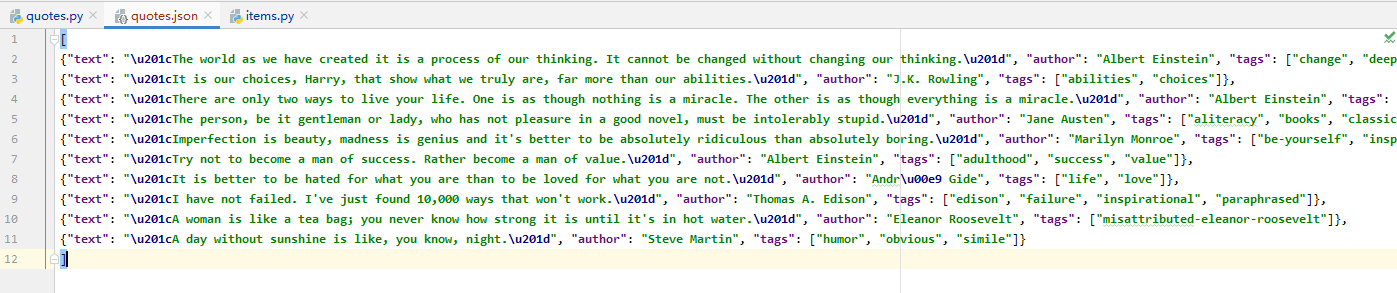
輸出格式還支援很多種,例如 csv、xml、pickle、marshal 等,常見的輸出語句如下:
scrapy crawl quotes -o quotes.csv
scrapy crawl quotes -o quotes.xml
scrapy crawl quotes -o quotes.pickle
scrapy crawl quotes -o quotes.marshal直到這裡,我們簡單的將獲取到的資料匯出成了 json 檔案,這就結束了麼?
當然沒有,前一篇文章我們只是簡單的獲取了當前頁面的內容,如果我們想抓取後續頁面的內容怎麼做呢?
當然,第一步我們需要先觀察後面一頁的連結:http://quotes.toscrape.com/page/2 。
接下來,我們需要構造一個訪問下一頁的請求,這時我們可以使用 scrapy.Request 。
這裡我們使用 Request() 先簡單的傳入兩個引數,實際上可以傳入的引數遠不止兩個,這個我們後面再聊。
- url:此請求的URL
- callback:它是回撥函式。當指定了該回調函式的請求完成之後,獲取到響應,引擎會將該響應作為引數傳遞給這個回撥函式。
那麼接下來我們要做的就是使用選擇器得到下一頁連結並生成請求,使用 scrapy.Request 訪問此連結,進行新一輪的資料抓取。
新增的程式碼如下:
next = response.css('.pager .next a::attr("href")').extract_first()
url = response.urljoin(next)
yield scrapy.Request(url=url, callback=self.parse)現在,改動後的 Spider 類整體程式碼如下:
# -*- coding: utf-8 -*-
import scrapy
from first_scrapy.items import QuoteItem
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
item = QuoteItem()
item['text'] = quote.css('.text::text').extract_first()
item['author'] = quote.css('.author::text').extract_first()
item['tags'] = quote.css('.tags .tag::text').extract()
yield item
next = response.css('.pager .next a::attr("href")').extract_first()
url = response.urljoin(next)
yield scrapy.Request(url=url, callback=self.parse)再次使用命令執行這個 Spider ,得到的結果如下(注意,如果前面生成過 json 檔案,記得刪除後再執行,否則會直接追加寫):
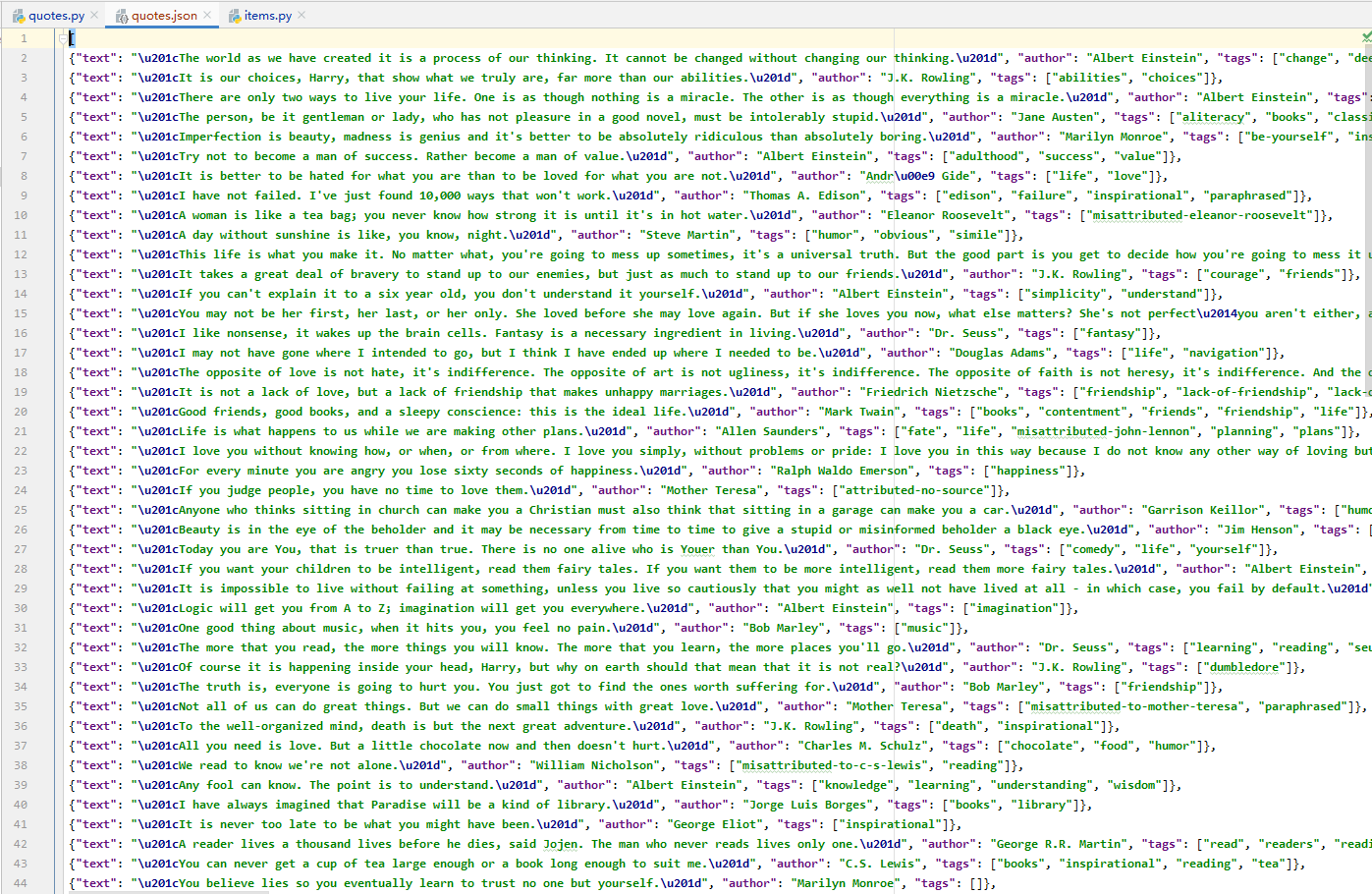
可以看到,資料增加了許多,說明我們抓取後續頁面的資料成功。
到這裡就結束了麼?怎麼可能,我們這裡只是簡單的將資料儲存在了 json 檔案中,並不方便我們的取用,這裡我們可以將資料儲存在我們所需要的資料庫中。
Item Pipeline
當我們想將資料儲存在資料庫中時,可以使用 Item Pipeline ,Item Pipeline 為專案管道。
這個管道的典型用途有:
- 清洗 HTML 資料
- 驗證爬取資料,檢查爬取欄位
- 查重並丟棄重複內容
- 將爬取結果儲存到資料庫
本示例選擇儲存的資料為 MongoDB ,接下來,我們會將前面查詢出來的資料儲存在 MongoDB 中。
emmmmmmmmmm,如果要問小編 MongoDB 怎麼安裝的話,簡單來講,直接使用 Docker 進行安裝,只需幾個簡單的命令即可:
docker pull mongo (拉取映象 預設最新版本)
docker images (檢視映象)
docker run -p 27017:27017 -td mongo (啟動映象)
docker ps (檢視啟動的映象)如果不出意外,以上這幾句話執行一下就可以了。連線工具可以使用 Navicat 。
這裡我們直接修改 pipelines.py 檔案,之前使用命令自動生成的內容可以全都刪掉,寫入以下內容:
# -*- coding: utf-8 -*-
from scrapy.exceptions import DropItem
class TextPipeline(object):
def process_item(self, item, spider):
if item['text']:
return item
else:
return DropItem('Missing Text')這裡我們實現了 process_item() 方法,其引數是 item 和 spider。
這裡簡單判斷了當前的 text 是否存在,如果不存在則直接丟擲 DropItem 異常,如果存在則直接返回 item 。
接下來,我們將處理後的 item 存入 MongoDB,定義另外一個 Pipeline。同樣在 pipelines.py 中,我們實現另一個類 MongoPipeline,內容如下所示:
import pymongo
class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def process_item(self, item, spider):
name = item.__class__.__name__
self.db[name].insert(dict(item))
return item
def close_spider(self, spider):
self.client.close()MongoPipeline 類實現了 API 定義的另外幾個方法。
- from_crawler,這是一個類方法,用 @classmethod 標識,是一種依賴注入的方式,方法的引數就是 crawler,通過 crawler 這個我們可以拿到全域性配置的每個配置資訊,在全域性配置 settings.py 中我們可以定義 MONGO_URI 和 MONGO_DB 來指定 MongoDB 連線需要的地址和資料庫名稱,拿到配置資訊之後返回類物件即可。所以這個方法的定義主要是用來獲取 settings.py 中的配置的。
- open_spider,當 Spider 被開啟時,這個方法被呼叫。在這裡主要進行了一些初始化操作。
- close_spider,當 Spider 被關閉時,這個方法會呼叫,在這裡將資料庫連線關閉。
最主要的 process_item() 方法則執行了資料插入操作。
定義好 TextPipeline 和 MongoPipeline 這兩個類後,我們需要在 settings.py 中使用它們。MongoDB 的連線資訊還需要定義。
在 settings.py 中加入如下內容:
ITEM_PIPELINES = {
'first_scrapy.pipelines.TextPipeline': 300,
'first_scrapy.pipelines.MongoPipeline': 400,
}
MONGO_URI='localhost'
MONGO_DB='first_scrapy'再次執行爬取命令:
scrapy crawl quotes執行結果如下:
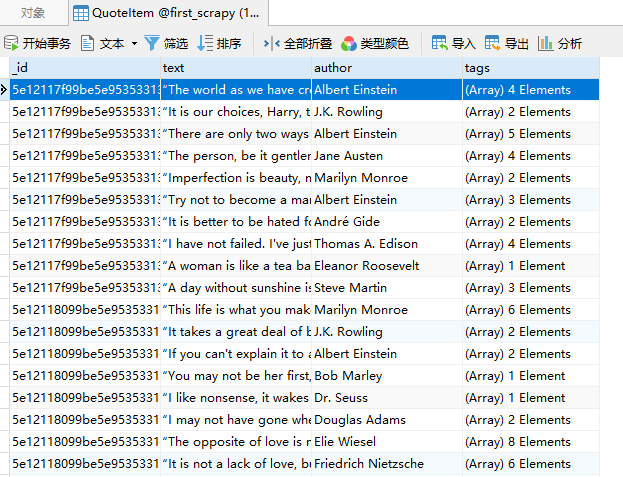
可以看到,在 MongoDB 中建立了一個 QuoteItem 的表,表中儲存了我們剛才抓取到的資料。
示例程式碼
本系列的所有程式碼小編都會放在程式碼管理倉庫 Github 和 Gitee 上,方便大家取用。
示例程式碼-Github
示例程式碼-Gitee
參考
https://docs.scrapy.org/en/latest/topics/request-response.html
https://docs.scrapy.org/en/latest/topics/items.html
https://cuiqingcai.com/8337.h